5.4.1
Release date: 04-09-2023
NLP Lab 5.4 – Empowering Model Sharing, Enhanced Annotation, and Azure Blob Backups
We are thrilled to release NLP Lab 5.4 which brings a host of exciting enhancements to further empower your NLP journey. In this release, we’ve focused on simplifying model sharing, making advanced features more accessible with FREE access to Zero-shot NER prompting, streamlining the annotation process with completions and predictions merging, and introducing Azure Blob backup integration.
Publish Models Directly into Models HUB
We’re excited to introduce a streamlined way to publish NLP models to the NLP Models HUB directly from NLP Lab. Known for its user-friendly interface for annotating, submitting completions, and training Spark NLP Models, NLP Lab now simplifies the model-sharing process even further.
GitHub Integration for Easy Model Sharing
To use this feature, you’ll need to link your GitHub account with NLP Lab. Here’s a quick guide:
- Access Integrations Settings: On your NLP Lab instance, navigate to Settings page and then to Integrations Tab.
- Connect to GitHub: The GitHub Integration option is readily available. Simply click the “Connect” button to proceed.
- Authenticate with GitHub: You will be directed to the GitHub website for authentication. Once authenticated, a success message in NLP Lab will confirm the linkage.
Now, you are all set to publish your models to the NLP Models HUB!
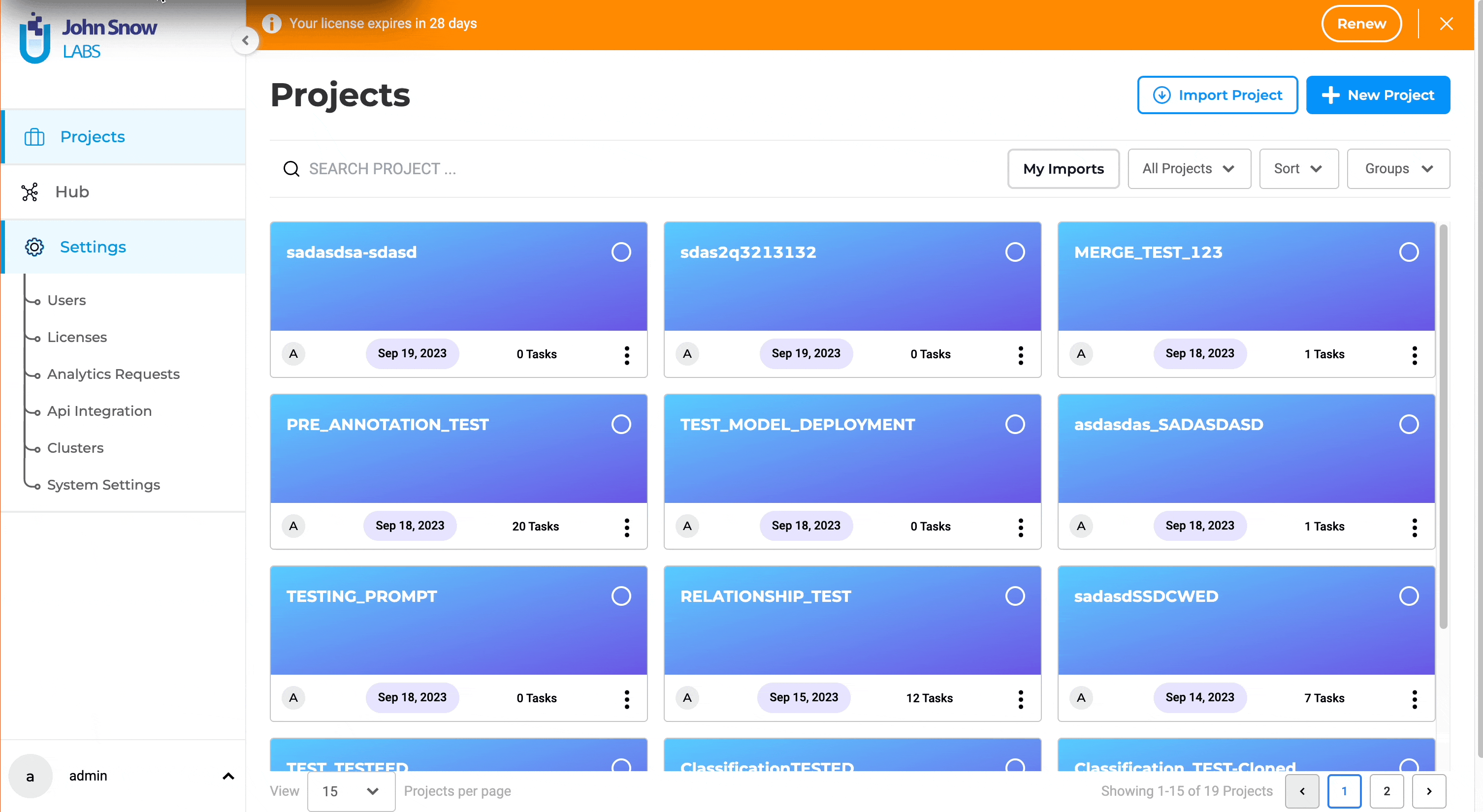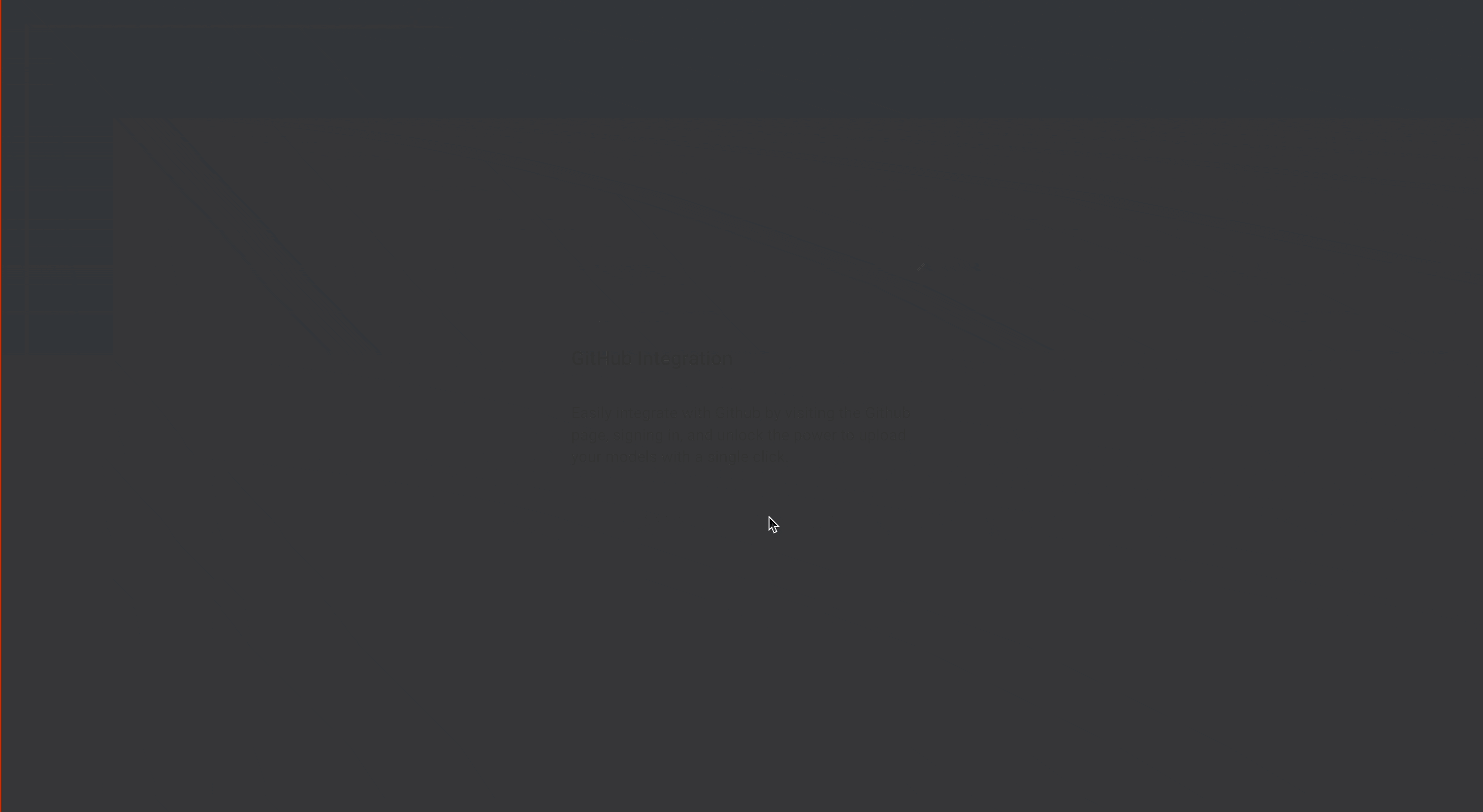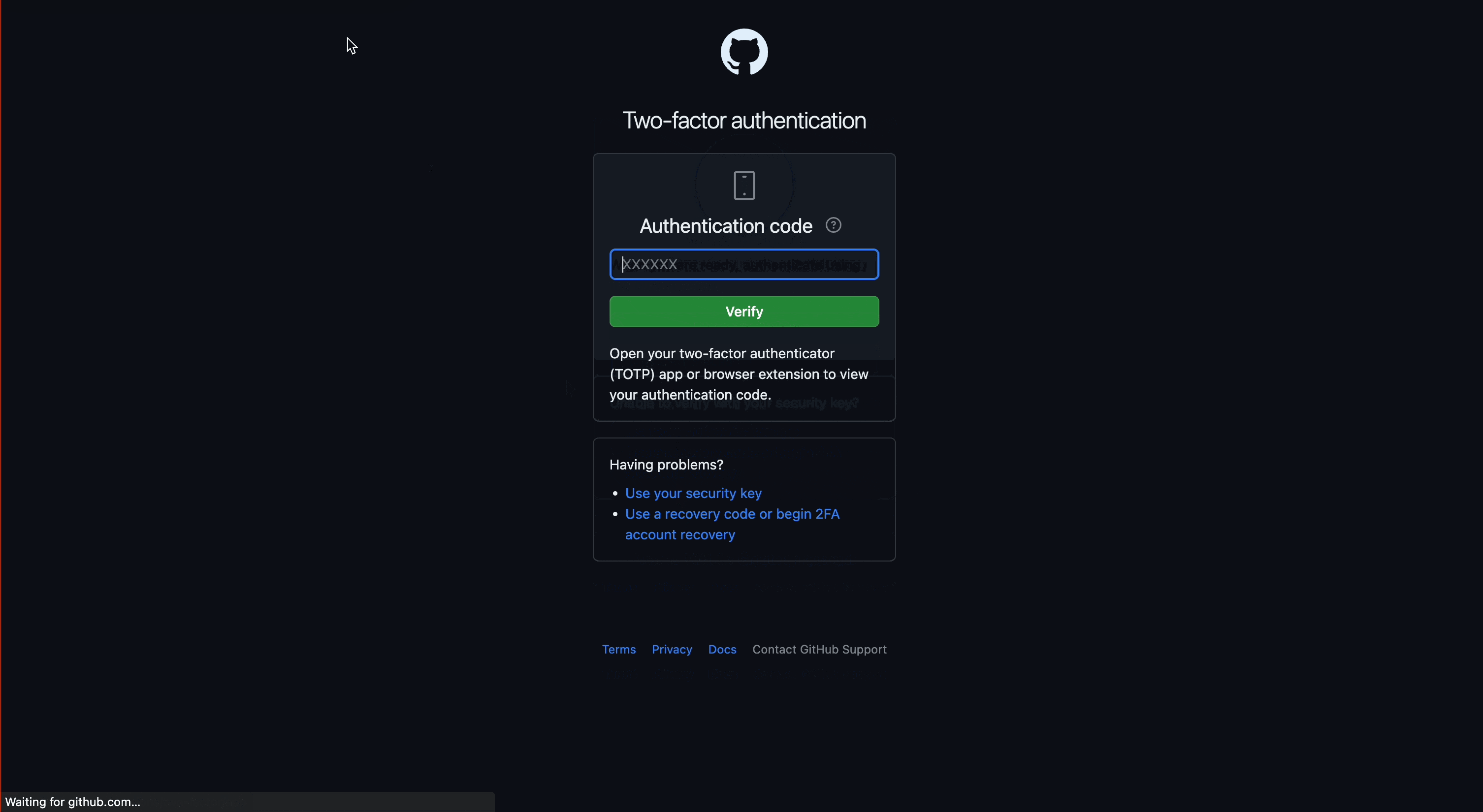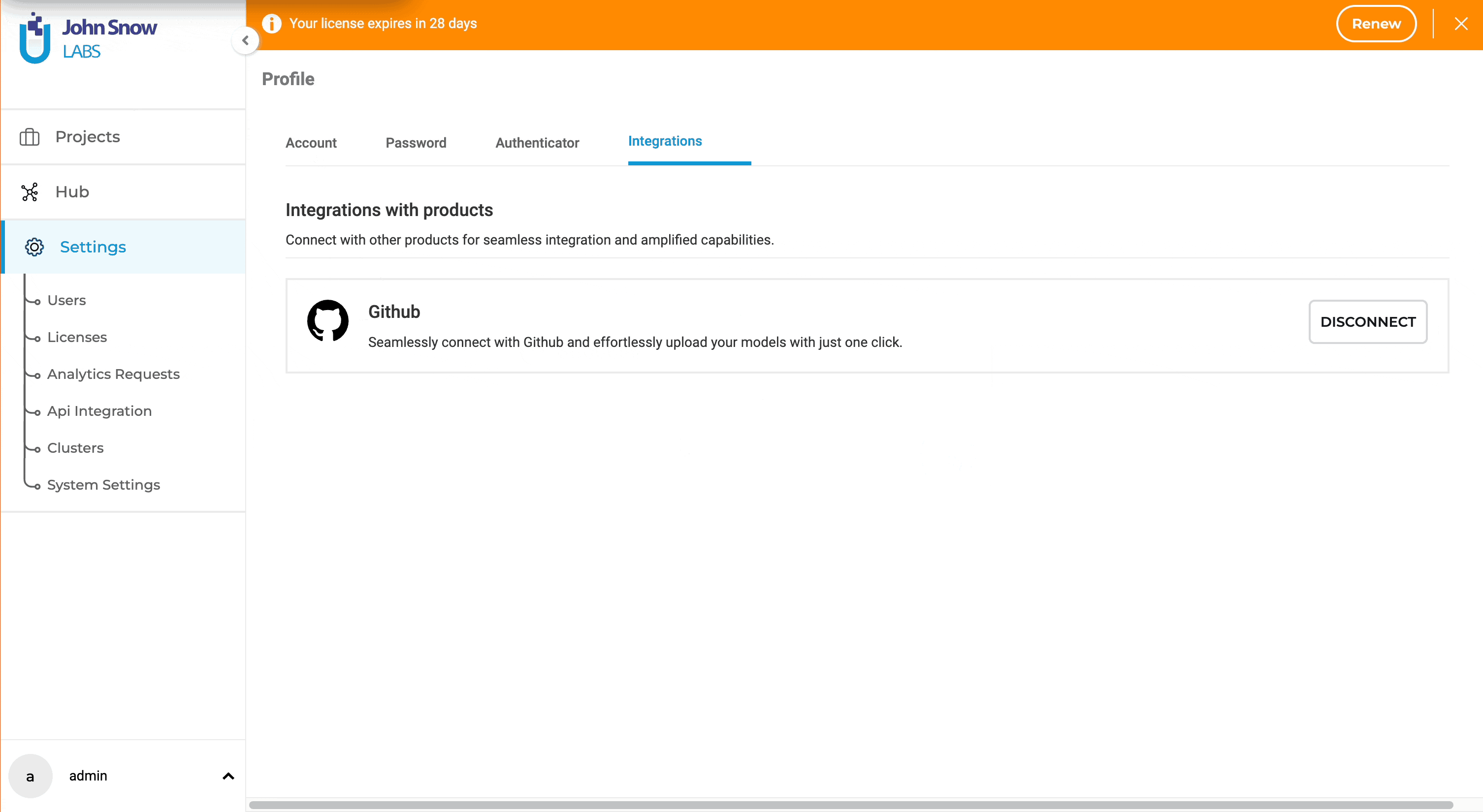
Steps to publish your NLP Lab trained model to NLP Models HUB
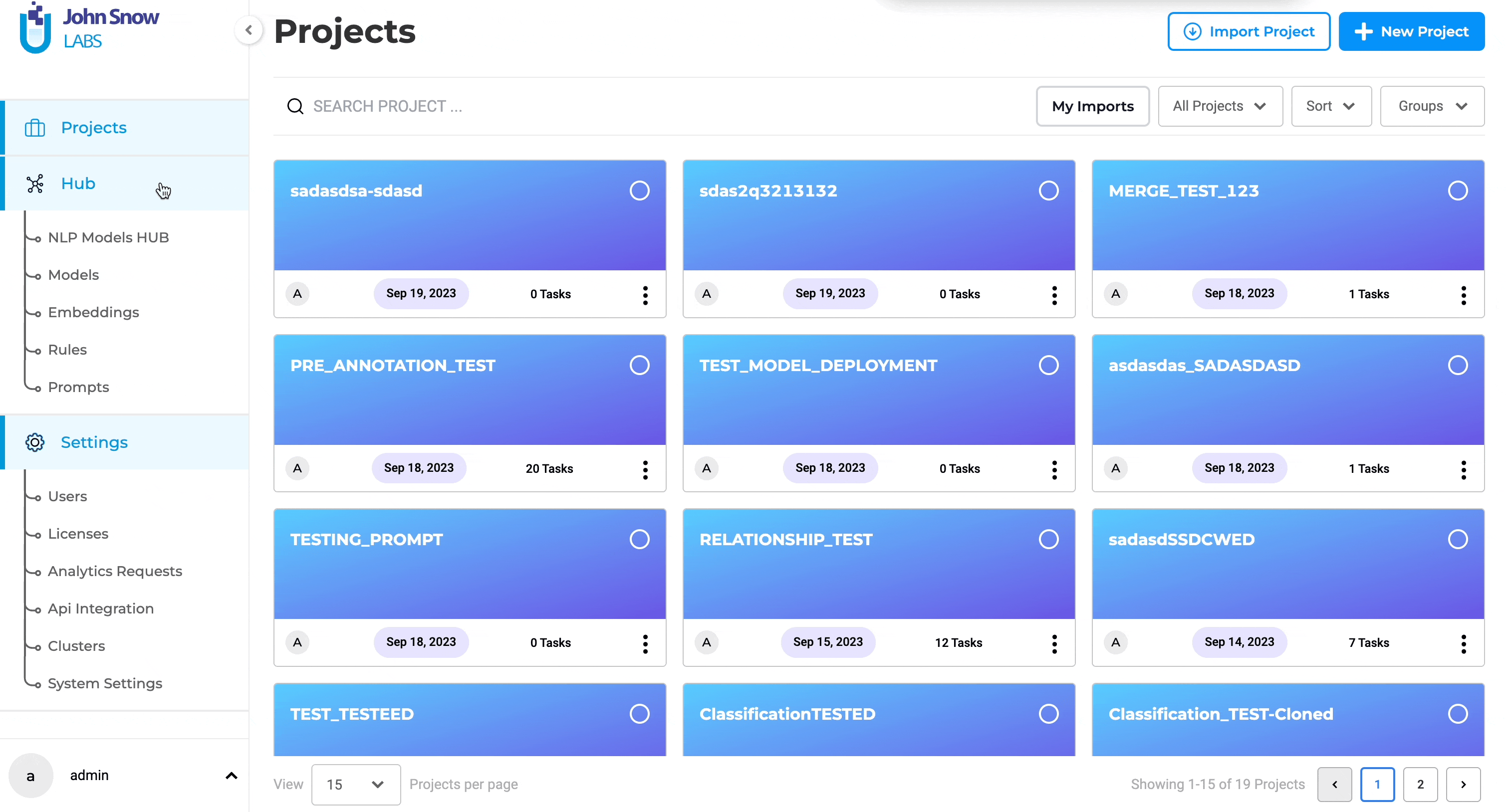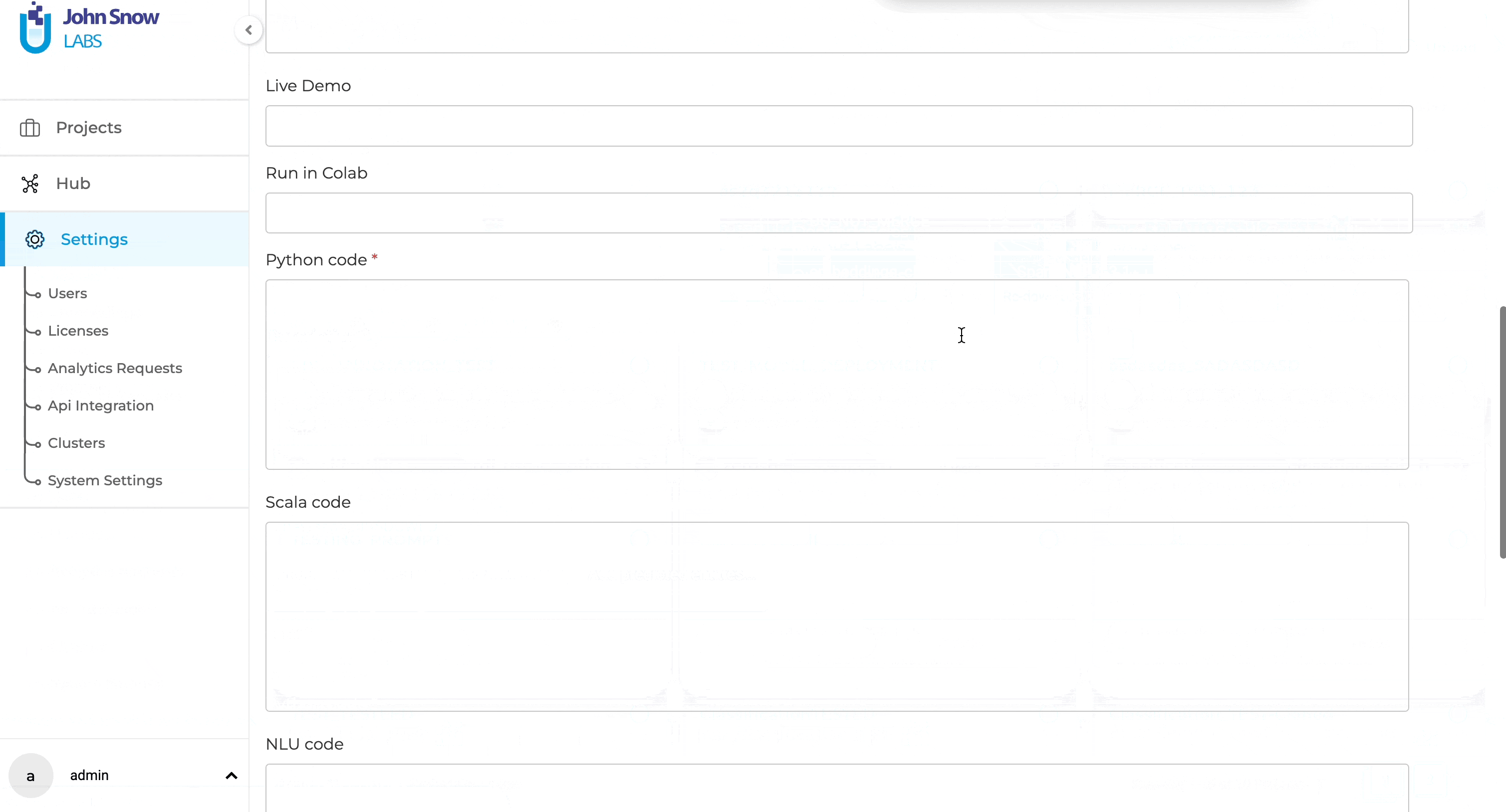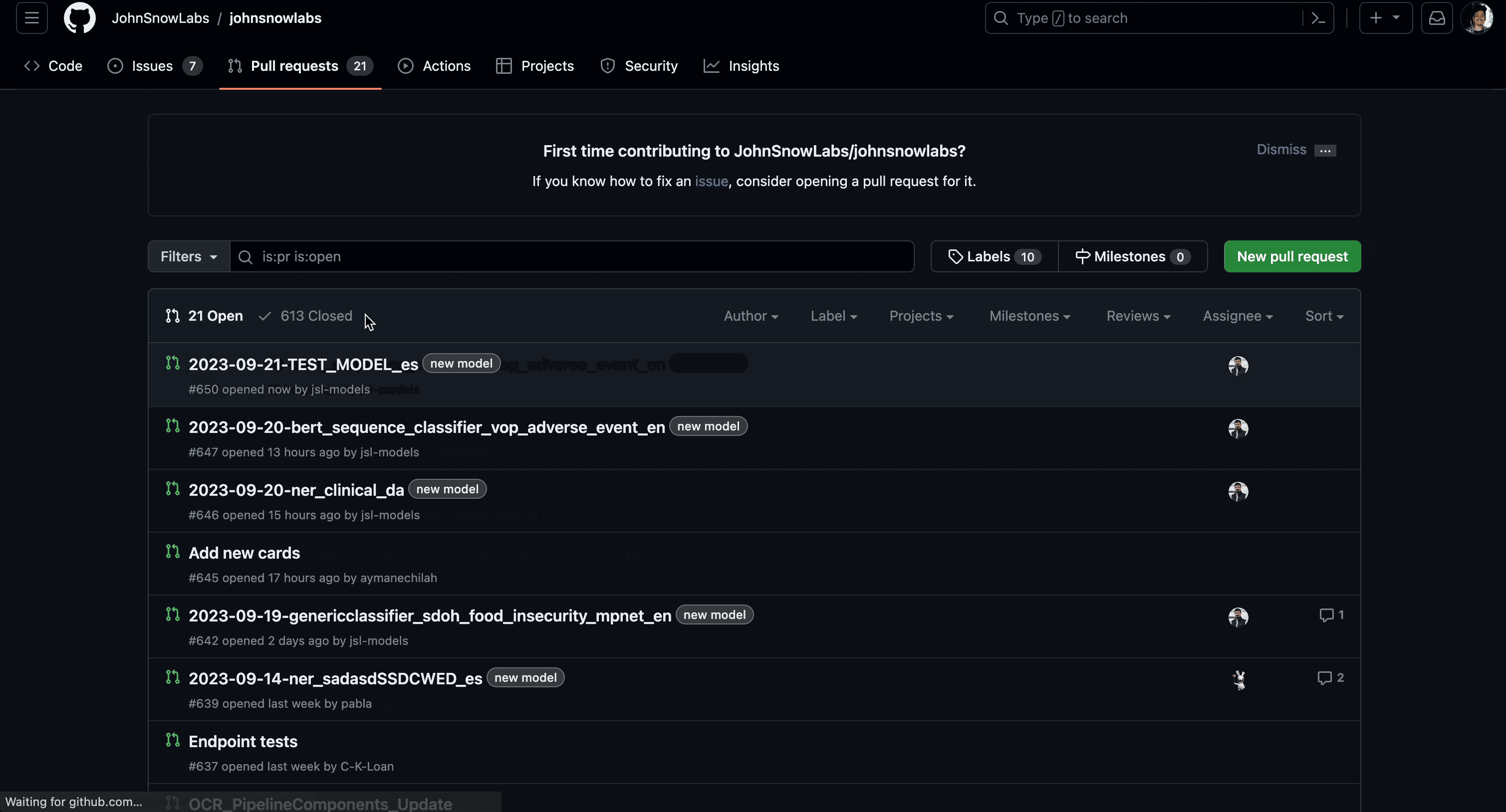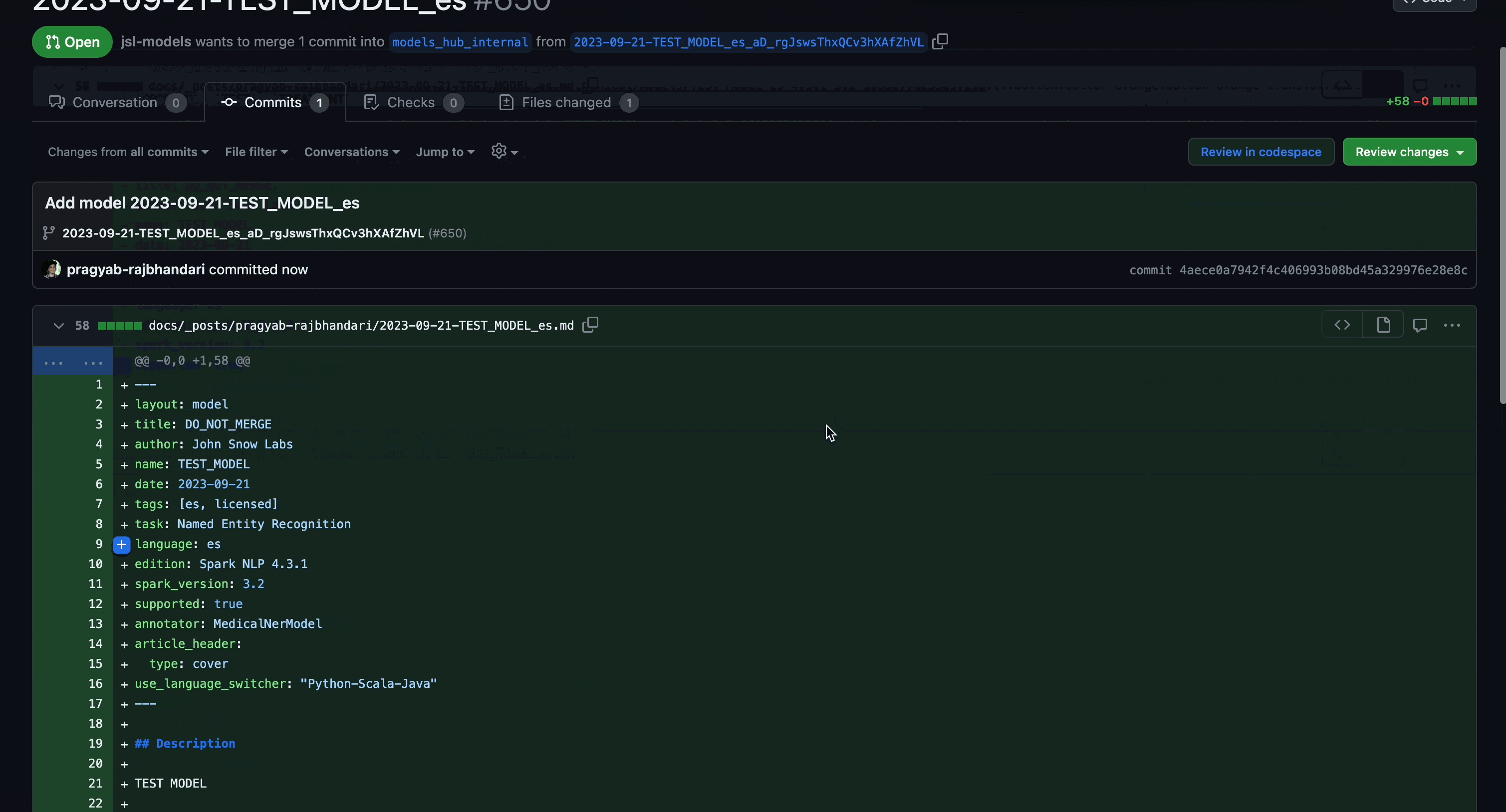
If you are an admin user with access to the “Hub” menu, you will find all downloaded or trained models on your “Models” Page. Here’s how to publish them on the NLP Models Hub:
- Initiate Publishing: Locate the model you wish to publish and click the three-dot menu next to it. Choose the “Publish” option, which will direct you to a pre-filled form.
