5.1.0
Release date: 30-06-2023
NLP Lab 5 - Harness the Power of Section-Based Annotation for Advanced NLP Tasks
We’re excited to announce that NLP Lab 5 is now available! This major update offers out-of-the-box support for section-based annotation, a feature that makes annotating larger documents with deep learning (DL) models or large language models (LLMs) an absolute breeze.
Section-based annotation is a cornerstone feature, that proposes a new strategy to handle manual and automatic text annotation. First of all, it allows the splitting of tasks into distinct sections, at various granular levels such as sentences, paragraphs, or even pages, depending on the requirement of the use case at hand. This approach gives annotators a clear view and fine-grained control over the document structure. Second, it allows users to specify what are the relevant sections for their project’s specific goals. This can be done by a combination of specific keywords that can be found inside the relevant texts, regular expressions (regex) matching particular patterns within the text, or by the use of classifiers specially trained to recognize specific types of sections.
This two-step process ensures that only relevant sections, those most likely to provide valuable insights, are selected for further annotation. The following are three essential benefits related to this process: - streamlined and targeted annotations that ignore irrelevant sections within a task, - context limitation for text processing via LLMs, and DL models for increased performance and speed at lower costs, - customizable taxonomies for each section for focused (pre)annotations.
Relevant sections can be automatically identified by the NLP Lab during the task import step but they can also be manually adjusted/created/removed when required, by the annotators themselves as part of their completions. Limiting the (pre)annotation context is essential in view of the larger integration with LLM we are preparing (stay tuned for NLP Lab 5.2). By focusing on one relevant section at a time, instead of an entire document that can be hundreds of pages long, NLP Lab ensures that the LLM ingests only the relevant context, suppressing distraction by eliminating noise or irrelevant data. This will improve the response time and the precision of predictions while being considerate of the processing costs.
