Native LLM Evaluation Workflow with Multi-Provider Integration Generative AI Lab 7.2.0
Release date: 06-23-2025
Generative AI Lab 7.2.0 introduces native LLM evaluation capabilities, enabling complete end-to-end workflows for importing prompts, generating responses via external providers (OpenAI, Azure OpenAI, Amazon SageMaker), and collecting human feedback within a unified interface. The new LLM Evaluation and LLM Evaluation Comparison project types support both single-model assessment and side-by-side comparative analysis, with dedicated analytics dashboards providing statistical insights and visual summaries of evaluation results.
New annotation capabilities include support for CPT code lookup for medical and clinical text processing, enabling direct mapping of labeled entities to standardized terminology systems.
The release also delivers performance improvements through background import processing that reduces large dataset import times by 50% (from 20 minutes to under 10 minutes for 5000+ files) using dedicated 2-CPU, 5GB memory clusters.
Furthermore, annotation workflows now benefit from streamlined NER interfaces that eliminate visual clutter while preserving complete data integrity in JSON exports. Also, the system now enforces strict resource compatibility validation during project configuration, preventing misconfigurations between models, rules, and prompts.
Additionally, 20+ bug fixes address critical issues, including sample task import failures, PDF annotation stability, and annotator access permissions.
Whether you’re tuning model performance, running human-in-the-loop evaluations, or scaling annotation tasks, Generative AI Lab 7.2.0 provides the tools to do it faster, smarter, and more accurately.
New Features
LLM Evaluation Project Types with Multi-Provider Integration
Two new project types enable systematic evaluation of large language model outputs:
Two new project types enable the systematic evaluation of large language model outputs: • LLM Evaluation: Assess single model responses against custom criteria • LLM Evaluation Comparison: Side-by-side evaluation of responses from two different models
Supported Providers:
- OpenAI
- Azure OpenAI
- Amazon SageMaker
Service Configuration Process
- Navigate to Settings → System Settings → Integration.
- Click Add and enter your provider credentials.
- Save the configuration.

LLM Evaluation Project Creation
- Navigate to the Projects page and click New.
- After filling in the project details and assigning to the project team, proceed to the Configuration page.
- Under the Text tab on step 1 - Content Type, select LLM Evaluation task and click on Next.
- On the Select LLM Providers page, you can either:
- Click Add button to create an external provider specific to the project (this provider will only be used within this project), or
- Click Go to External Service Page to be redirected to Integration page, associate the project with one of the supported external LLM providers, and return to Project → Configuration → Select LLM Response Provider,
- Choose the provider you want to use, save the configuration and click on Next.
- Customize labels and choices as needed in the Customize Labels section, and save the configuration.