- Review and Confirm: Complete any remaining fields and review the model information. Click “Submit” to finalize.
- GitHub Pull-Request: A Pull-Request containing your model details will be generated on your behalf.
- For Open-Source Models, the Pull Request will be sent to the Repository: “JohnSnowLabs/spark-nlp”.
- For Licensed Models, the Pull Request will be sent to the Repository: “JohnSnowLabs/johnsnowlabs”.
- Final Steps: Your Pull Request will be reviewed by the NLP Models HUB team and, upon approval, will be published to NLP Models HUB.
This new feature eliminates the need to manually download the model from NLP Lab and upload it to the NLP Models HUB form. It also pre-fills in as much as possible the model form with model metadata, usage code, and example results. This way, the model publication becomes accessible and convenient for non-technical users who want to share their models with the community.
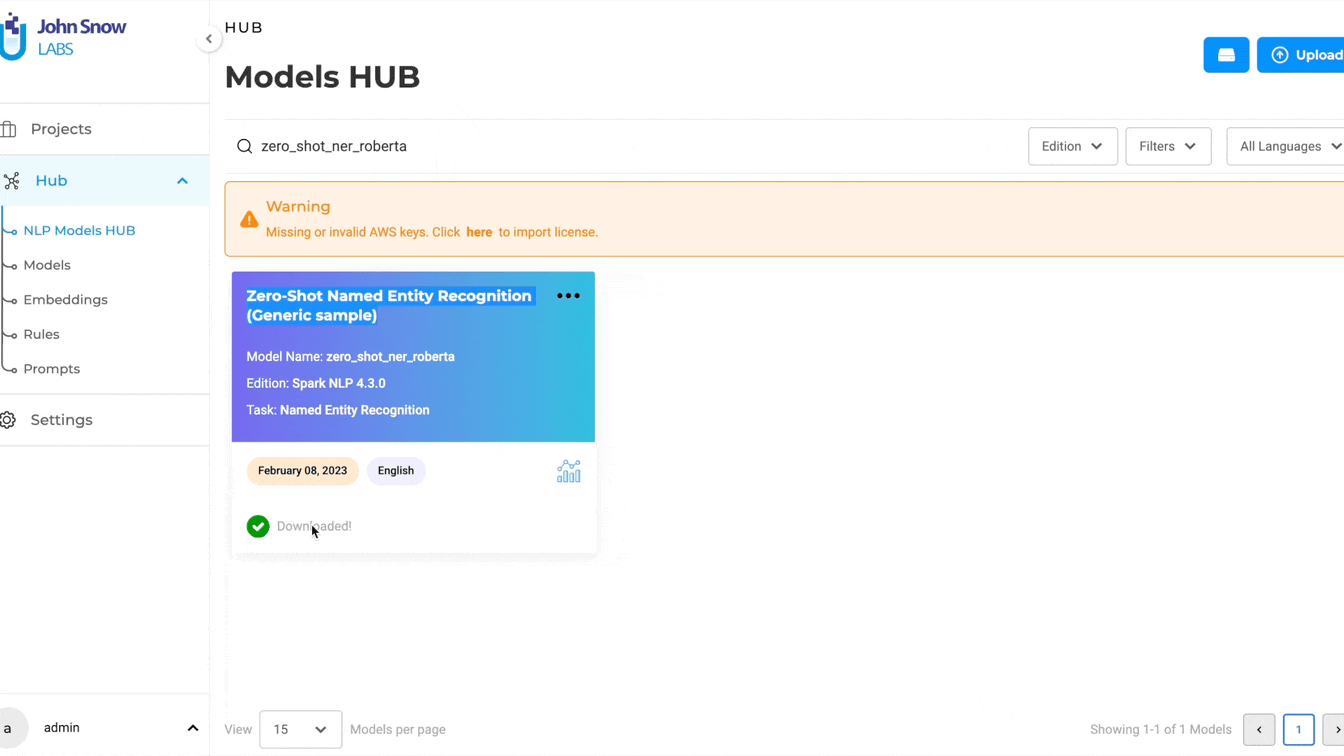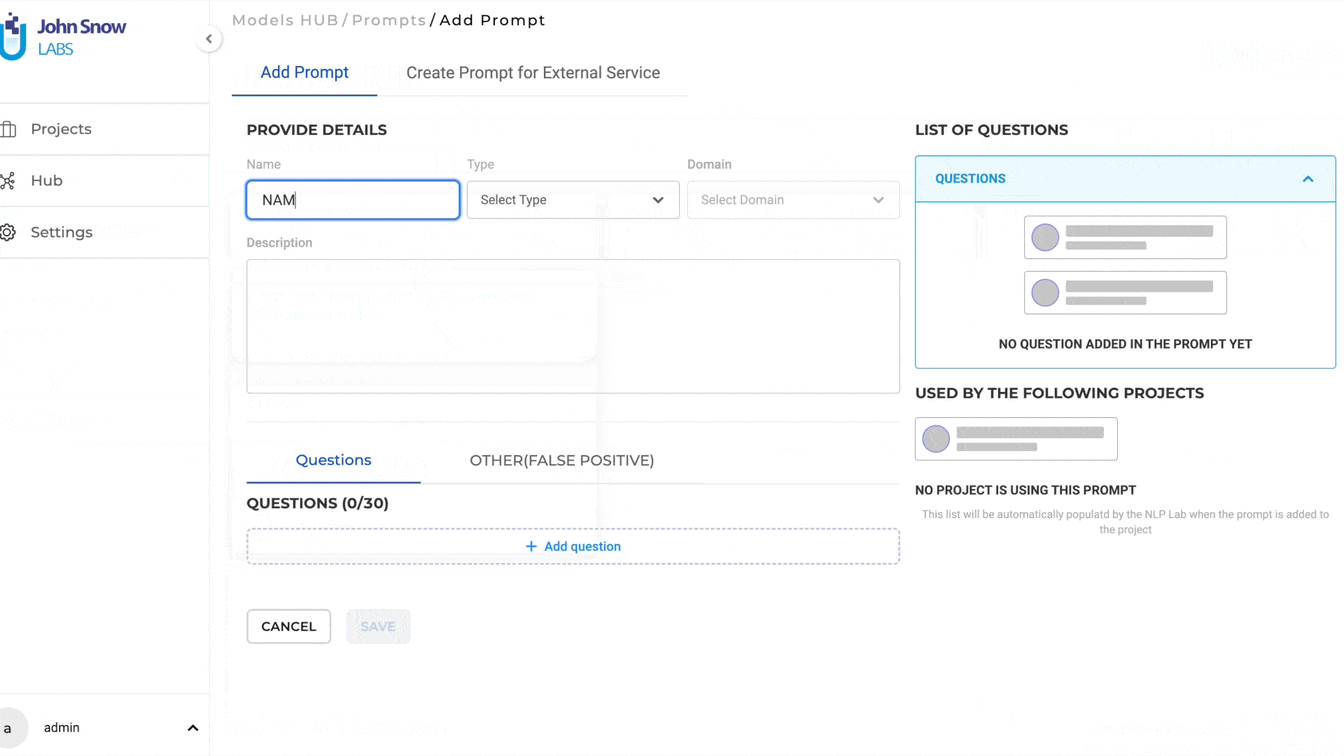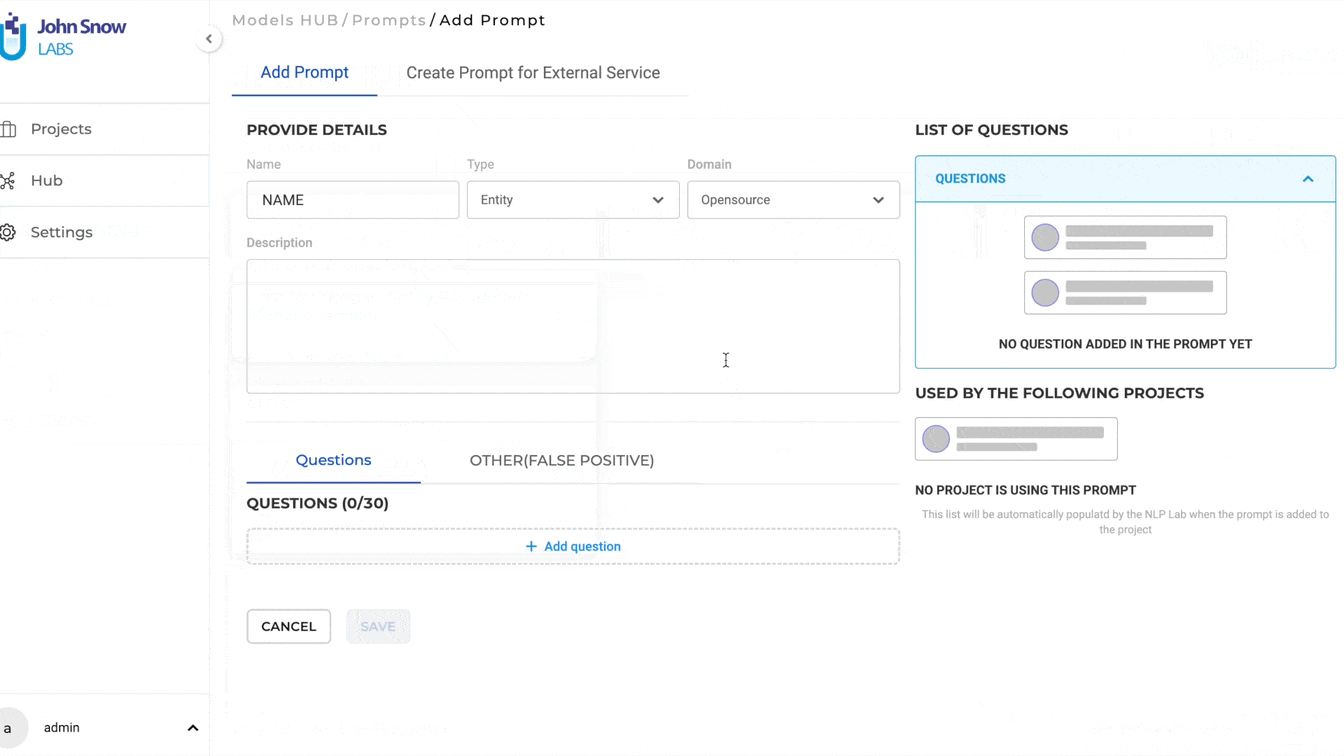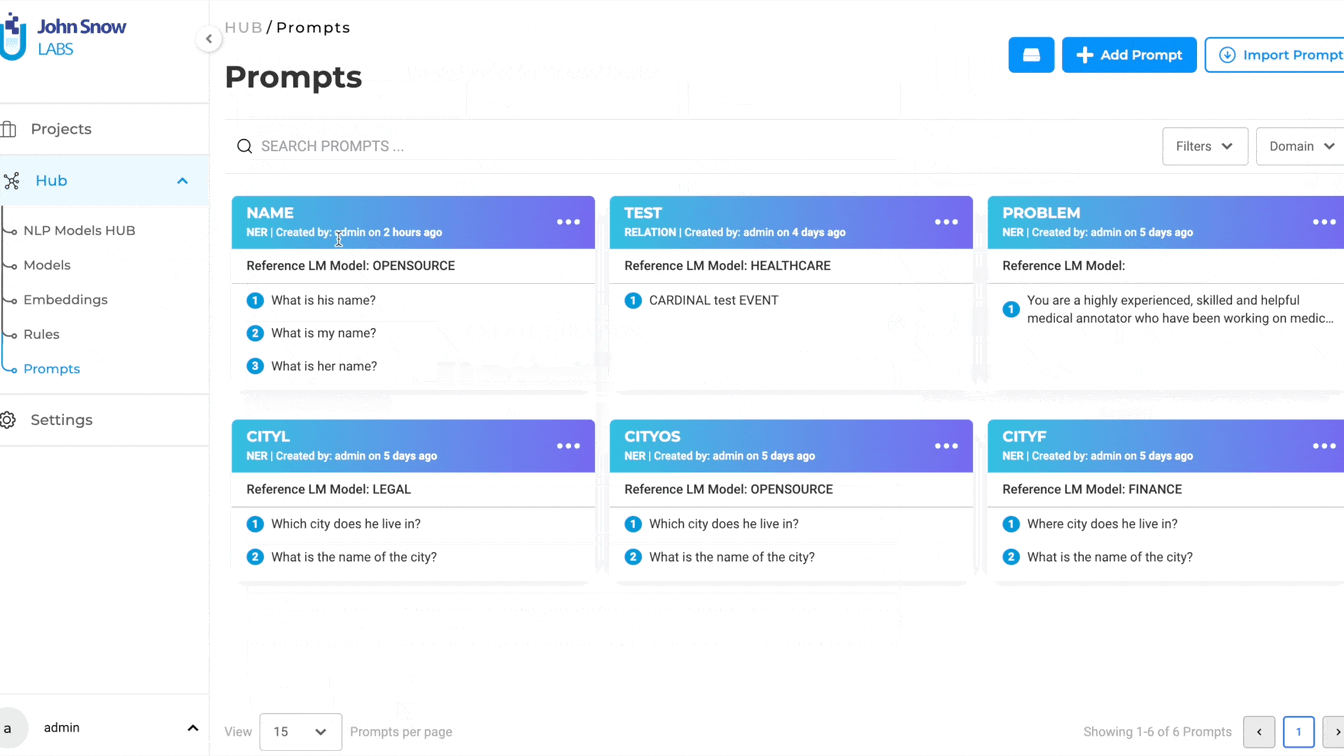
Zero-Shot NER Prompts are now available for FREE
Prompt engineering is gaining traction as a fast-evolving discipline that aims to guide advanced language models like GPT-3 to generate precise and intended results, such as answering queries or constructing meaningful narratives. While NLP Lab has previously provided support for prompt engineering, the feature was restricted to users with license keys. We are now taking this a step further by offering this entity extraction feature for free to a broader user base.
With the 5.4 release, NLP Lab enables the unrestricted design and application of Zero-Shot Prompts for entity identification in text. To create NER prompts, users should first download the Roberta zero-shot NER model from the Models HUB. Afterward, they can select the Open-source Domain while setting up an NER prompt. As part of prompt definition, users can specify one or more questions, the answers to which will serve as the target entities for annotation.