NER tasks are all about precision! Starting with NLP Lab 5 you will be able to associate relevant labels to specific sections of text. This results in more precise entity recognition and reduced chances of false positives. This granularity of annotation is crucial for those working on projects where each detail matters.
For classification tasks, the section-based annotation feature enables classification to be performed at the sentence, paragraph, or page level. This offers unparalleled flexibility to split the task according to the required level of granularity. Whether you are classifying sentences or whole paragraphs, NLP Lab now accommodates your needs in a much more tailored way.
We understand that annotators want to focus their efforts on the most pertinent areas of the documents they process. With section-based annotation, they can focus solely on the relevant sections, leading to better productivity and less time spent scrolling through irrelevant content.
During model training, only the annotations from the relevant sections will be used. This feature drastically reduces the training time required, saving valuable computational resources and accelerating the project timelines. When it comes to preannotations, the models, prompts, and rules now evaluate solely the relevant sections. This thoughtful approach results in more precise pre-annotations and faster computation of results, thereby boosting your project efficiency.
Overall, section-based annotation in NLP Lab streamlines the annotation process, enabling annotators to concentrate on the necessary sections while optimizing training time and enhancing the accuracy of pre-annotations. We’re confident that this new release will significantly improve your NLP project execution. We can’t wait to see what amazing things you’ll do with it!
NLP Tasks compatible with Section-Based Annotation
NLP Lab offers Section-Based Annotation features for the following tasks:
- Named Entity Recognition (NER): NER tasks involving text can now be partitioned into sections using bespoke rules, facilitating an efficient examination and annotation of only the pertinent sections.