For LLM Evaluation Comparison projects, follow the same steps, but associate the project with two different external providers and select both on the LLM Response Provider page.
Sample Import Format for LLM Evaluation
To start working with prompts:
1.Go to the Tasks page and click Import.
2.Upload your prompts in either .json or .zip format. Following is a Sample JSON Format to import prompt:
Sample JSON for LLM Evaluation Project
{
"data": {
"prompt": "Give me a diet plan for a diabetic 35 year old with reference links",
"response1": "",
"title": "DietPlan"
}
}
Sample JSON for LLM Evaluation Comparison Project
{
"data": {
"prompt": "Give me a diet plan for a diabetic 35 year old with reference links",
"response1": "",
"response2": "",
"title": "DietPlan"
}
}
3.Once the prompts are imported as tasks, click the Generate Response button to generate LLM responses.
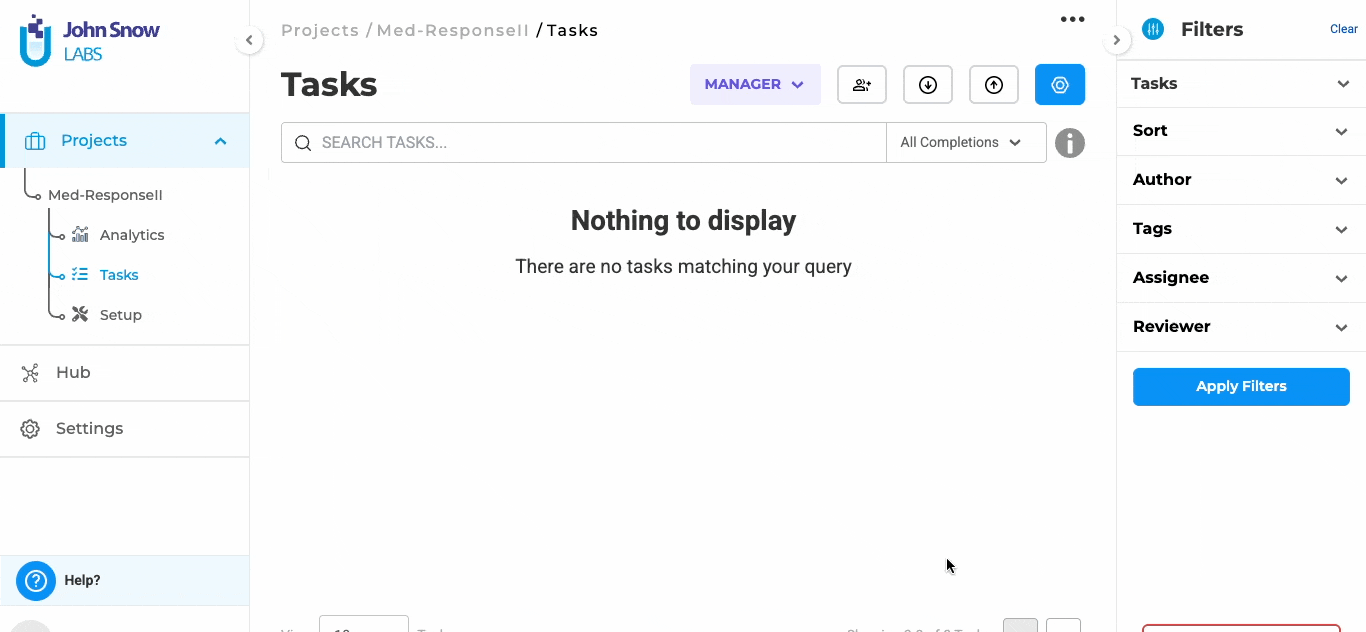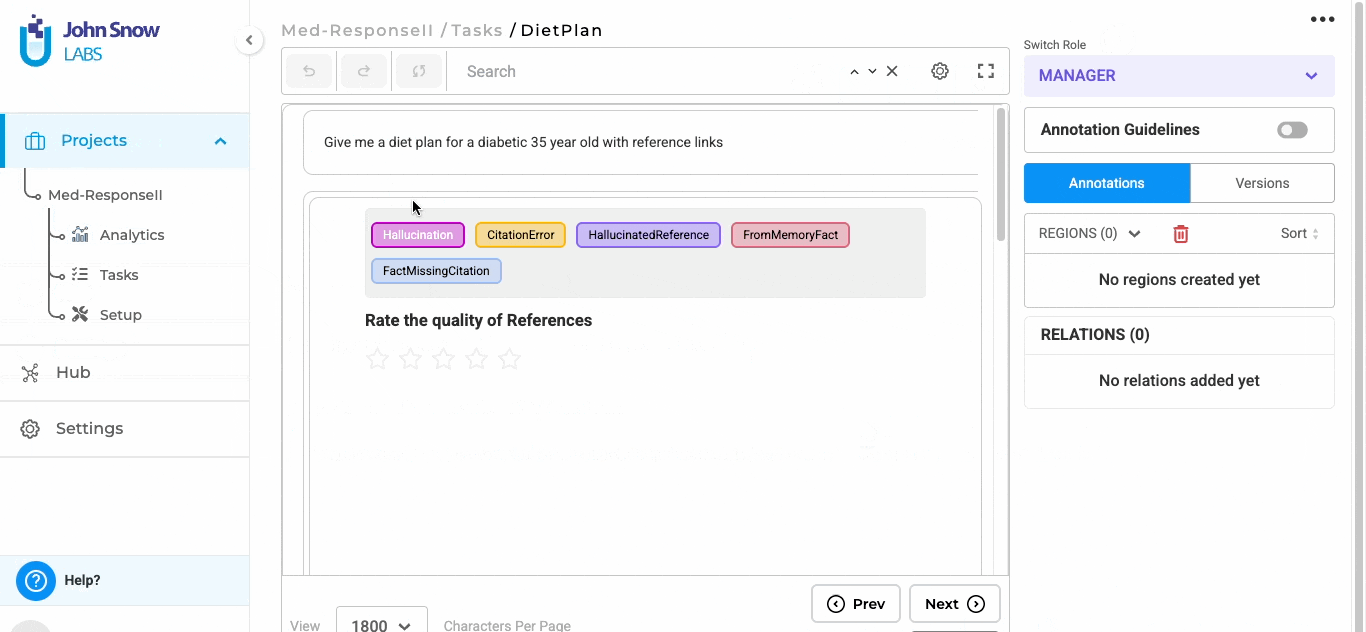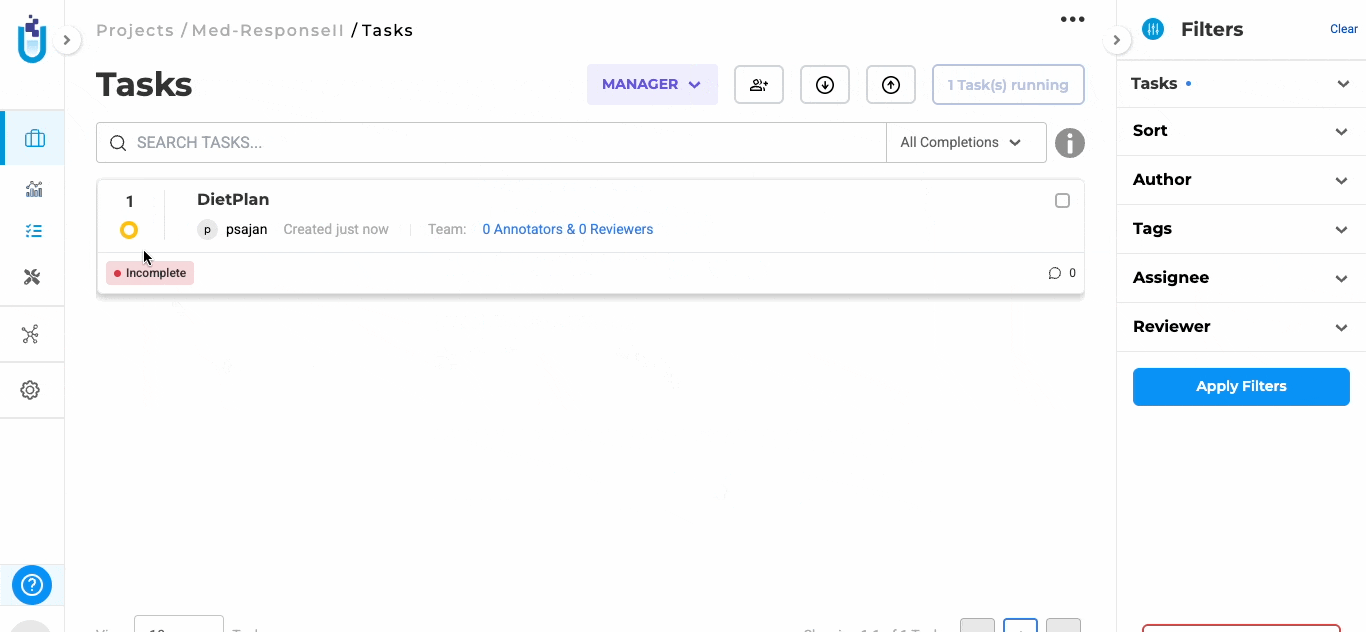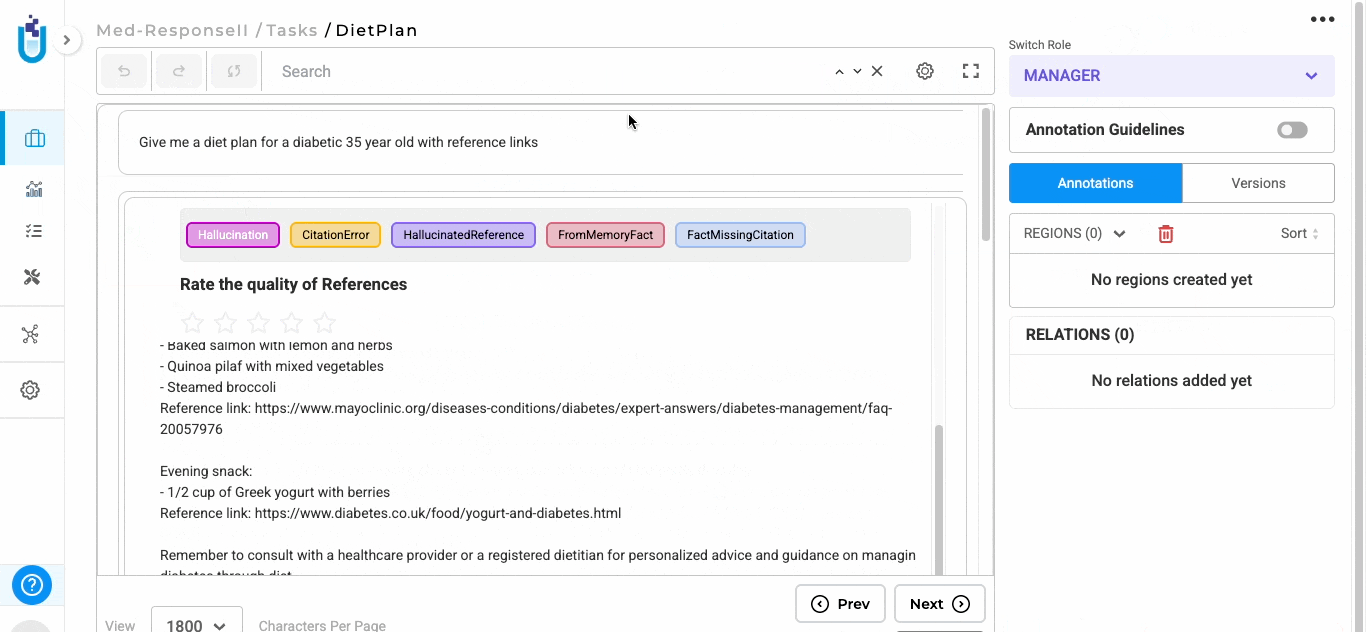
After responses are generated, users can begin evaluating them directly within the task interface.
Sample Import Format for LLM Evaluation with Response
Users can also import prompts and LLM-generated responses using a structured JSON format. This feature supports both LLM Evaluation and LLM Evaluation Comparison project types.
Below are example JSON formats:
- LLM Evaluation: Includes a prompt and one LLM response mapped to a provider.
- LLM Evaluation Comparison: Supports multiple LLM responses to the same prompt, allowing side-by-side evaluation.