Additionally, for enhanced performance, zero-shot prompts can be seamlessly integrated with GPT prompts, programmatic labeling, and other pre-trained DL models to achieve even more accurate and effective outcomes.
Merge Completions and Predictions for enhanced annotation
Responding to customer feedback, version 5.4 brings a substantial upgrade to our annotation capabilities. Users can now consolidate individual completions and predictions into one unified completion. This merging can occur between predictions and completions and can involve single or multiple annotators.
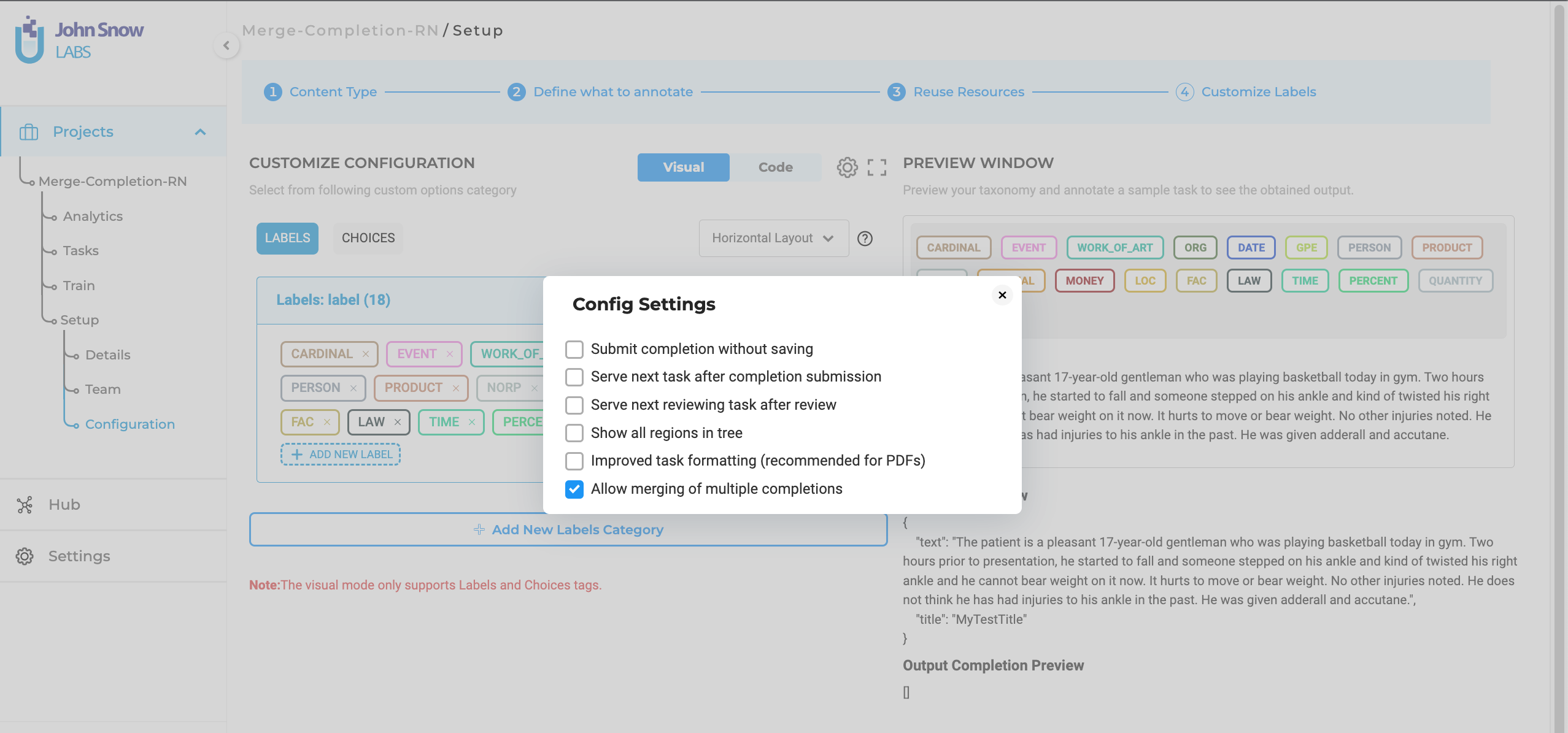
To access this feature, users must first activate the ‘Merge Prediction’ option within the project configuration settings.
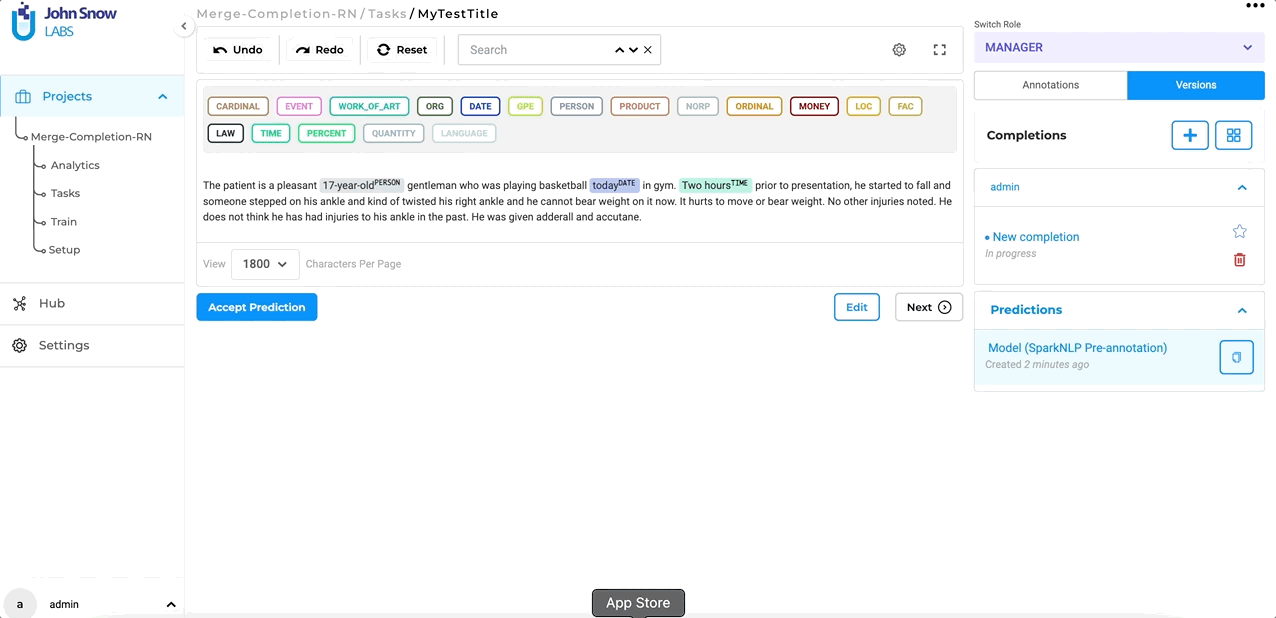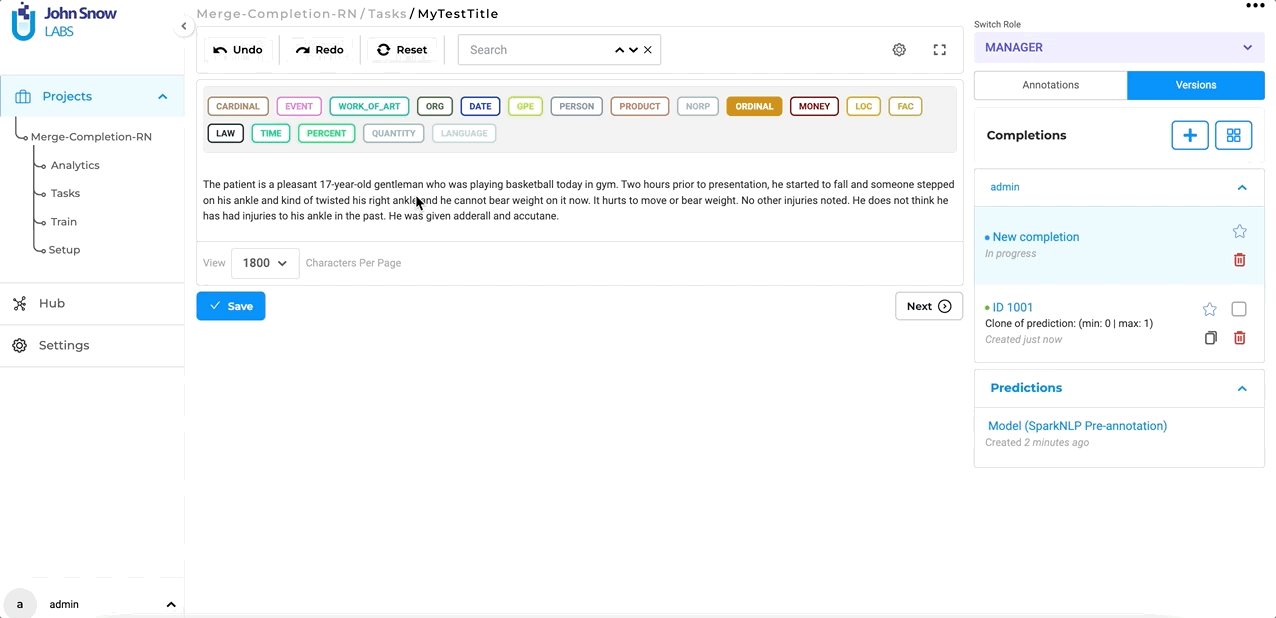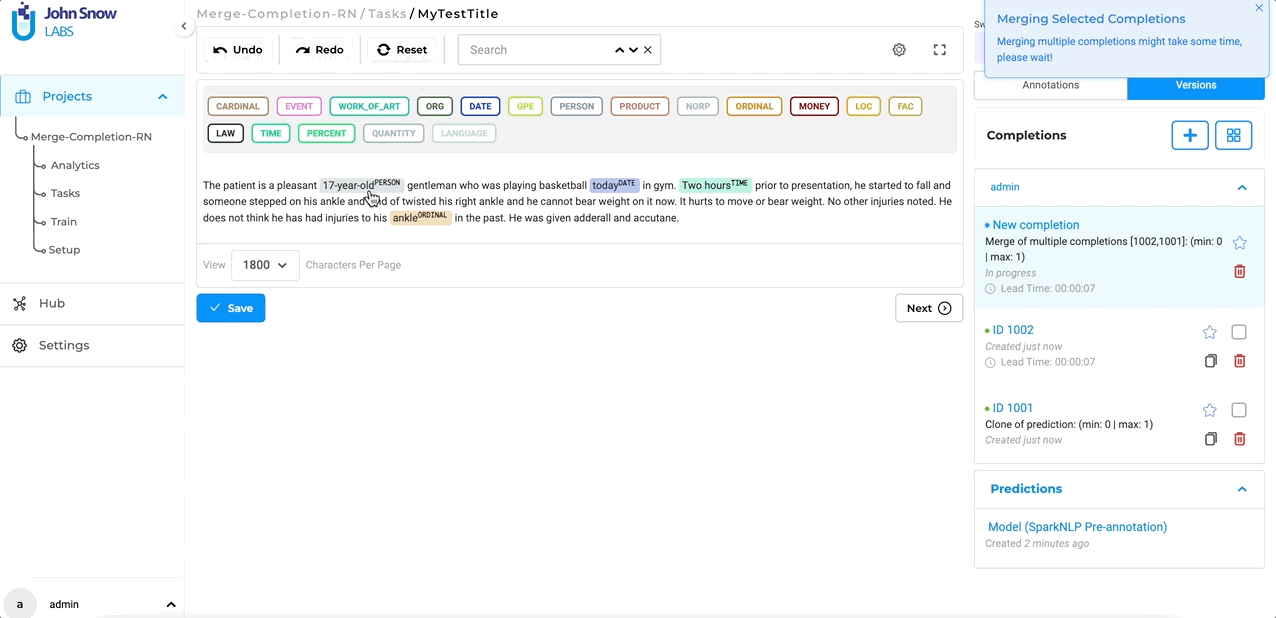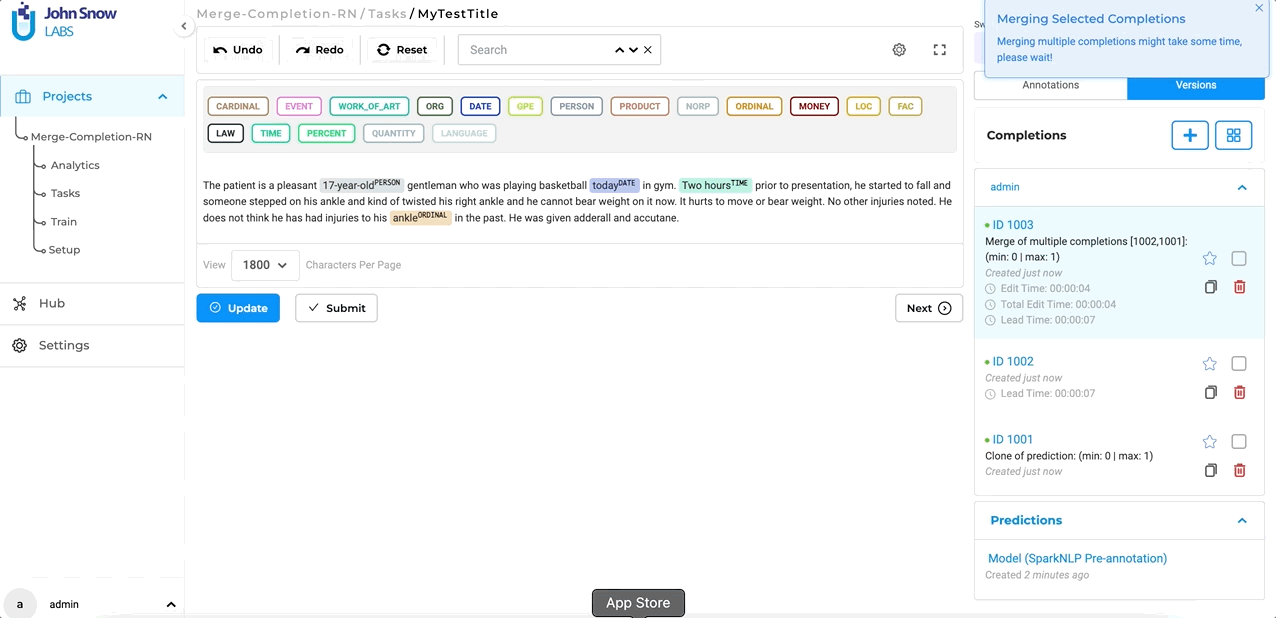
After enabling this setting, users will have the ability to combine multiple completions into a single, unified completion for more streamlined annotation. For this, you simply select the versions you want to merge from the Versions panel and click the Merge button. NLP Lab makes sure to clean up the resulting completion by only retaining one version of identical chunk annotations.
This provides a simple way to enrich existing completions with new pre-annotations, particularly when you wish to introduce new entities or choices to your project. To do so, simply add the new entity or choice—linked to a model, rule, or prompt—into your project configuration. Then, pre-annotate your task and combine the existing completion with the new prediction.
Additionally, this new feature streamlines the review process, as reviewers can now consolidate the contributions of multiple annotators into a single, unified completion.