- Text Classification: With the introduction of Section-Based Annotation, tasks can now be divided into relevant sections, and each section can be independently classified, eliminating the limitations of classifying the entire task as a whole.
- Combined NER and Classification: NLP Lab’s versatility enables it to support project configurations combining NER and assertion labeling, with classification or relation extraction. Users can now identify relevant sections within the project and carry out classification as well as NER and relation labeling within each section. Specific taxonomies can be defined for each such section that offers more control over the annotation targets.
- Visual NER: Section-Based Annotation is now available for Visual NER projects, specifically designed for image-based tasks. This feature is particularly beneficial when dealing with lengthy PDFs that are divided into sections by page. Users have the ability to specify the specific pages that are relevant to their needs. With Section-Based Annotation, NLP Lab offers a more granular approach to annotation and analysis, allowing users to focus on specific sections and achieve more accurate and efficient results.
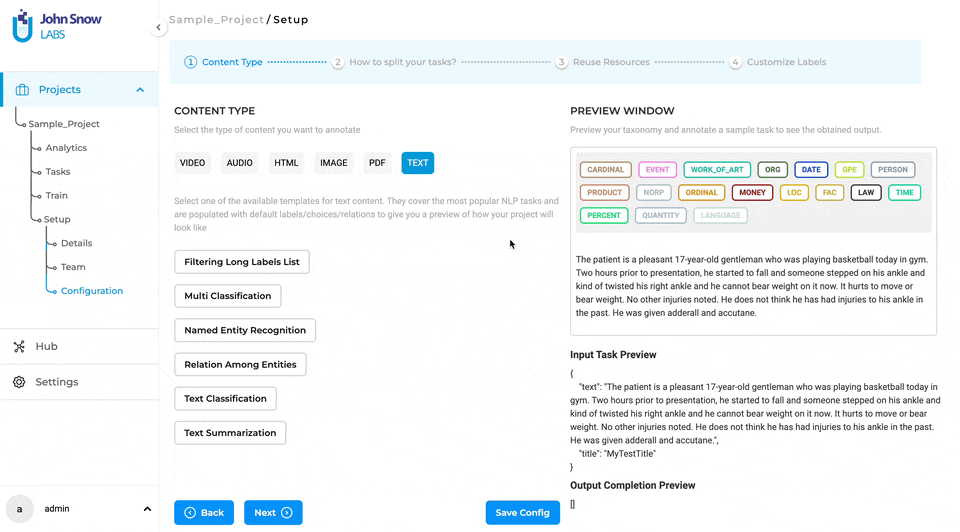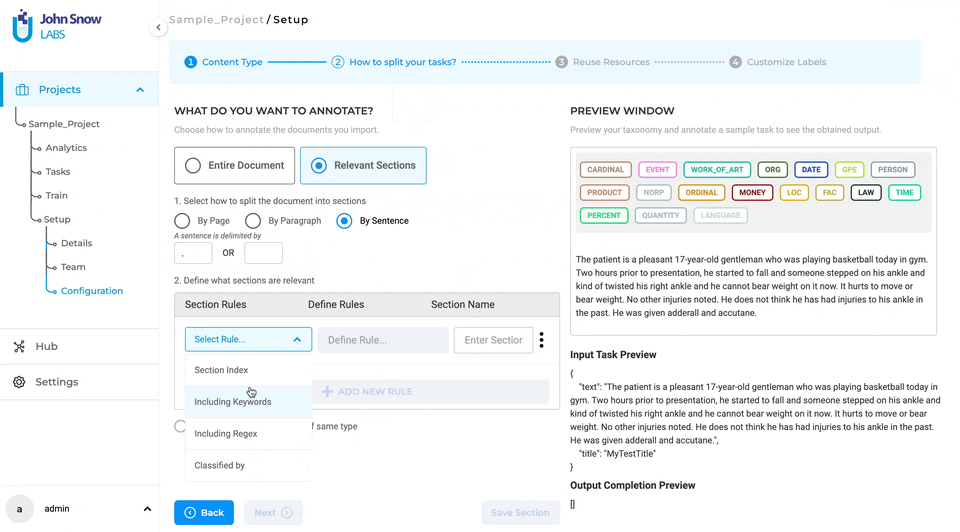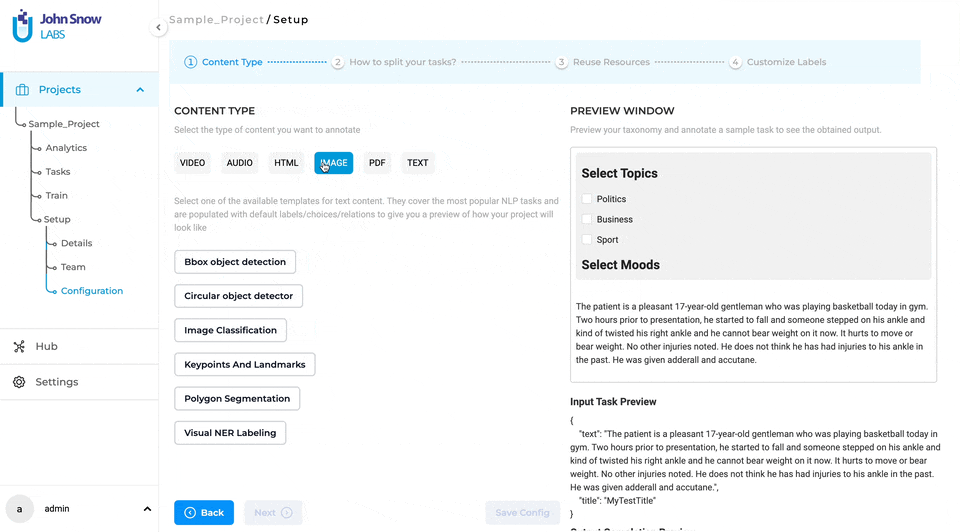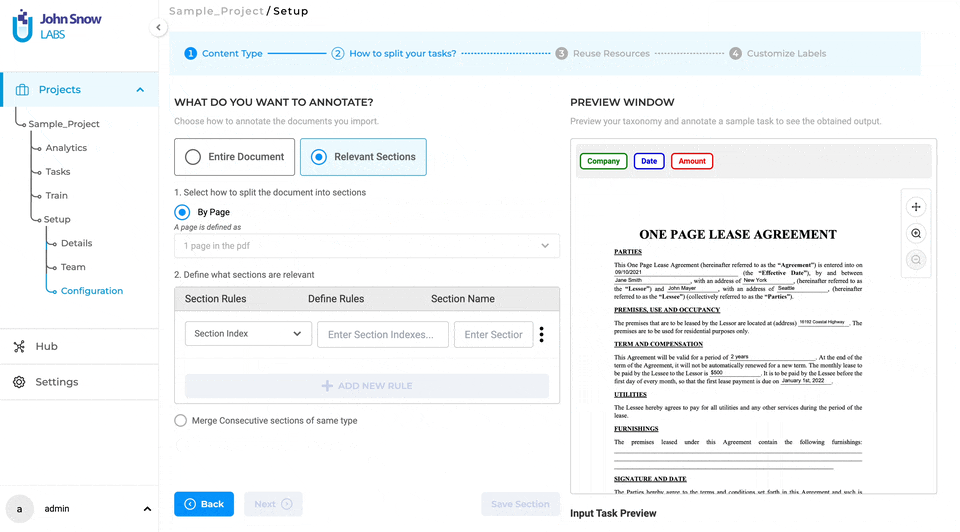
Task Splitting
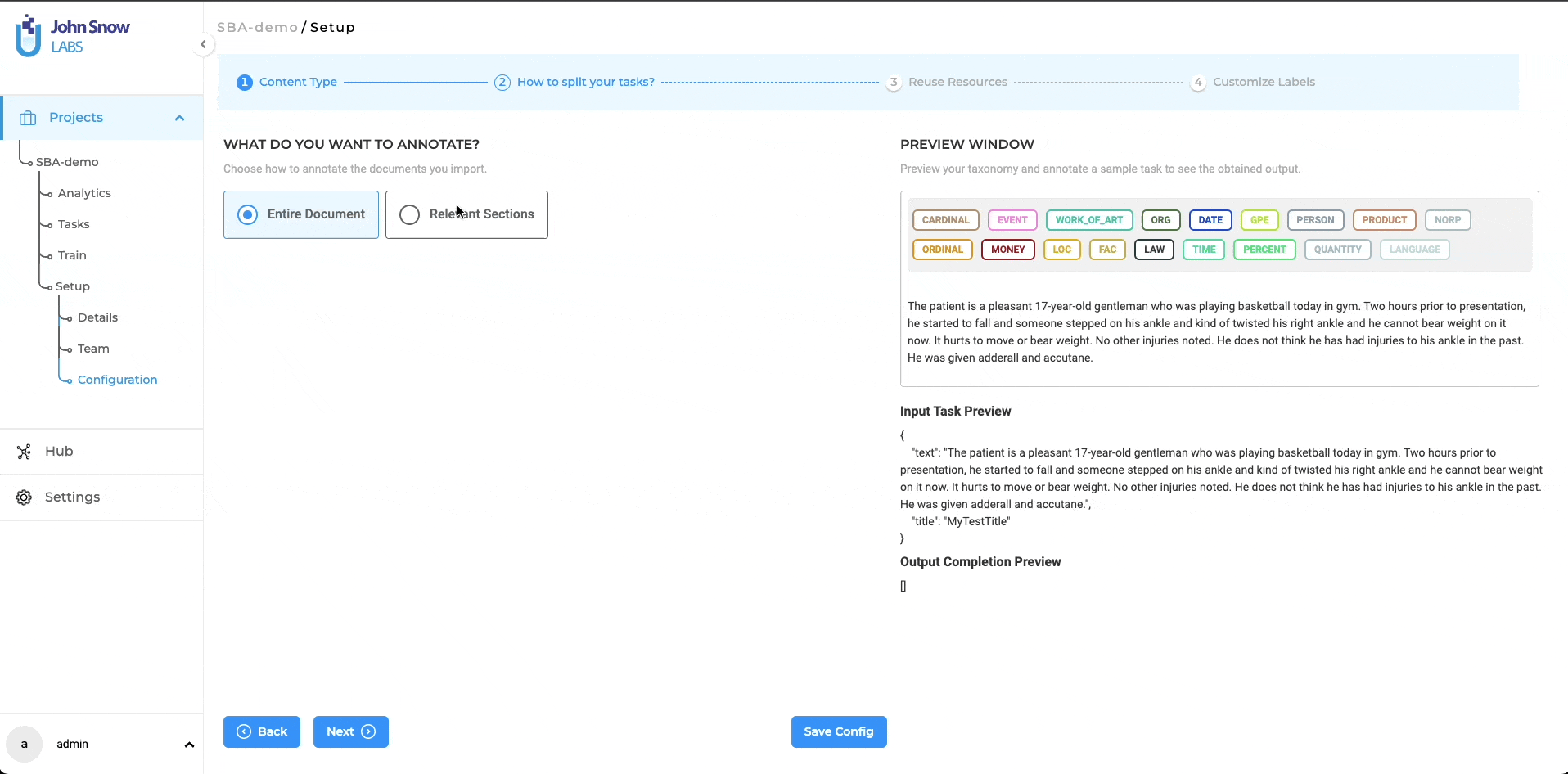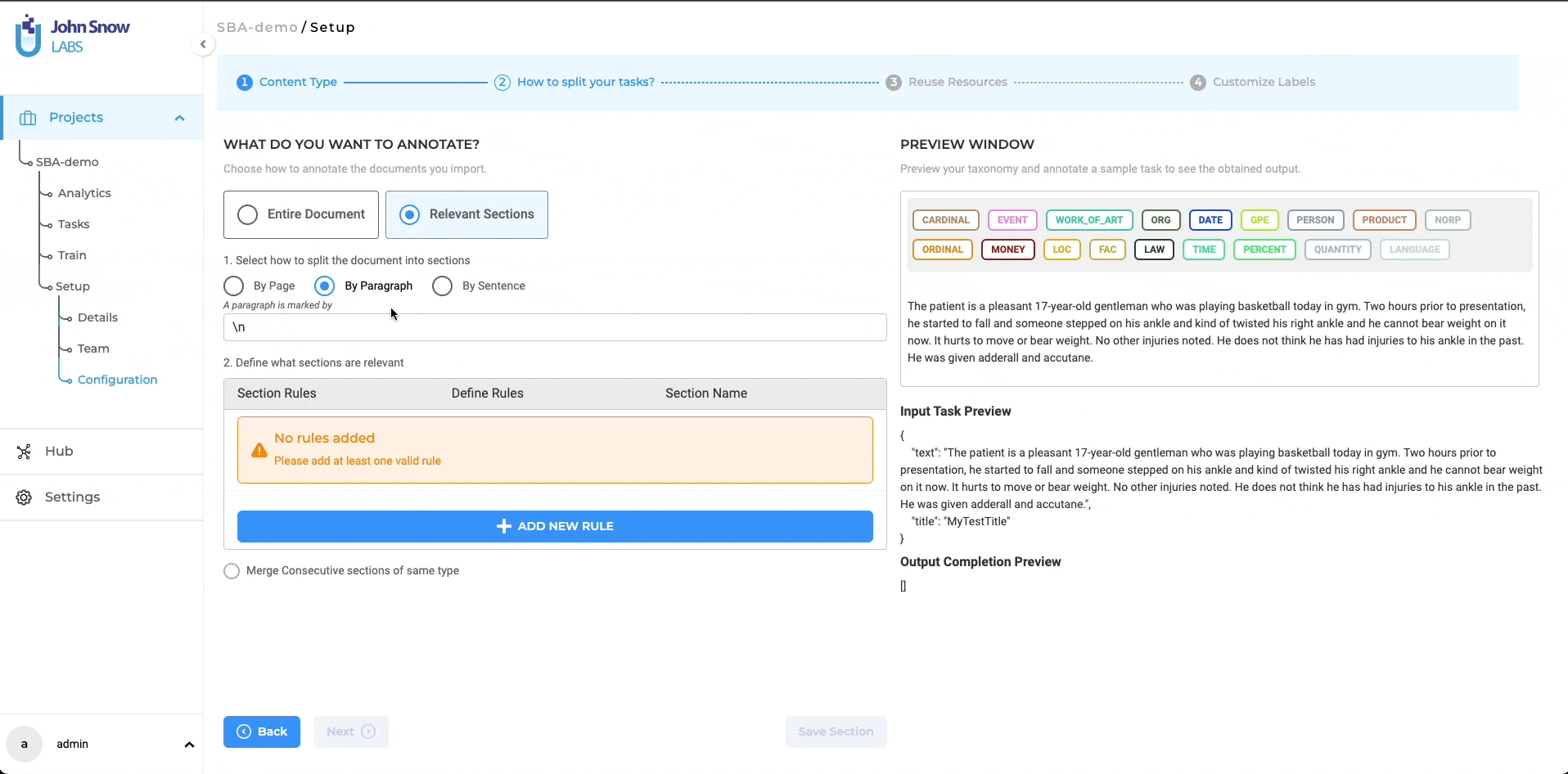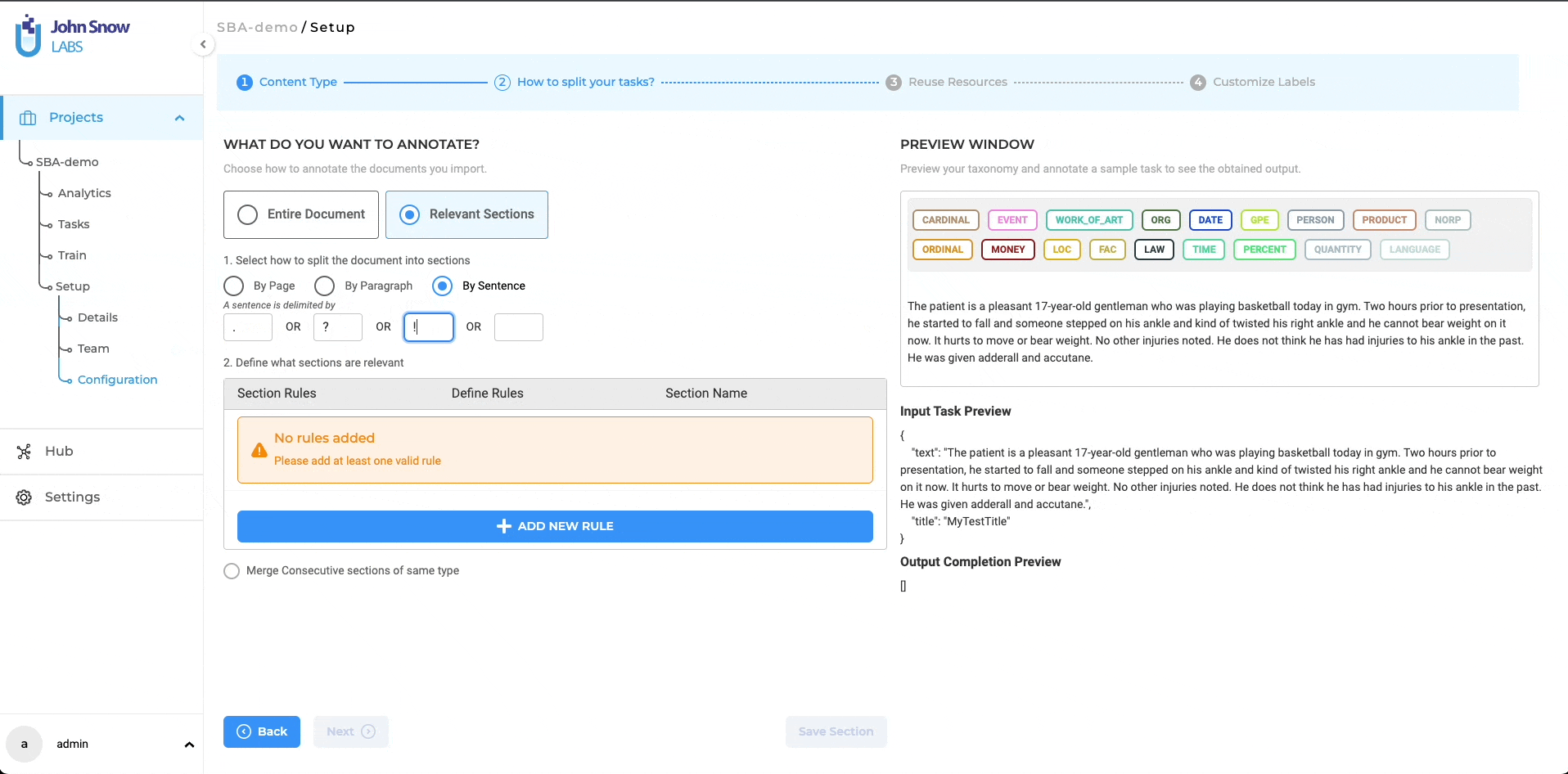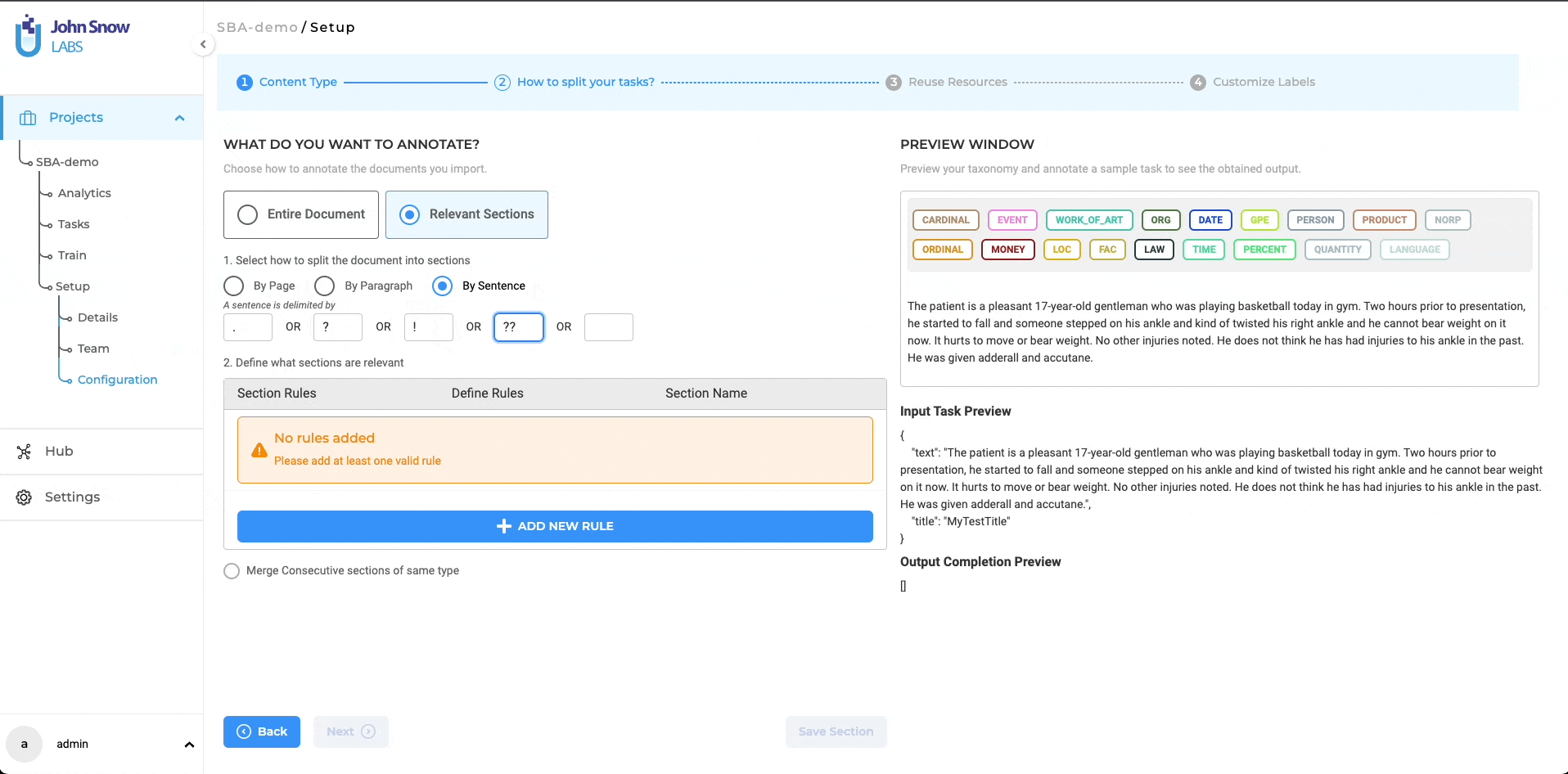
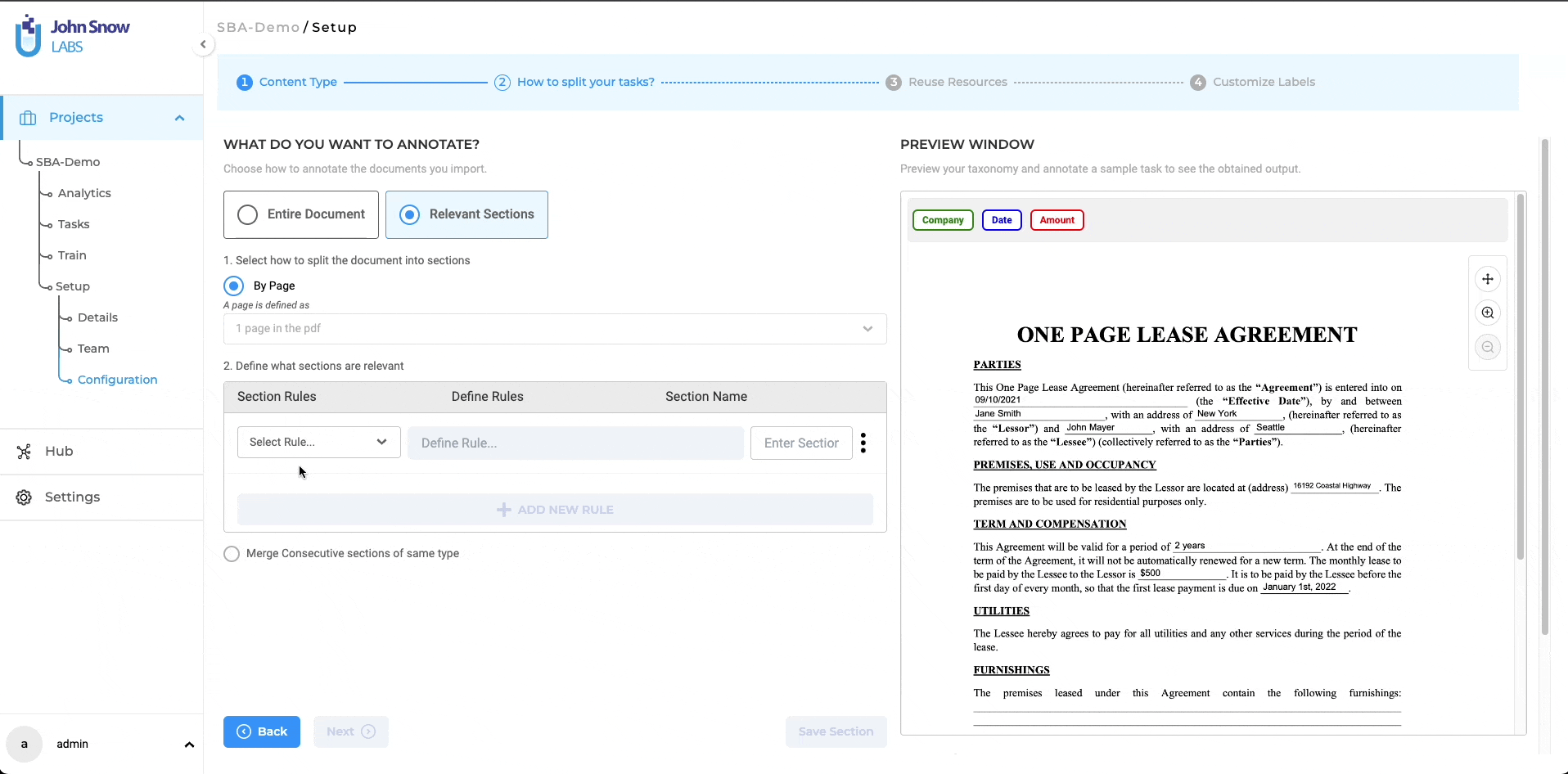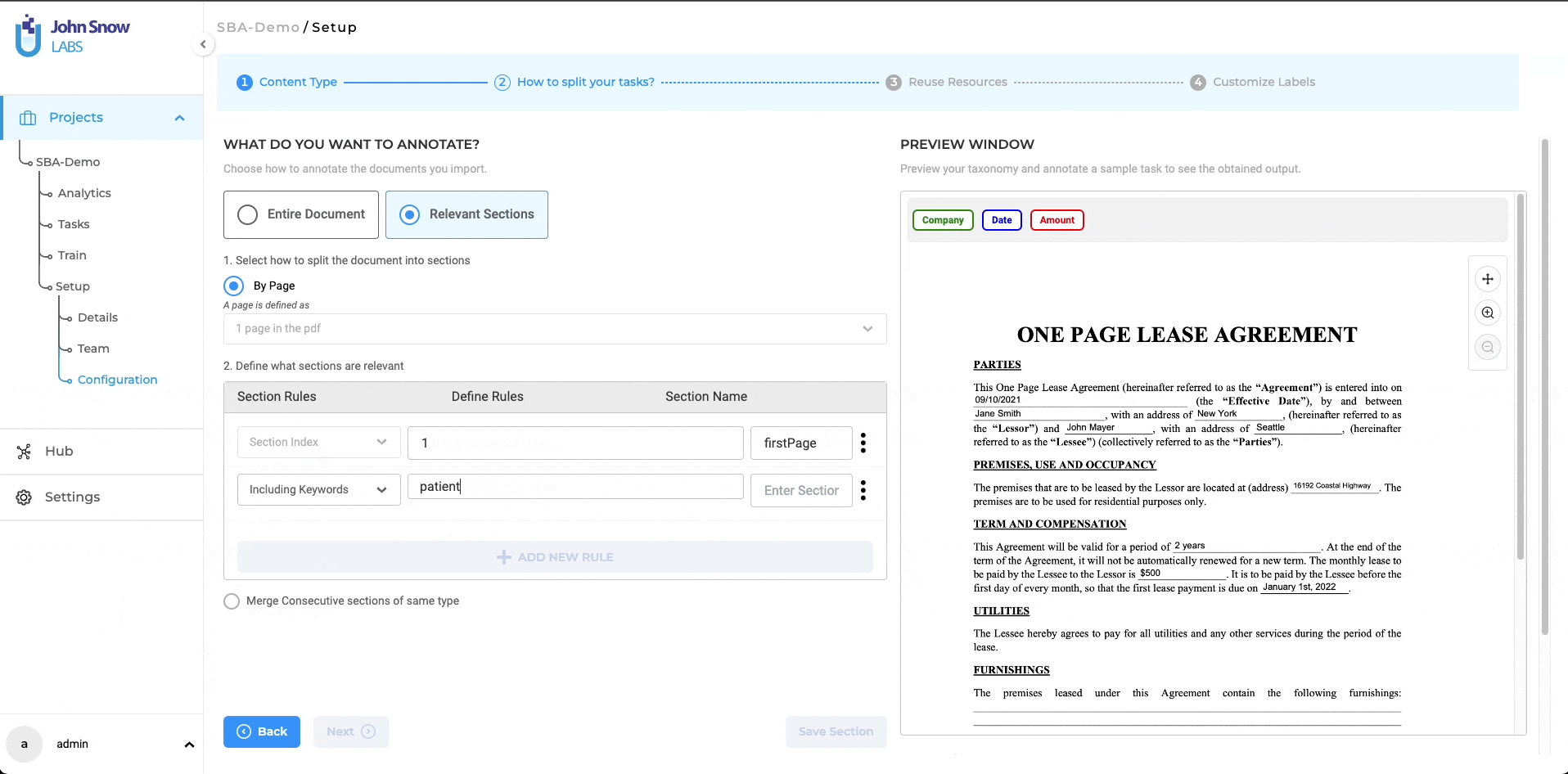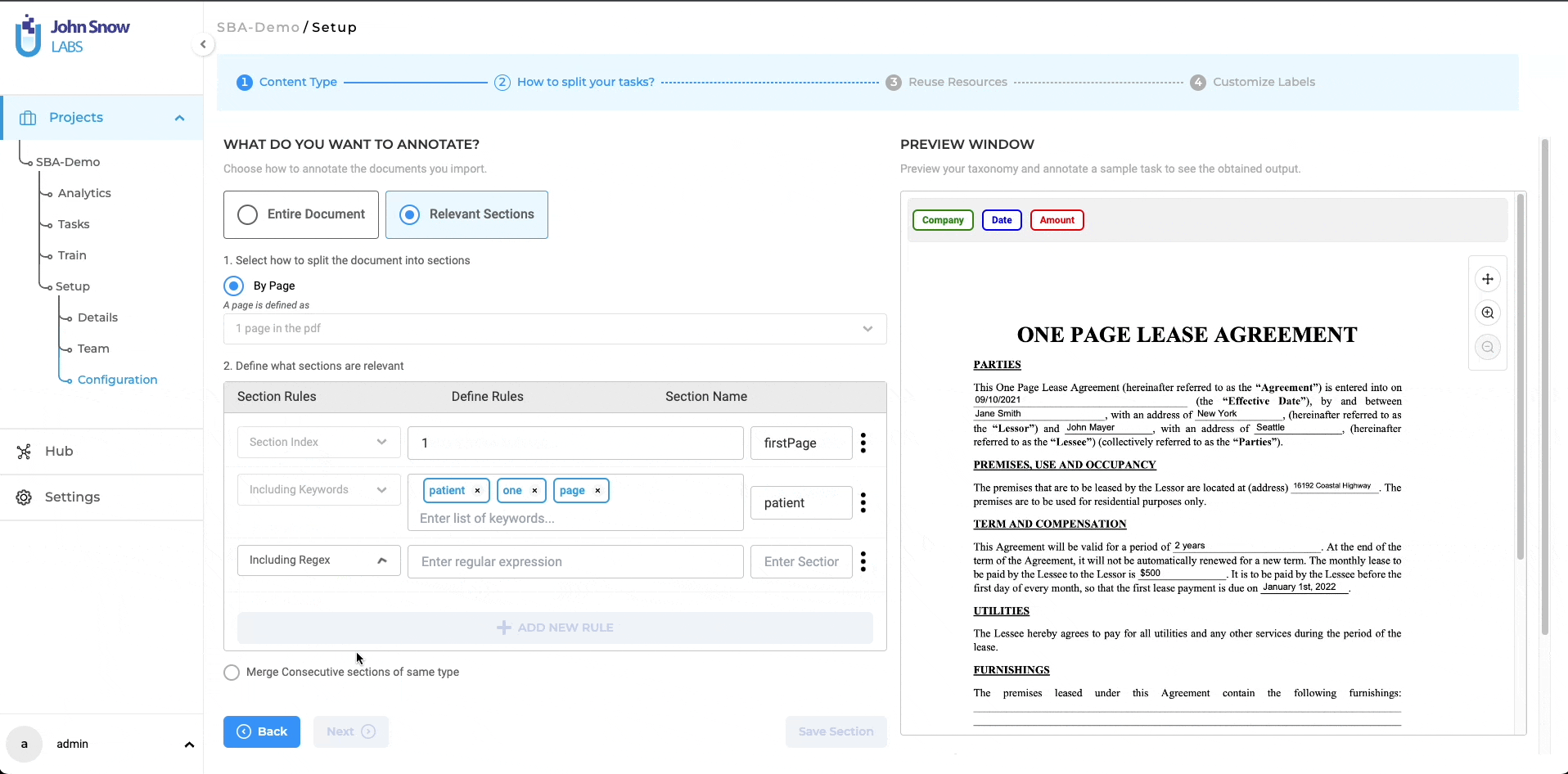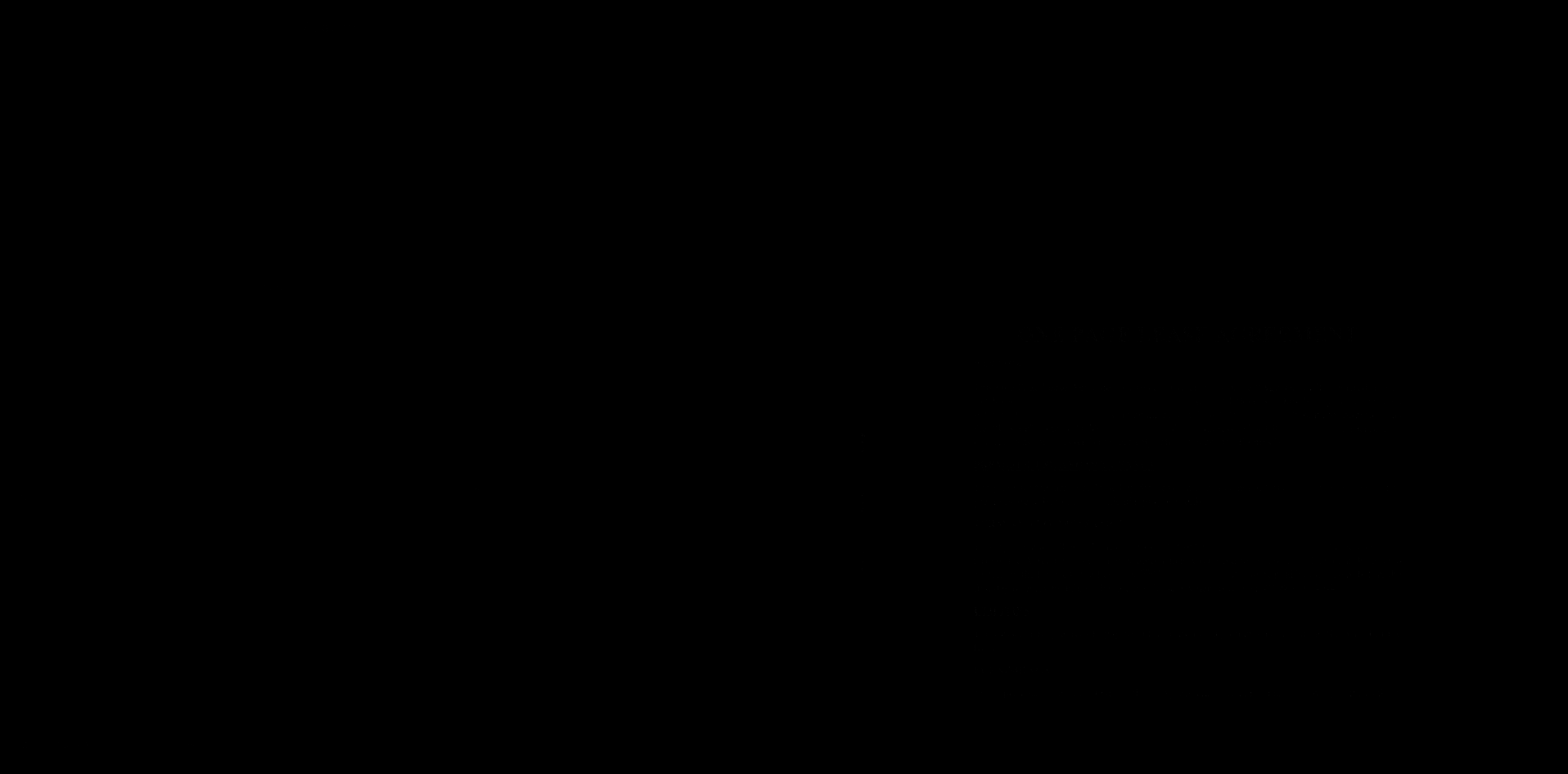
The project definition wizard introduces the task-splitting feature as an independent step, following the content type definition. In this second step of the project definition, users can opt for annotating the entire task at hand by choosing the “Entire Document” option or annotating only the relevant sections by choosing the “Relevant Sections” option. Three methods are available for splitting your tasks:
Split by Page: In text projects, a page is delineated by a specific character count. Users will find a dropdown menu featuring the same two default options as seen in the annotation screen for identifying a page: 1800 and 3600 characters. For Visual NER projects, a page represents a single page in the PDF document or an image. The page boundaries are automatically established, eliminating the need for further user inputs.
Split by Paragraph: Text tasks can be divided into paragraphs by using a dynamic regex such as “\n”. Custom regex expressions are also supported and can be defined to adapt the task splitting to the particularities of your documents.
Split by Sentence: This selection enables users to partition text documents into individual sentences, using single or multiple delimiters. The full-stop sign ‘.’ is the default delimiter used to identify sentence boundaries. Since a sentence may end with various delimiters. users have the flexibility to include multiple delimiters for sentence segmentation.
IMPORTANT REMARKS:
- The Split by Paragraph and Split by Sentence options are not applicable for Visual NER projects.
-
Section Based annotations cannot be enabled for pre-existing projects with annotated tasks or any project with tasks already in progress.