Sample JSON for LLM Evaluation Project with Response
{
"data": {
"prompt": "Give me a diet plan for a diabetic 35 year old with reference links",
"response1": "Prompt Respons1 Here",
"llm_details": [
{ "synthetic_tasks_service_provider_id": 1, "response_key": "response1" }
],
"title": "DietPlan"
}
}
Sample JSON for LLM Evaluation Comparision Project with Response
{
"data": {
"prompt": "Give me a diet plan for a diabetic 35 year old with reference links",
"response1": "Prompt Respons1 Here",
"response2": "Prompt Respons2 Here",
"llm_details": [
{ "synthetic_tasks_service_provider_id": 1, "response_key": "response1" },
{ "synthetic_tasks_service_provider_id": 2, "response_key": "response2" }
],
"title": "DietPlan"
}
}
Analytics Dashboard for LLM Evaluation Projects
A dedicated analytics tab provides quantitative insights for LLM evaluation projects:
- Bar graphs for each evaluation label and choice option
- Statistical summaries derived from submitted completions
- Multi-annotator scenarios prioritize submissions from highest-priority users
- Analytics calculations exclude draft completions (submitted tasks only)
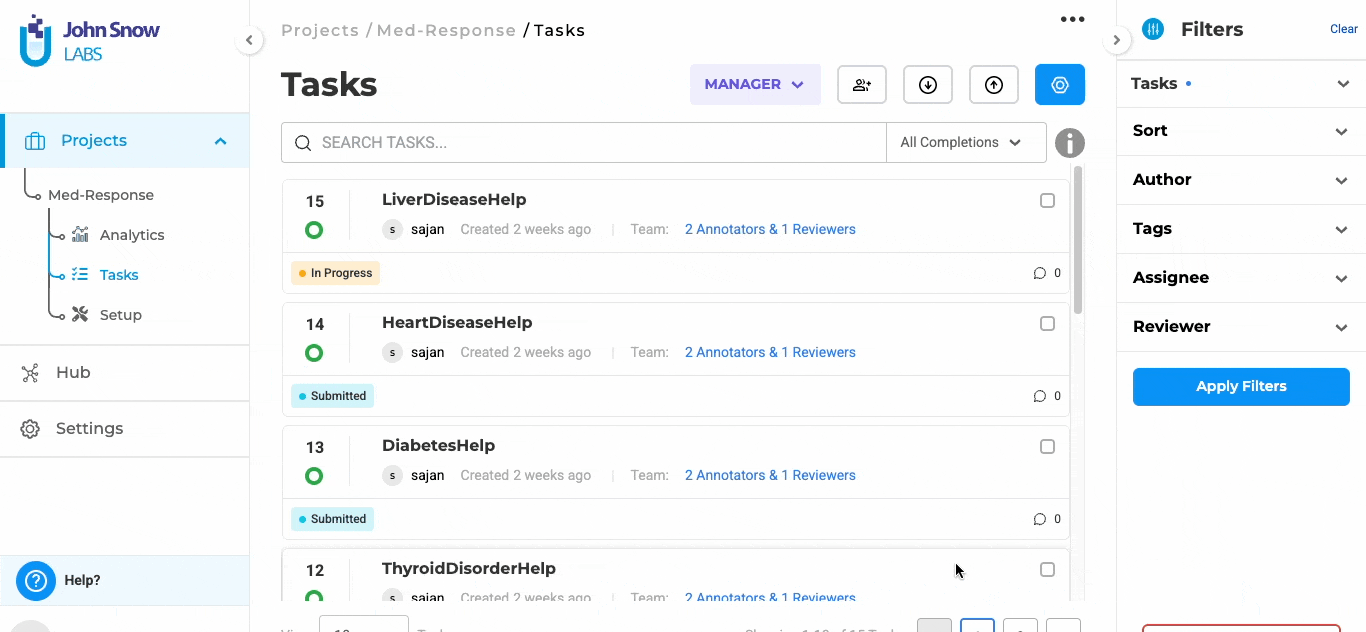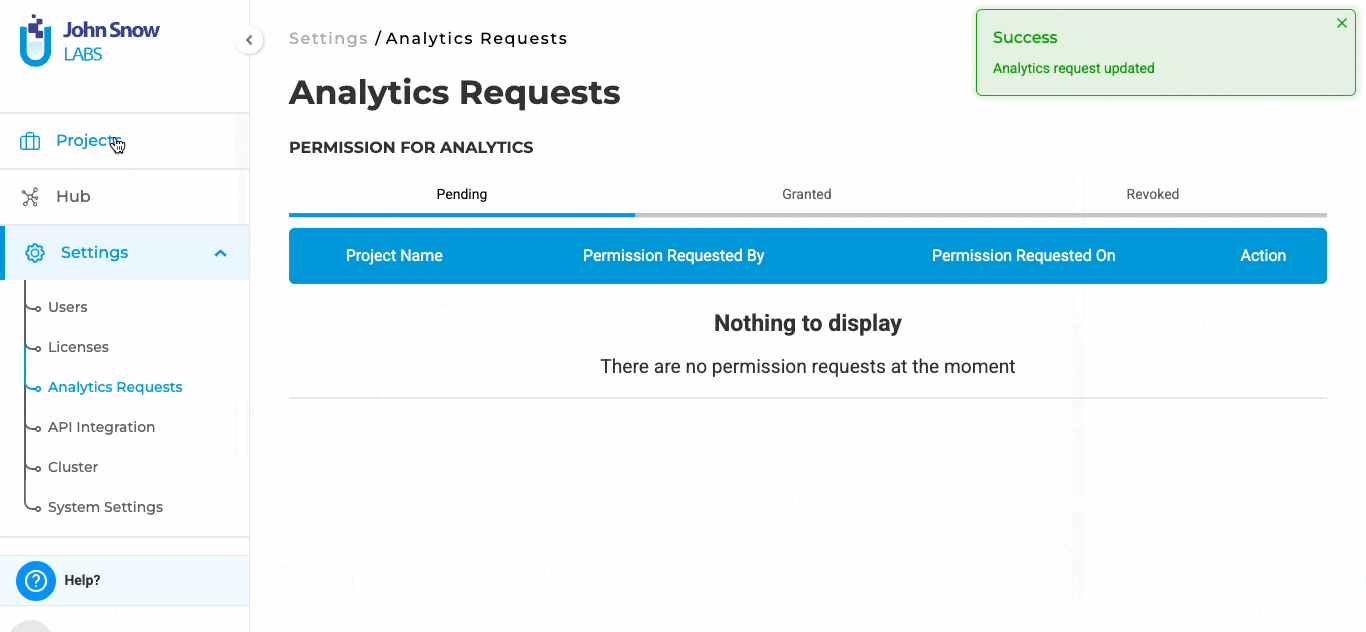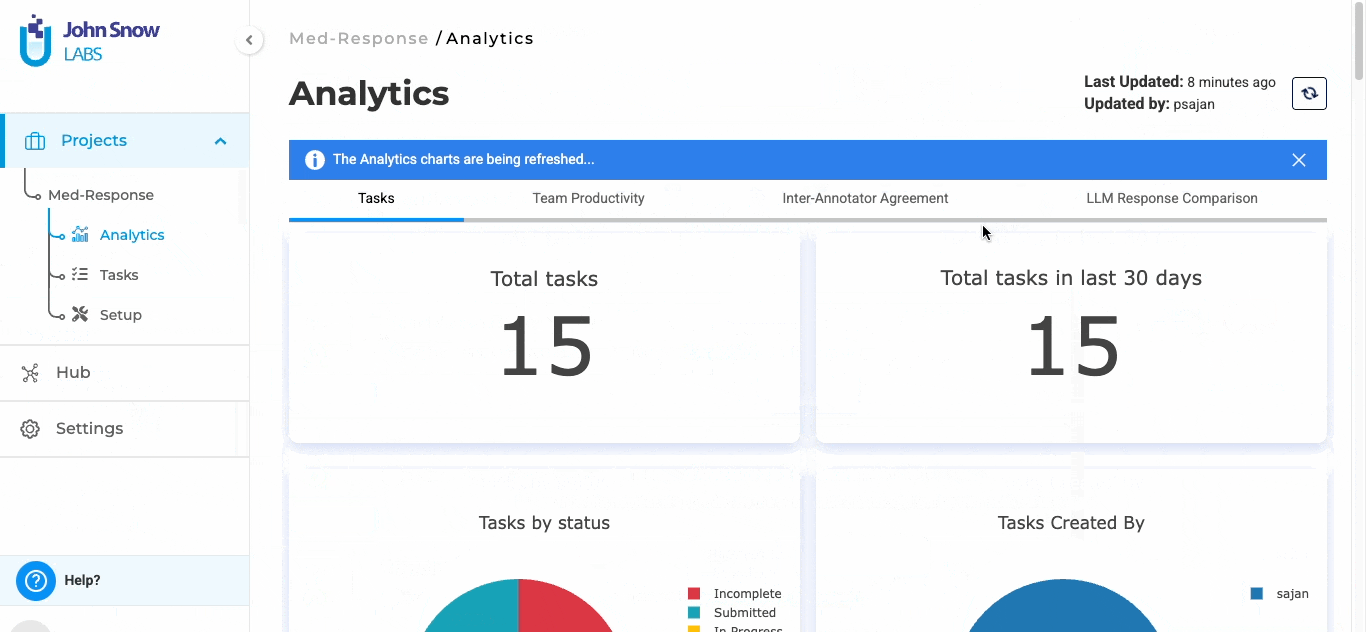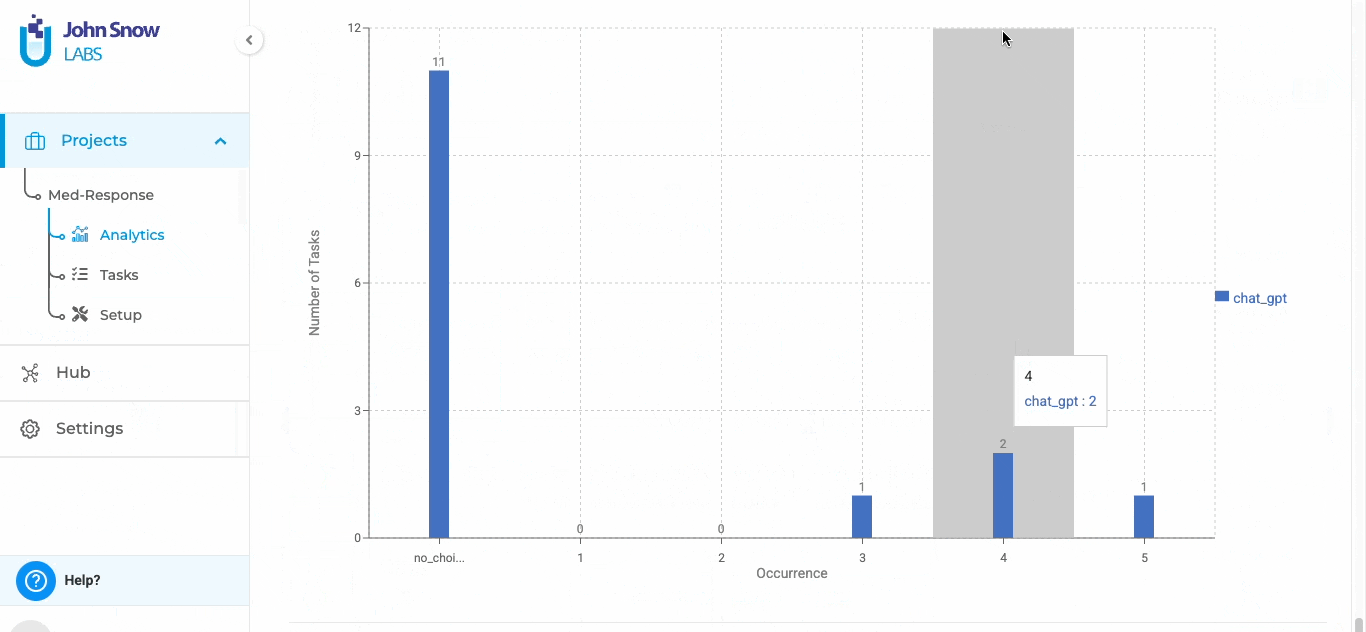
The general workflow for these projects aligns with the existing annotation flow in Generative AI Lab. The key difference lies in the integration with external LLM providers and the ability to generate model responses directly within the application for evaluation.