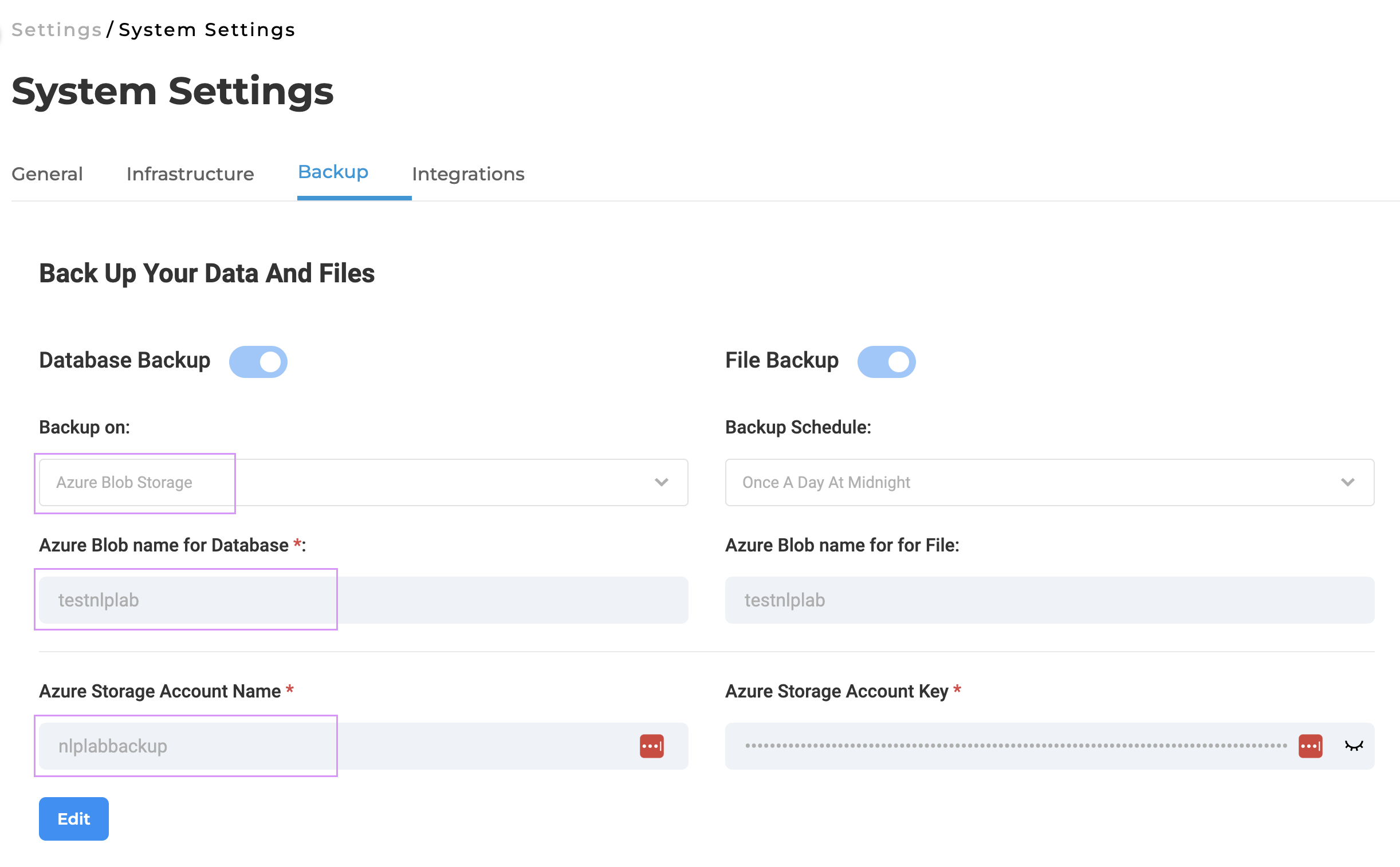
Backup Integration with Azure Blob in NLP Lab
In this new version, NLP Lab introduces a feature that allows users to easily configure backups for databases and files directly to Azure Blob, all through a user-friendly interface. Administrators can manage these backup settings by navigating to the System Settings tab, where they can enter the necessary Azure Blob credentials. Users have the flexibility to choose from multiple backup frequencies and specify a particular Blob container for storing the backup files. Once configured, new backups will be auto-generated and stored in the designated Azure Blob container according to the chosen schedule.
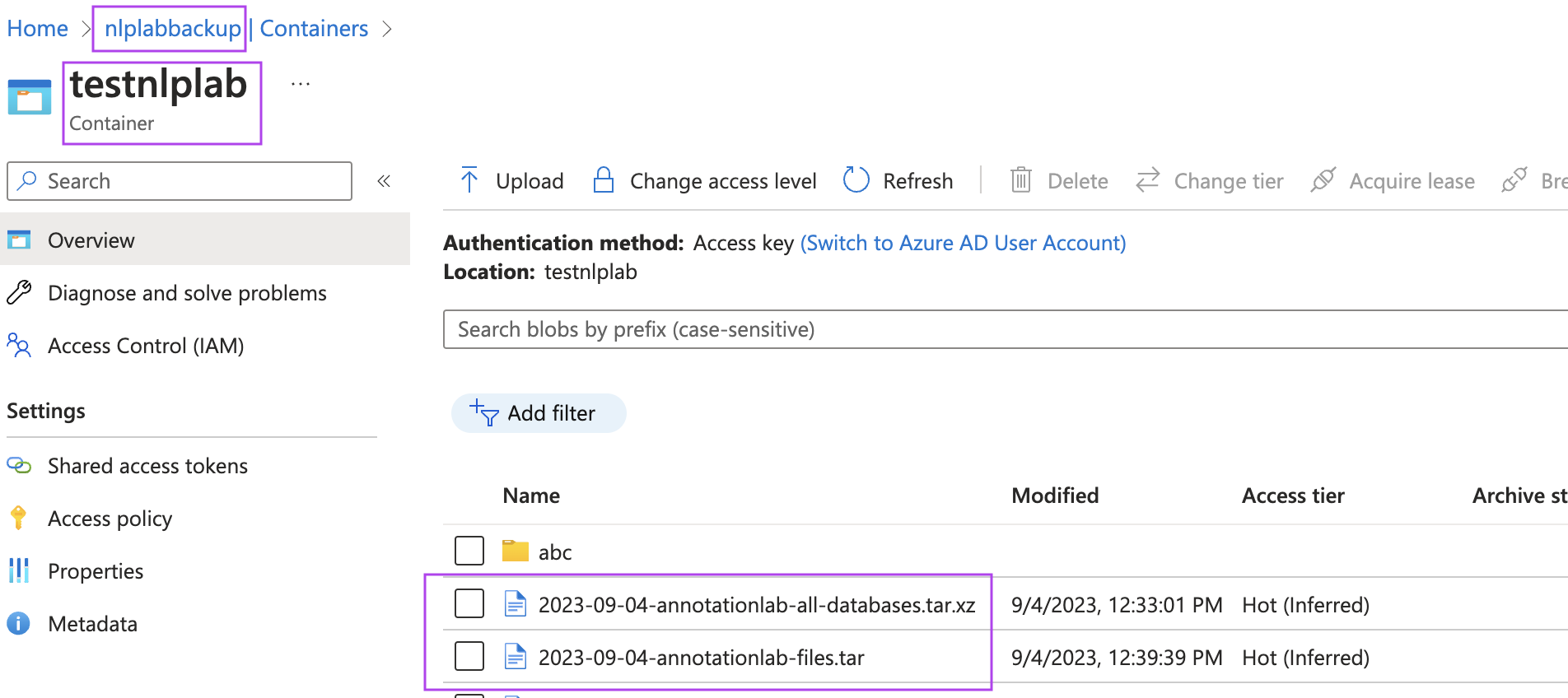
This feature plays a crucial role in disaster recovery planning. For comprehensive guidance, refer to the “instruction.md” file included with the installation artifacts of this release. Below is an example of backup files in Azure Blob configured as per the settings in the NLP Lab.
Improvements
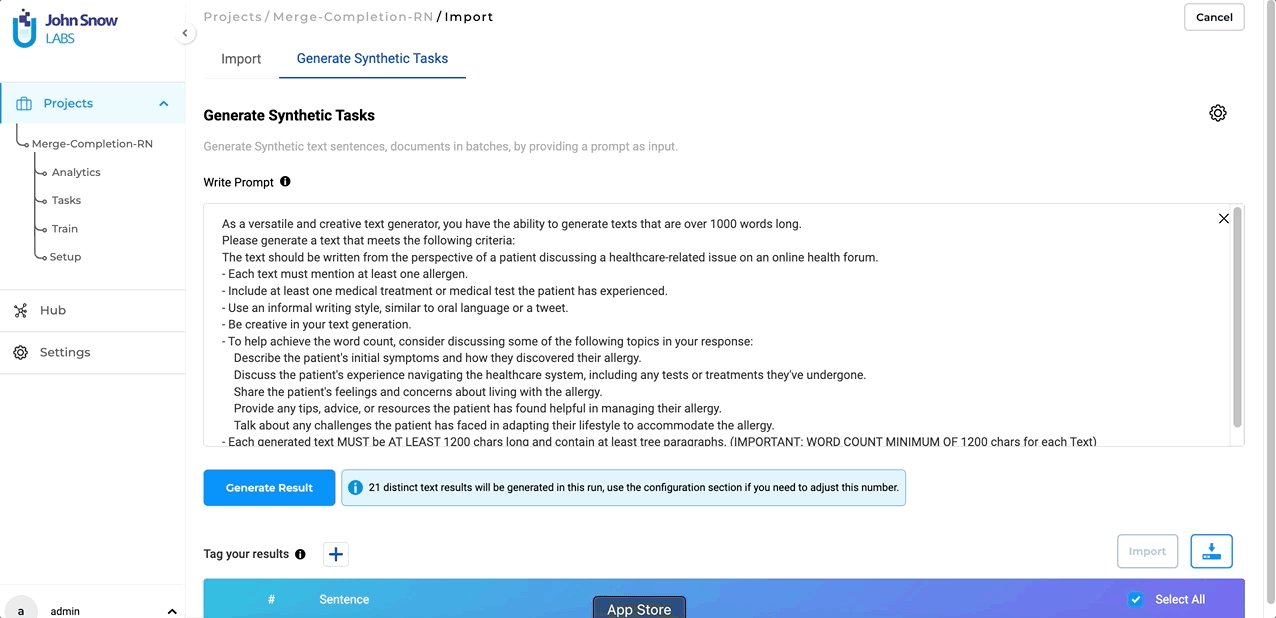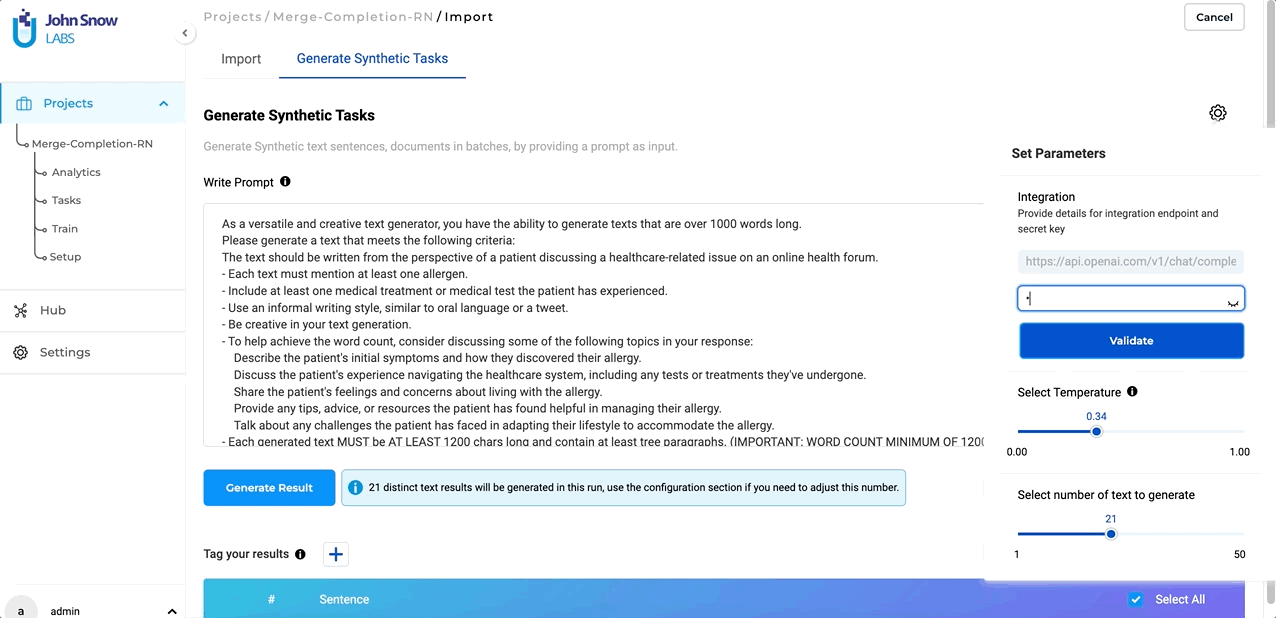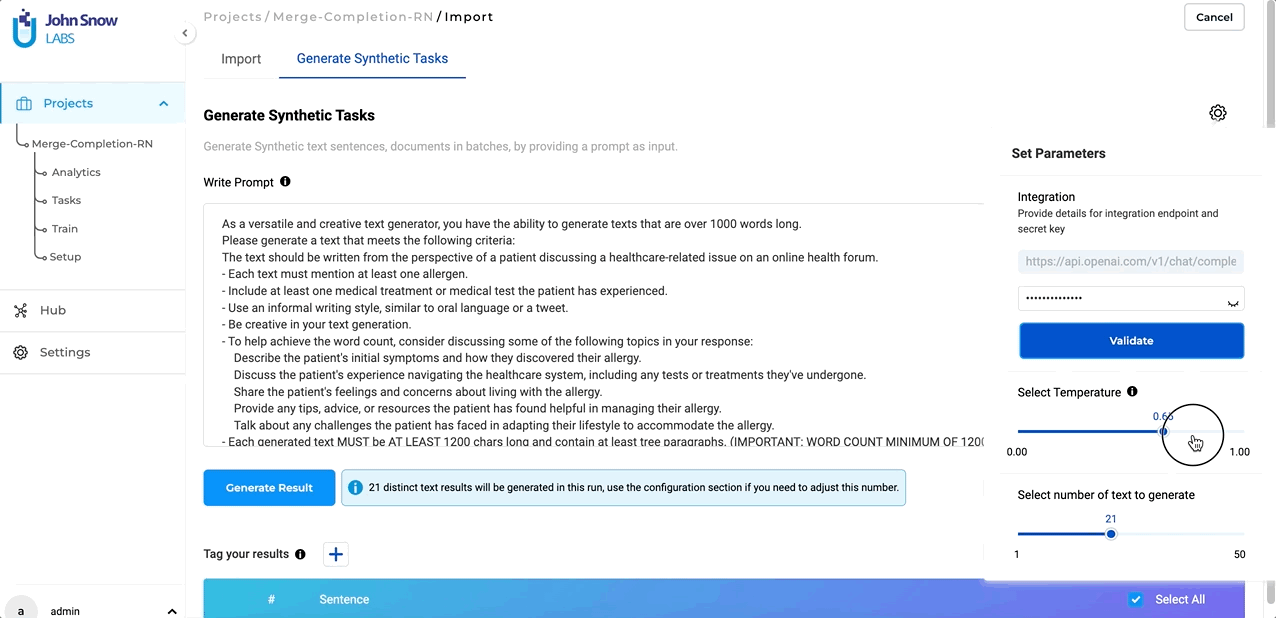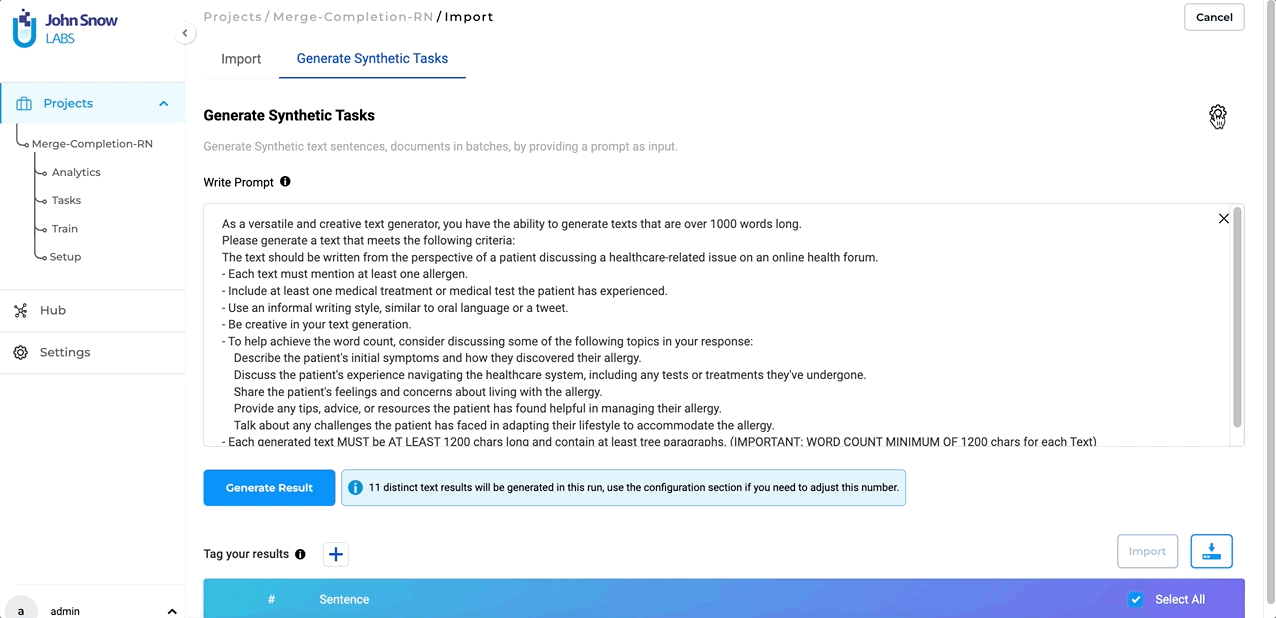
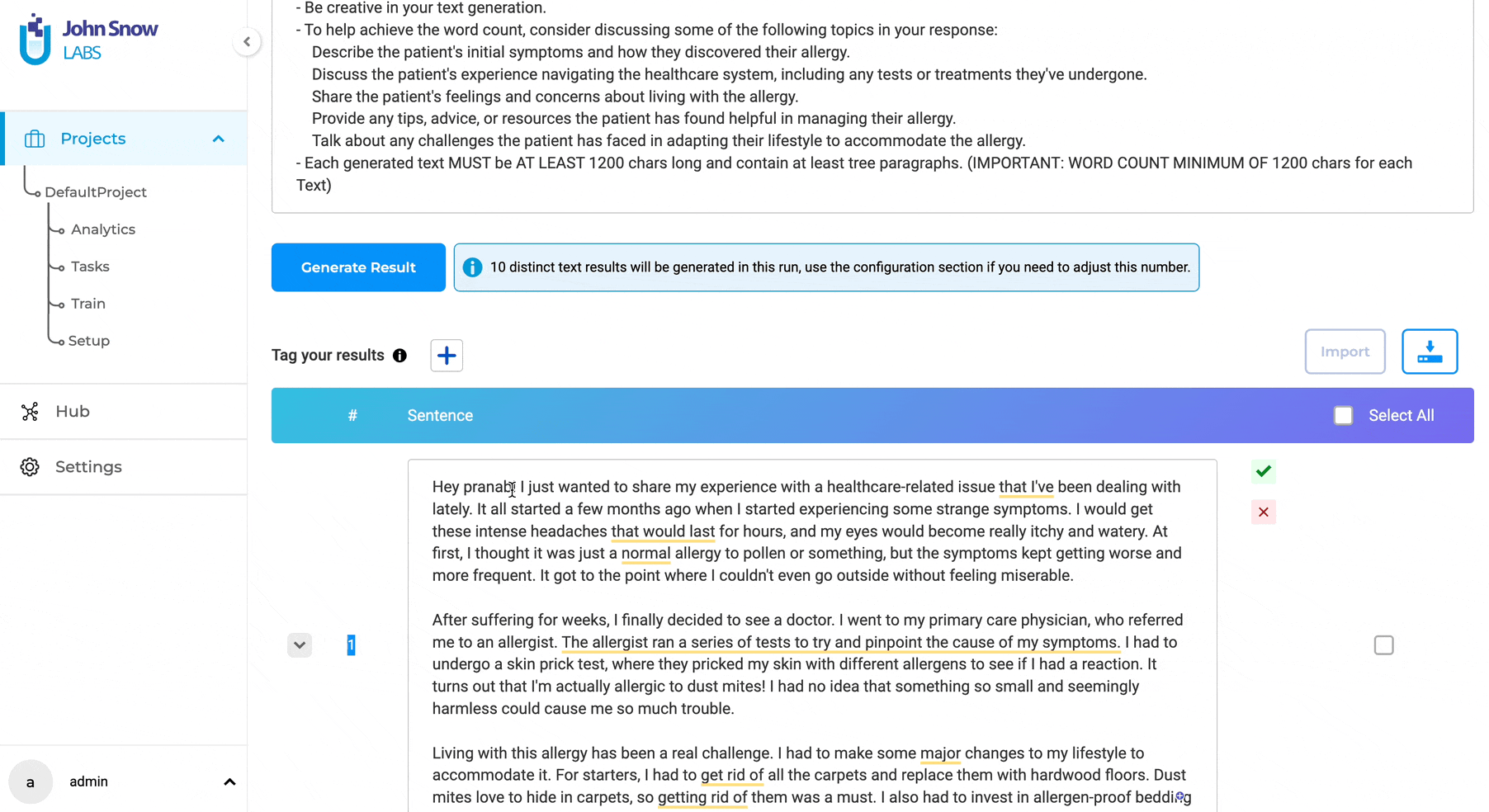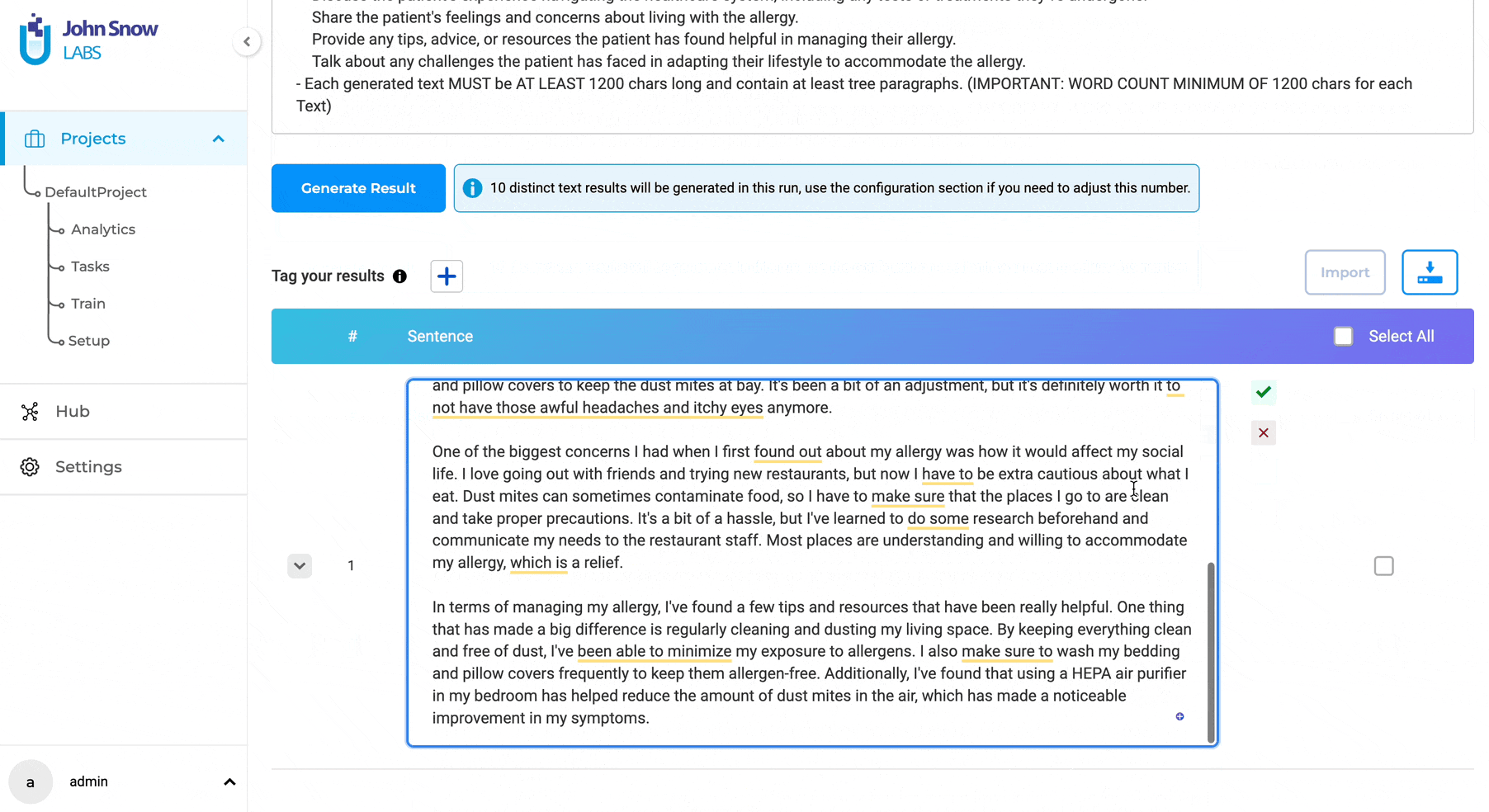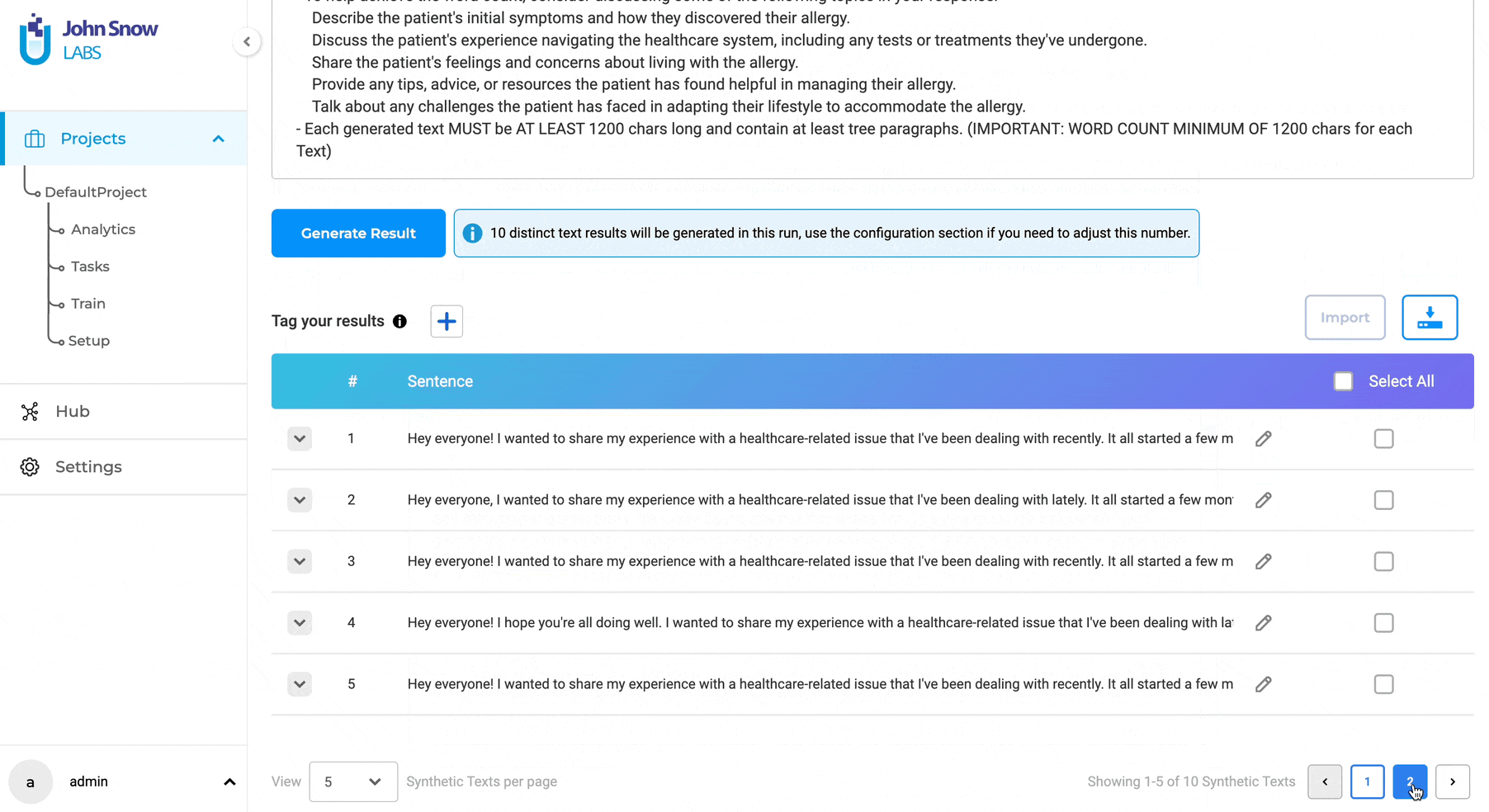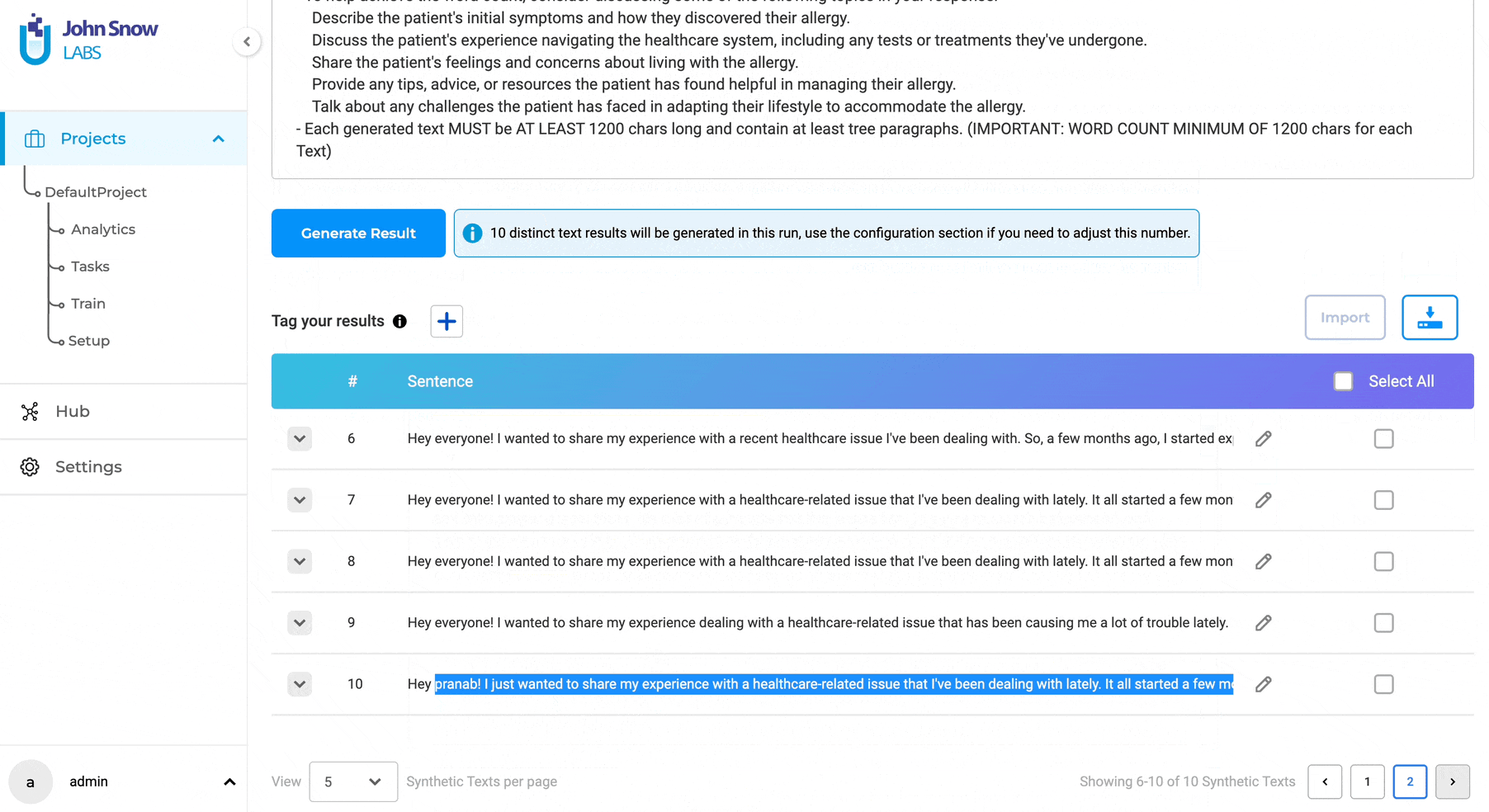
Improved User Experience for Synthetic Text Generation
In version 5.4, we have overhauled the Synthetic Text Generation page to provide a more user-friendly and efficient experience, while preserving all the familiar features and capabilities. The parameter settings, which were previously visible on the main page by default, have been moved to a convenient pop-up window, resulting in a cleaner layout. To access these settings, simply click on the settings icon located on the right-hand side of the page. It’s important to note that all settings, parameters, and functionalities remain unchanged from previous versions.