These new project types provide teams with a structured approach to assess and compare LLM outputs efficiently, whether for performance tuning, QA validation, or human-in-the-loop benchmarking.
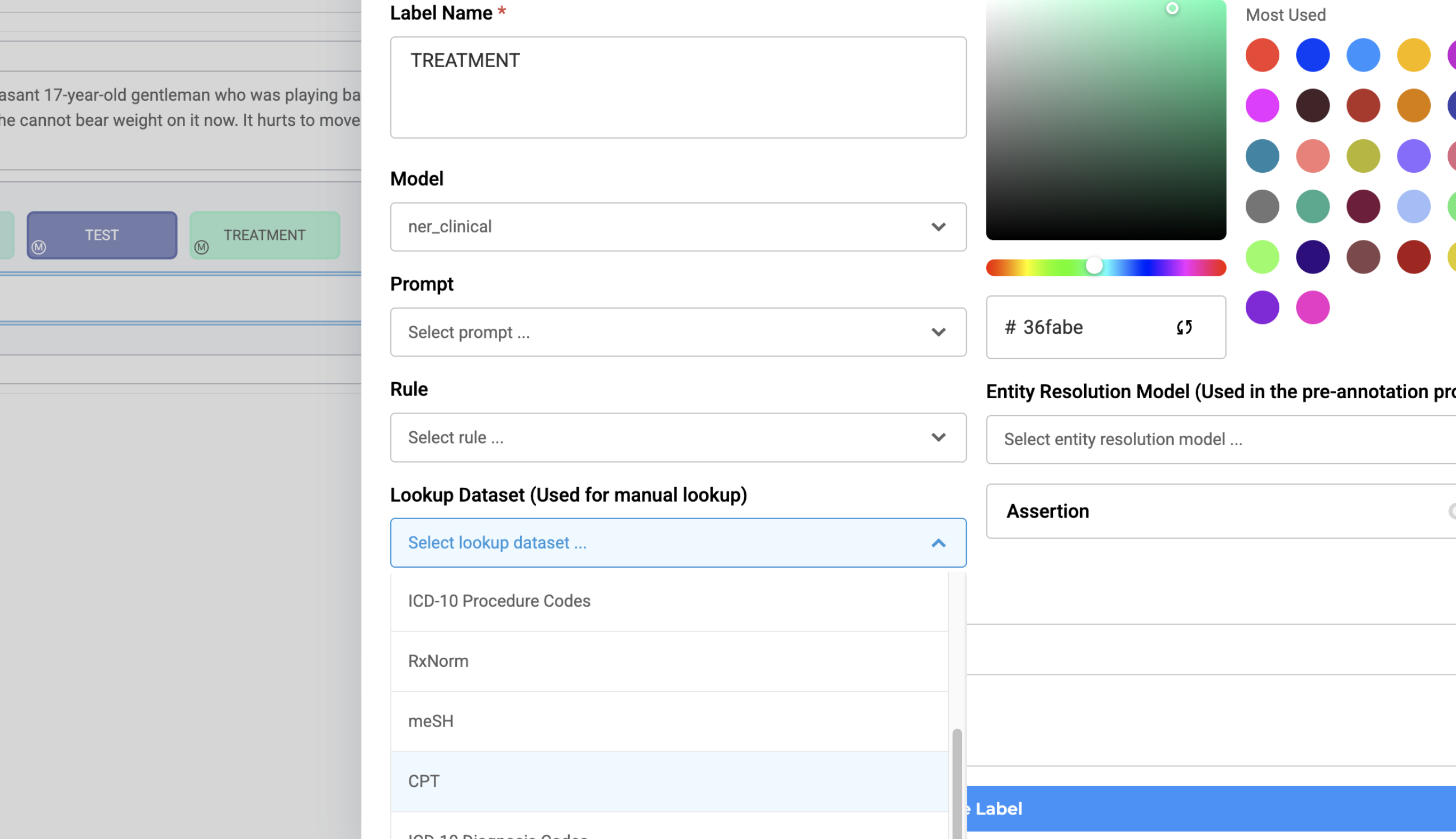
CPT Lookup Dataset Integration for Annotation Extraction
NER projects now support CPT codes lookup for standardized entity mapping. Setting up lookup datasets is simple and can be done via the Customize Labels page in the project configuration wizard.
Use Cases:
- Map clinical text to CPT codes
- Link entities to normalized terminology systems
- Enhance downstream processing with standardized metadata
Configuration:
- Navigate to Customize Labels during project setup
- Click on the label you want to enrich
- Select your desired Lookup Dataset from the dropdown list
- Go to the Task Page to start annotating — lookup information can now be attached to the labeled texts
Improvements
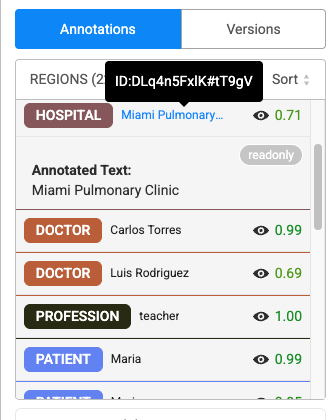
Redesigned Annotation Interface for NER Projects
The annotation widget interface has been streamlined for Text and Visual NER project types. This update focuses on enhancing clarity, reducing visual clutter, and improving overall usability, without altering the core workflow. All previously available data remains intact in the exported JSON, even if not shown in the UI.
Enhancements in Name Entity Recognition and Visual NER Labeling Project Types
- Removed redundant or non-essential data from the annotation view.
- Grouped the Meta section visually to distinguish it clearly and associate the delete button specifically with metadata entries.