Switching between Section-Based Annotation (SBA) and Non-SBA Configurations
NLP Lab already offers support for “Section-Based Annotation (SBA)” with the ability to customize labels for specific sections, with these configurations located in the XML configuration file under the “Customize Labels” section. As part of our ongoing improvements, the XML configuration will now automatically remove custom labels associated with sections when the “Section-Based Annotation (SBA)” configuration is removed from the project. This enhancement ensures that the labels become available for the entire task, further enhancing the efficiency and flexibility of the annotation process.
Mapping Labels to Sections in Project Configuration
NLP Lab 5.4 includes several subtle yet significant improvements to the Section Association settings within Project Configuration:
- Convenient “Select All” Checkbox: For enhanced workflows, we’ve introduced a “Select All” checkbox that simplifies the process of activating all associations between labels and sections.
- Sticky “Section Title” Column and “Label Name” Row: To facilitate error-free association assignments, both the Section Title Row and Labels Row are now sticky, ensuring they remain visible during scrolling.
- Adaptive Title Cell Width: The Title Cells have been dynamically calibrated to adjust their width based on the content they contain, enhancing the readability and usability of the interface.
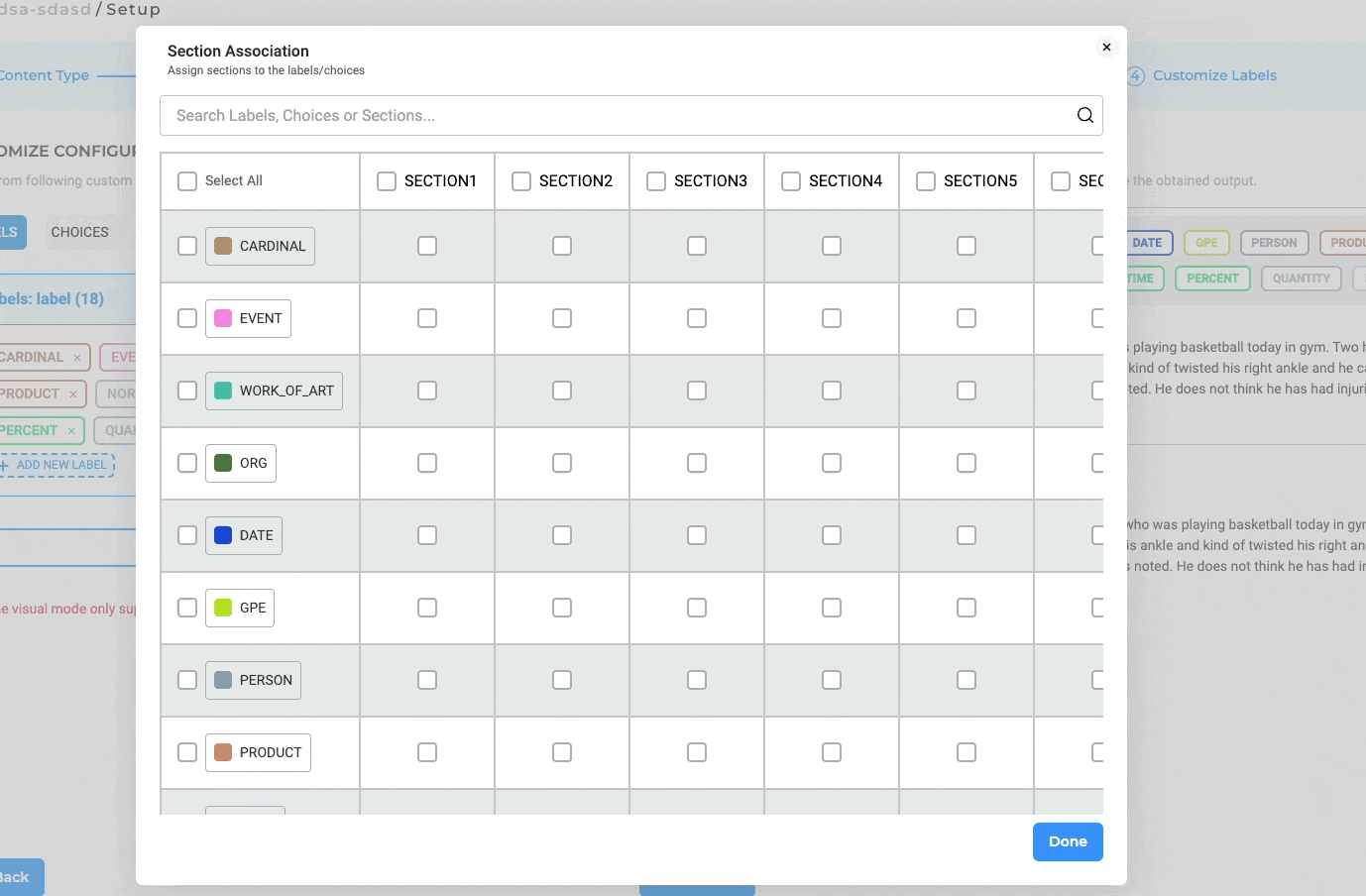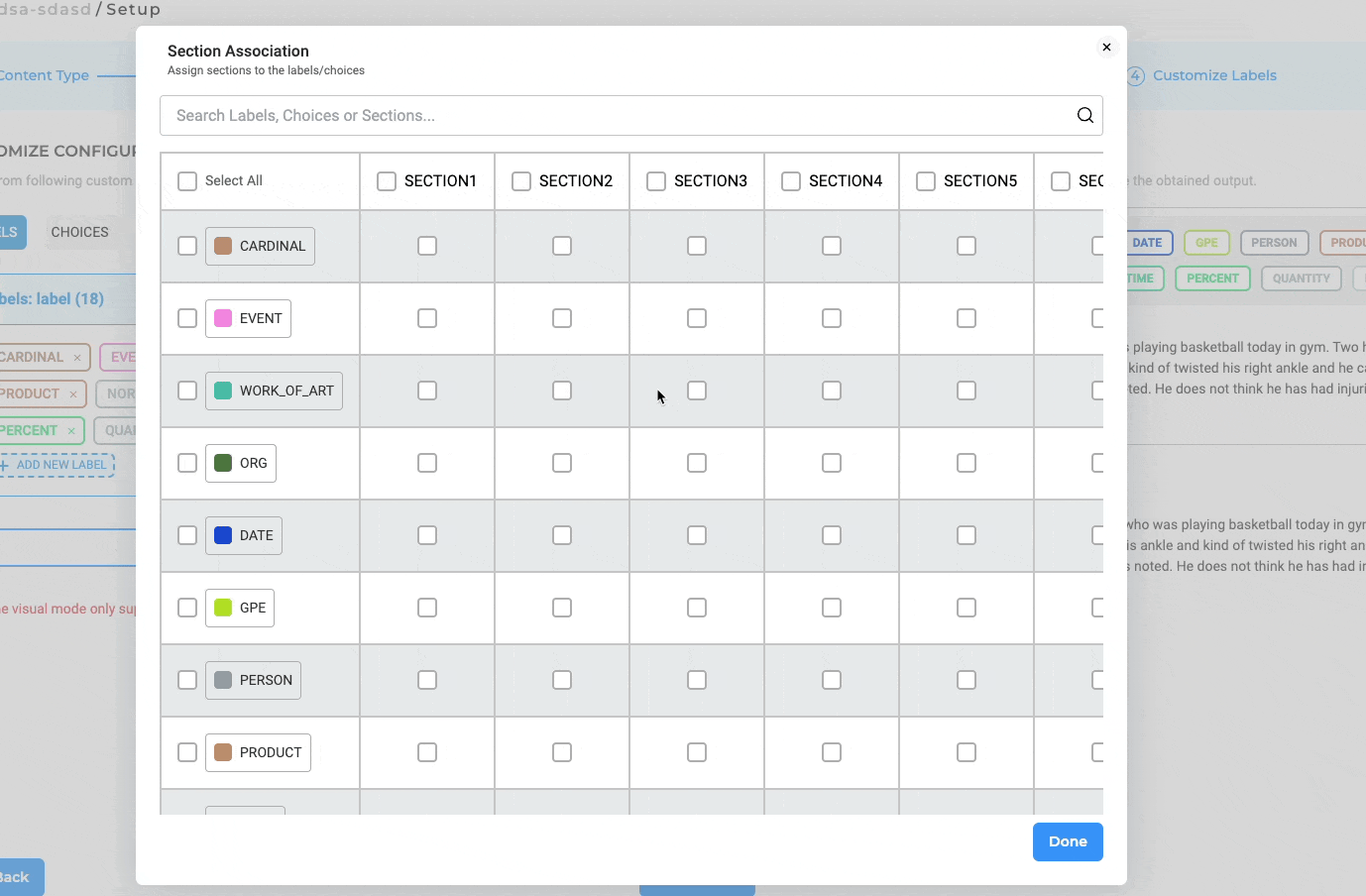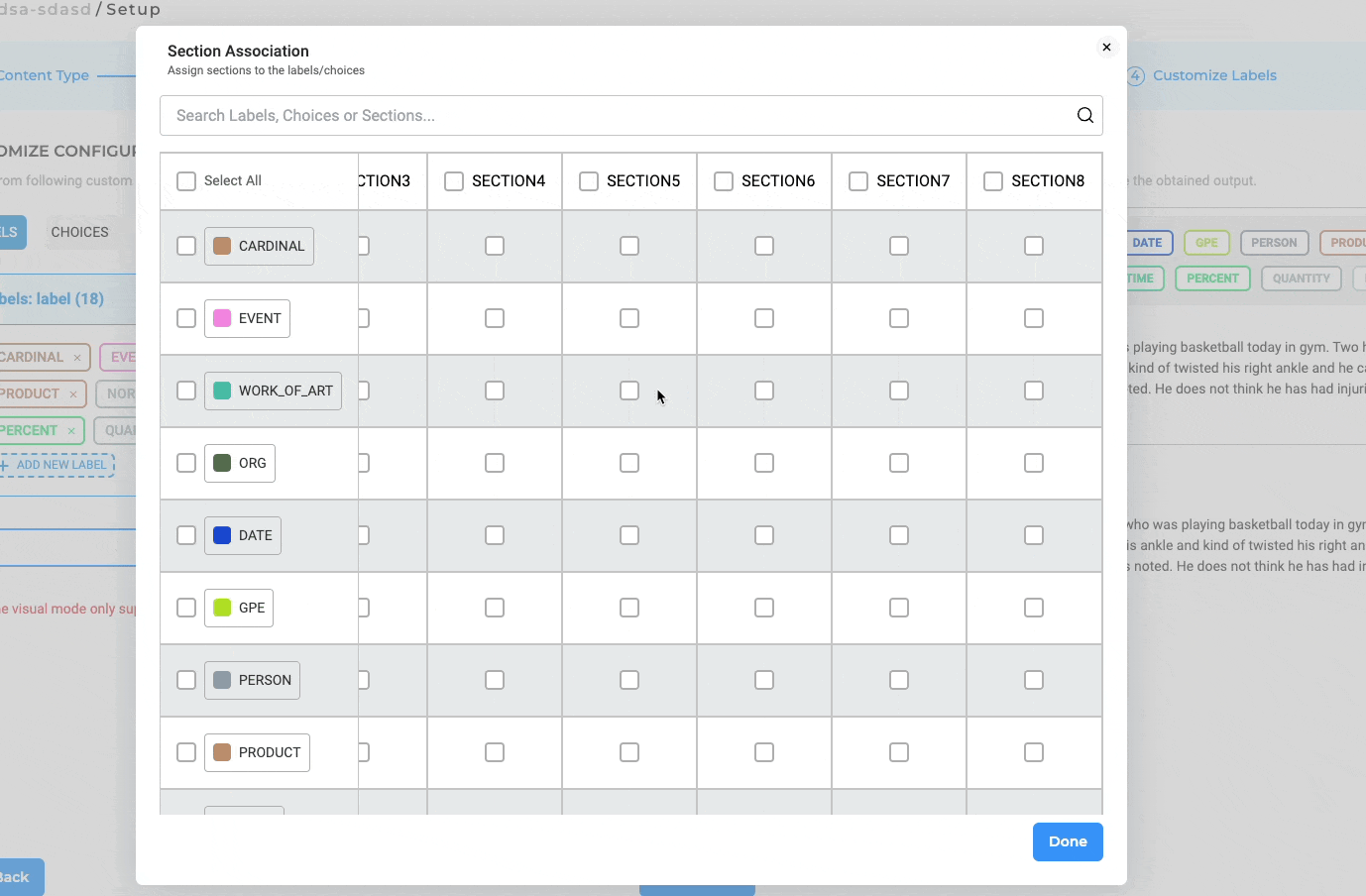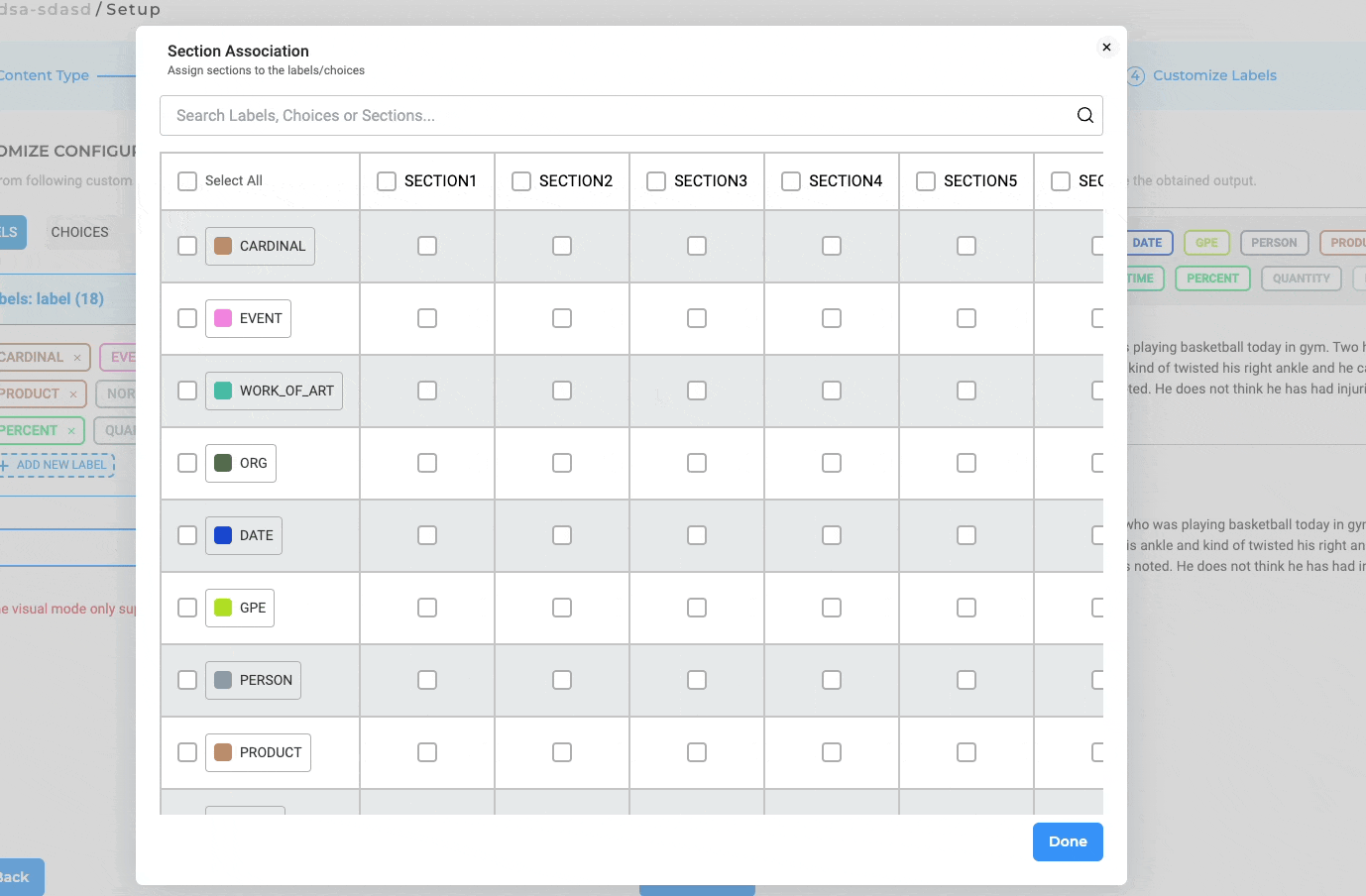
Validation for Assertion Labels in Project Configuration
In earlier versions, when the ‘assertion=true’ attribute was missing in the project configuration for assertion labels, deploying the model would result in a pre-annotation server crash. In our latest release, we’ve introduced a robust check to ensure a smoother experience.