- Default confidence scores display (1.00) with green highlighting. Hover functionality on labeled text reveals text ID.
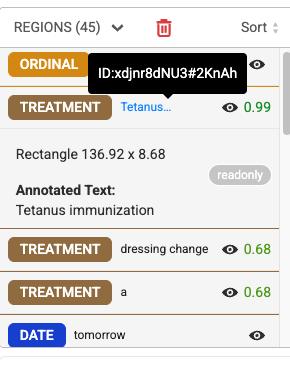
Visual NER Specific Updates
- X-position data relocated to detailed section
- Recognized text is now placed at the top of the widget for improved readability.
- Maintained data integrity in JSON exports despite UI simplification
These enhancements contribute to a cleaner, more intuitive user interface, helping users focus on relevant information during annotation without losing access to critical data in exports.
Optimized Import Processing for Large Datasets
The background processing architecture now handles large-scale imports without UI disruption through intelligent format detection and dynamic resource allocation. When users upload tasks as a ZIP file or through a cloud source, Generative AI Lab automatically detects the format and uses the import server to handle the data in the background — ensuring smooth and efficient processing, even for large volumes.
For smaller, individual files — whether selected manually or added via drag-and-drop — imports are handled directly without background processing, allowing for quick and immediate task creation.
Note: Background import is applied only for ZIP and cloud-based imports.
Automatic Processing Mode Selection:
- ZIP files and cloud-based imports: Automatically routed to background processing via dedicated import server
- Individual files (manual selection or drag-and-drop): Processed directly for immediate task creation
- The system dynamically determines optimal processing path based on import source and volume
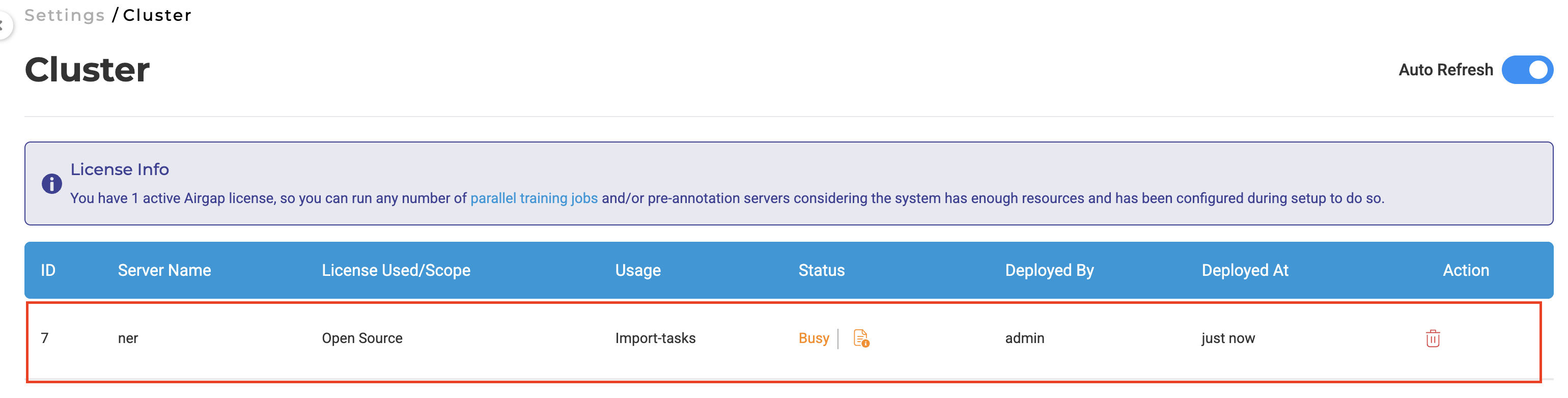
Technical Architecture:
- Dedicated import cluster with auto-provisioning: 2 CPUs, 5GB memory (non-configurable)
- Cluster spins up automatically during ZIP and cloud imports
- Automatic deallocation upon completion to optimize resource utilization
- Sequential file processing methodology reduces system load and improves reliability
- Import status is tracked and visible on the Import page, allowing users to easily monitor progress and confirm successful uploads.