Now, if a user attempts to associate assertion models with a label but forgets to include the ‘assertion=true’ attribute in the project XML, a user-friendly error message will be prominently displayed on the configuration page. This proactive alert serves as a helpful reminder to rectify the configuration, preventing any unintended disruptions and ensuring the reliability of your project setup.
###Bug Fixes
-
Improved Cluster Page Error Handling:
In previous versions, the cluster list page had issues displaying servers for Kubernetes clusters with multiple namespaces. This problem only occurred when NLP Lab was installed using the default namespace. With version 5.4, this bug has been successfully fixed.
-
Precise Pre-annotation Indexing:
Previously, when text contained multiple spacing and tabs in a task, the pre-annotation label index did not match the actual pre-annotated texts. In the current version, this issue has been resolved, ensuring consistent pre-annotation label indexing even with varying spacing and tabs.
-
Visibility of Pre-annotation Progress:
In the past, when tasks were manually selected for pre-annotation, the pre-annotation results’ status was not visible. With version 5.4, this issue has been resolved, and pre-annotation status is now displayed accurately.
-
Enhanced Bulk Pre-annotation:
In the prior version, the bulk pre-annotation process occasionally failed to yield results for certain tasks, despite being visually indicated as successfully pre-annotated (highlighted in green). However, in this current release, the pre-annotation results are precise, consistent, and presented comprehensively.
-
Streamlined Model Addition:
In the previous version, when additional models were added to a project from the “re-use” tab and saved, users were redirected to the task page. With version 5.4, users aren’t redirected to the Task page after adding additional models from the “Reuse Resource” page.
-
Improved Editing Experience for Synthetic Tasks:
In earlier versions, editing tasks generated by ChatGPT when multiple tasks were being generated caused auto-refresh issues. The latest version reinstates auto-refresh after task editing is complete.
-
Confidence Scores for Pre-annotations generated by OpenAI Prompts:
In previous versions, the confidence score for all OpenAI prompt results was 1. This problem has since been resolved, now for each prompt prediction, it will display actual confidence scores if provided by the OpenAI platform.
-
Enhanced Search Functionality:
In previous versions, the presence of unintended whitespaces preceding or succeeding the search keyword would result in a failure to yield any search results. This issue has been rectified across all search fields in NLP Lab. Rigorous testing has been conducted to ensure the accuracy and precision of the search functionality.
-
Selective Classification Models for SBA configuration:
Previously, the SBA classifier dropdown listed both downloaded and failed-to-download classification models, leading to errors. Version 5.4 only displays successfully downloaded classification models.
-
Optimized Export for Visual NER Projects:
The latest version, has significantly reduced the file size of exported projects by adopting a streamlined approach. This enhancement is achieved by selectively including only the OCR images of the filtered files, thereby optimizing both storage efficiency and overall project performance.
-
Tagging issues while importing synthetic tasks:
Previously, users were able to assign both “task” and “train” tags to the synthetically generated tasks, due to which when multiple tags were selected then some tasks were hidden. The issue has been fixed and users can no longer assign the “test” and “train” tags to the tasks in this version.
-
Validation Error Resolution:
Previously, validation errors encountered within the “Reuse Resources” screen inadvertently disabled the option to add other models by rendering the button non-functional. This limitation has been successfully resolved, ensuring that users can now seamlessly rectify errors and continue their debugging processes without any restrictions.
-
Undo action not working for the Section-Based Projects:
Previously, when performing an Undo operation for a section containing NER labels that had been deleted, only the labels were restored, leaving the section inactive. Subsequently, clicking ‘save’ resulted in orphaned labels. With the latest version of NLP Lab, when an Undo operation is performed, both the section and the associated labels are fully restored, ensuring data consistency and accurate user experience.
-
Preservation of Imported Sections:
In the earlier version, when tasks were imported with “Preserve Imported Sections” option enabled, the sections were created as per the section rules defined by the user instead of applying the above option and use the sections defined in the imported JSON file. In the current version when the section rule does not match the section of the imported JSON/Zip file for a task then no relevant section is created.
-
Classification Filter Functionality:
The “Filter by Confidence Score” was experiencing issues, particularly within Section-Based Configured Projects. In the latest version of NLP Lab, this has been resolved, and the filter functions as intended, ensuring accurate and effective filtering capabilities.
-
Improved Sample Task Import for Visual NER Projects:
In this release, the issue where sample files for Visual NER projects imported from exported files were failing to load in the NLP Lab UI has been addressed. This fix guarantees that all exported files will maintain their integrity and load seamlessly.
-
Task List Count Consistency:
In certain cases, a disparity in the count of incomplete tasks arose during the assignment and submission of completions by various team members within projects. This issue has been resolved. Now, all team members can expect the task list numbers to align with their user role, ensuring a consistent and accurate representation of tasks as per the user/role.
-
Enhanced Section Rule Matching:
In certain cases, the entire task was erroneously marked as a section, even when the section delimiter was not found. This issue has been resolved. Now, sections are only created if the delimiter specified in the configuration is present within the task, ensuring accurate section definition and proper section detection.
-
Cluster Server Limit Handling:
When the cluster limit is at total capacity, users will encounter an error message indicating that the cluster limit has been reached. In the previous versions, even after clearing one or more cluster servers to create space for additional active learning deployments, the error persisted, causing active learning to be obstructed. This issue has been successfully resolved, ensuring a seamless experience where the error no longer persists if the cluster limit is cleared, thus allowing unimpeded training/deployment activities.
-
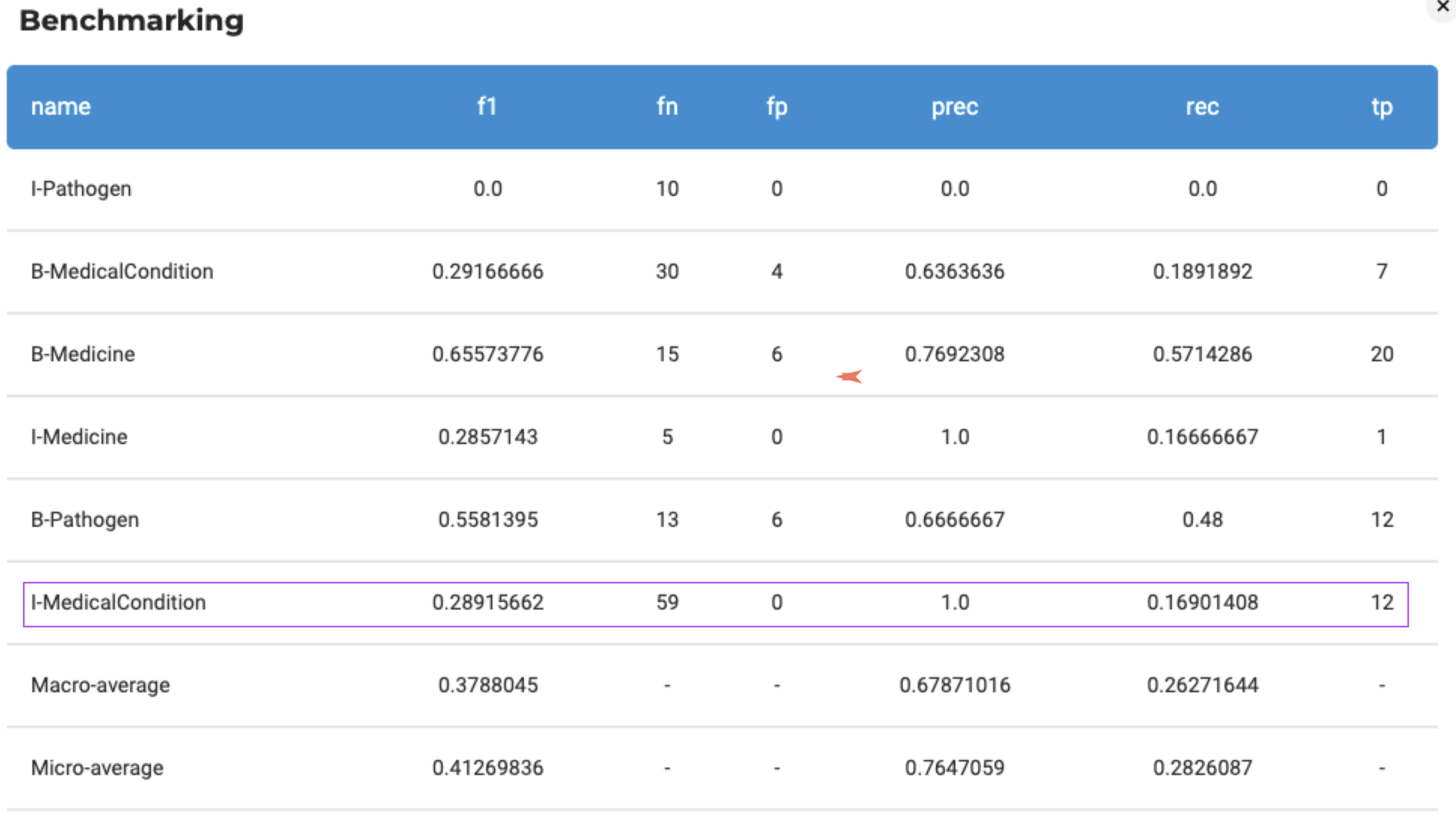
Benchmarking Display Fix:
In the earlier version, the benchmarking for the ‘Inside’ tag was not consistently displayed when viewing the benchmarking results in the UI for certain labels. This information was accessible during model training but was not visible in the UI. We have now resolved this issue.
Versions
- 8.2.1
- 8.2.0
- 8.1.3
- 8.1.2
- 8.1.1
- 8.1.0
- 8.0.1
- 8.0.0
- 7.8.2
- 7.8.1
- 7.8
- 7.7
- 7.6.0
- 7.5.1
- 7.5.0
- 7.4.0
- 7.3.1
- 7.3.0
- 7.2.2
- 7.2.1
- 7.2.0
- 7.1.0
- 7.0.1
- 7.0.0
- 6.11.3
- 6.11.2
- 6.11.1
- 6.11.0
- 6.10.1
- 6.10.0
- 6.9.1
- 6.9.0
- 6.8.1
- 6.8.0
- 6.7.2
- 6.7.0
- 6.6.0
- 6.5.1
- 6.5.0
- 6.4.1
- 6.4.0
- 6.3.2
- 6.3.0
- 6.2.1
- 6.2.0
- 6.1.2
- 6.1.1
- 6.1.0
- 6.0.2
- 6.0.0
- 5.9.3
- 5.9.2
- 5.9.1
- 5.9.0
- 5.8.1
- 5.8.0
- 5.7.1
- 5.7.0
- 5.6.2
- 5.6.1
- 5.6.0
- 5.5.3
- 5.5.2
- 5.5.1
- 5.5.0
- 5.4.1
- 5.3.2
- 5.2.3
- 5.2.2
- 5.1.1
- 5.1.0