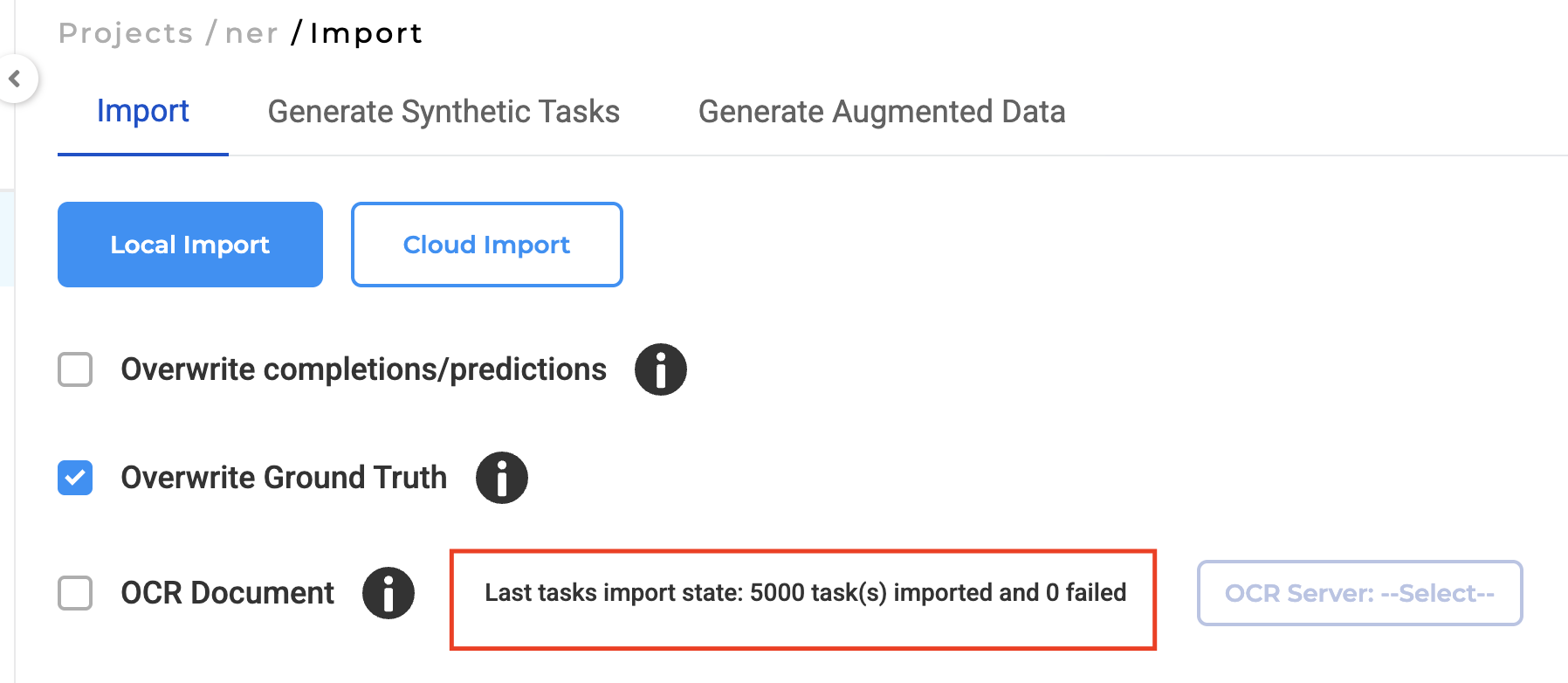
Performance Improvements:
- Large dataset imports (5000+ files): Previously 20+ minutes, now less than 10 minutes
- Elimination of UI freezing during bulk operations
- Improved system stability under high-volume import loads
Note: Import server created during task import is counted as an active server.
Refined Resource Compatibility Validation
In previous versions, while validation mechanisms were in place to prevent users from combining incompatible model types, rules, and prompts, the application still allowed access to unsupported resources. This occasionally led to confusion, as the Reuse Resource page displayed models or components not applicable to the selected project type. With version 7.2.0, the project configuration enforces strict compatibility between models, rules, and prompts:
- Reuse Resource page hidden for unsupported project types
- Configuration interface displays only compatible resources for selected project type
These updates ensure a smoother project setup experience and prevent misconfigurations by guiding users more effectively through supported options.
Bug Fixes
Sample Task Import **Resolution**
- Issue: Sample task import failures in HTML projects with NER labels
- Resolution: Sample tasks now import successfully into HTML projects containing NER labels
PDF Annotation Stability
- Issue: PDF page refreshes when adding lookup codes in Side-by-Side projects
- Resolution: PDF viewport maintains position during lookup data entry
Lang Test Model Versioning
- Issue: Test execution errors for v1-generated test cases after model retraining to v2
- Resolution: Previously generated test cases execute successfully across model versions
Relation Tag Display Logic
- Issue: Relations with “O” tag inappropriately displayed in UI
- Resolution: “O” tagged relations properly excluded from UI display
License Banner Event Handling
- Issue: license_banner_dismiss event triggered on page refresh
- Resolution: Event triggers only on explicit user dismissal
Task Selection Interface Stability
- Issue: Assignee button resizing and task-per-page selection failures when all tasks selected
- Resolution: UI elements maintain consistent sizing during bulk operations
Demo Project Access Control
- Issue: Admin users automatically added to Demo De-identification projects
- Resolution: Admin users no longer added by default to demo projects
Annotator Access Permissions
- Issue: “User doesn’t have permission” errors for assigned annotators in de-identification projects
- Resolution: Annotators with task assignments can access task pages without permission errors
Versions
- 8.2.1
- 8.2.0
- 8.1.3
- 8.1.2
- 8.1.1
- 8.1.0
- 8.0.1
- 8.0.0
- 7.8.2
- 7.8.1
- 7.8
- 7.7
- 7.6.0
- 7.5.1
- 7.5.0
- 7.4.0
- 7.3.1
- 7.3.0
- 7.2.2
- 7.2.1
- 7.2.0
- 7.1.0
- 7.0.1
- 7.0.0
- 6.11.3
- 6.11.2
- 6.11.1
- 6.11.0
- 6.10.1
- 6.10.0
- 6.9.1
- 6.9.0
- 6.8.1
- 6.8.0
- 6.7.2
- 6.7.0
- 6.6.0
- 6.5.1
- 6.5.0
- 6.4.1
- 6.4.0
- 6.3.2
- 6.3.0
- 6.2.1
- 6.2.0
- 6.1.2
- 6.1.1
- 6.1.0
- 6.0.2
- 6.0.0
- 5.9.3
- 5.9.2
- 5.9.1
- 5.9.0
- 5.8.1
- 5.8.0
- 5.7.1
- 5.7.0
- 5.6.2
- 5.6.1
- 5.6.0
- 5.5.3
- 5.5.2
- 5.5.1
- 5.5.0
- 5.4.1
- 5.3.2
- 5.2.3
- 5.2.2
- 5.1.1
- 5.1.0