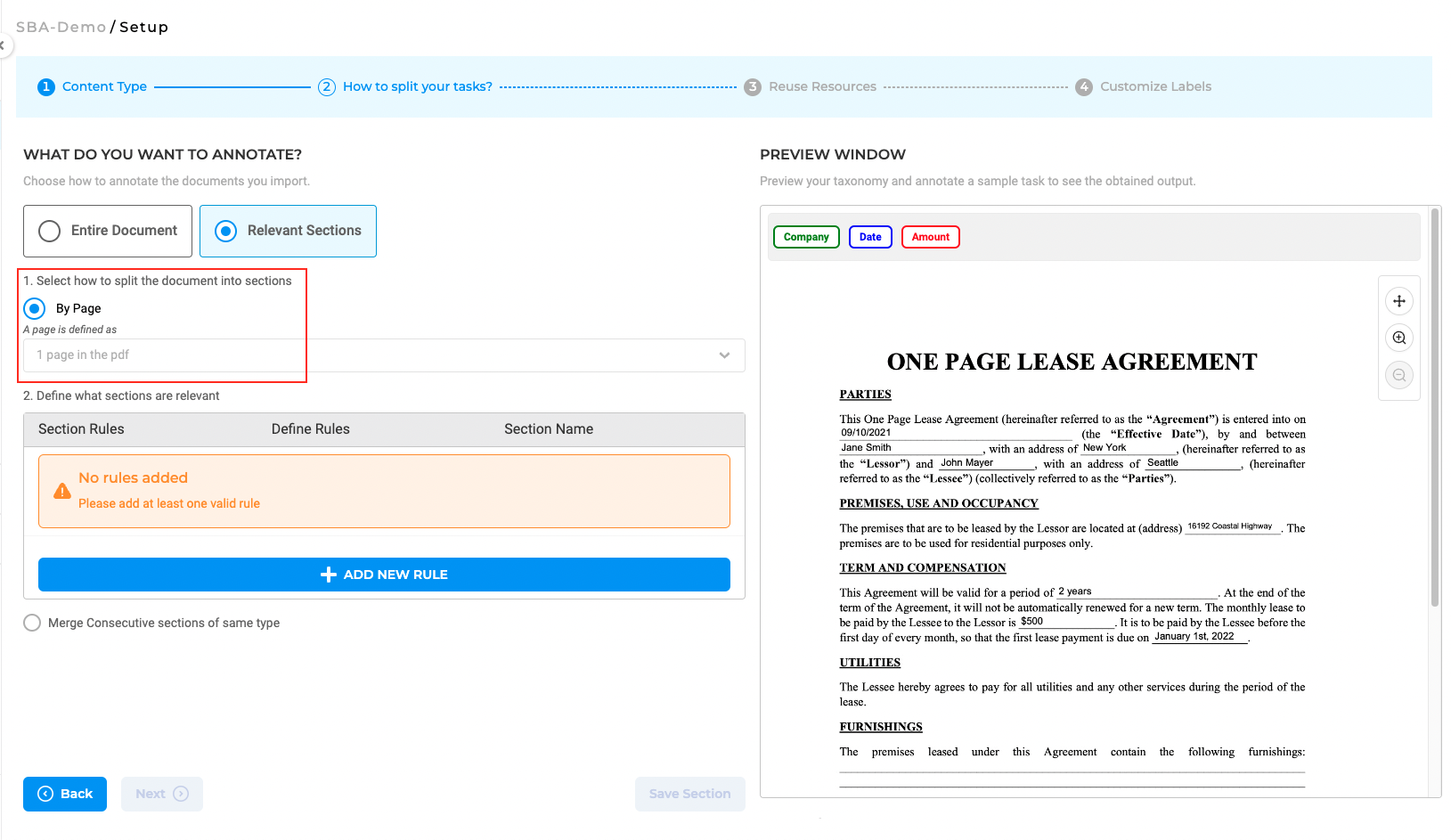
What Makes a Section Relevant?
After enabling the “Relevant Sections” feature and selecting a method to split documents into smaller parts (either by page, paragraph, or sentence), users can proceed to define the rules for identifying the relevant sections they want to work on. Only the sections that match the added section rules will be considered relevant.
Each section has a name that can be linked to the taxonomy elements (NER, assertion, or classification labels) that apply to that specific section. As such, all taxonomy elements that do not apply to section A, for instance, will be hidden on the annotation screen when section A is active or selected, making it easier for human users to check preannotations or define new annotations. Four types of rules can be combined to identify relevant sections:
Index-Based Rules
The section index refers to the crt. number of a section in the ordered list of sections created for a task. Index values are positive or negative integers, and can be specified in various formats. For example, you can define a sequence of integers such as 4, 5, 9 for the fourth, fifth and ninth sections, a range of values such as 1-10 to include all values from 1 to 10 or a negative value -1 to denote the last section in the task.
Keyword-Based Rules
Keywords can be used to mark a section as relevant. Each keyword can be a single word or a phrase consisting of alphanumeric characters. Multiple keywords can be used by separating them with commas (“,”). All sections containing the specified (list of) keywords will be considered relevant.
Regex-Based Rules:
Regex (regular expressions) can also be used to identify relevant sections. If a match is found within the document based on the provided regex, the corresponding page, paragraph, or sentence will be considered relevant.
Classifier-Based Rules:
Identification of relevant sections can also be done using pre-trained classifier models. Users can select one classifier from the available ones (downloaded or trained within NLP Lab) and pick the classes considered relevant for the current project. Those will be associated to a section name. Multiple relevant sections can be created with the same classifier. Please note that only one classifier can be used for section classification as part of one project. Saving this rule will deploy a classifier server, which can be viewed on the Cluster page. Licensed classifiers require a free valid license to run, and the deployment of a classifier is subject to the availability of server capacity.
Merge Consecutive Sections for Simplified Workflows:
Successive sections with the same name can be merged into one section. This feature is available by checking the corresponding option below the section definition widget. This simplifies the annotation process by grouping together neighboring sections with the same name for which the same taxonomy applies.
 )
)
IMPORTANT REMARKS:
For Visual NER projects, the rules for defining relevant sections are limited to index, keywords, and regex.
Section Specific Taxonomies
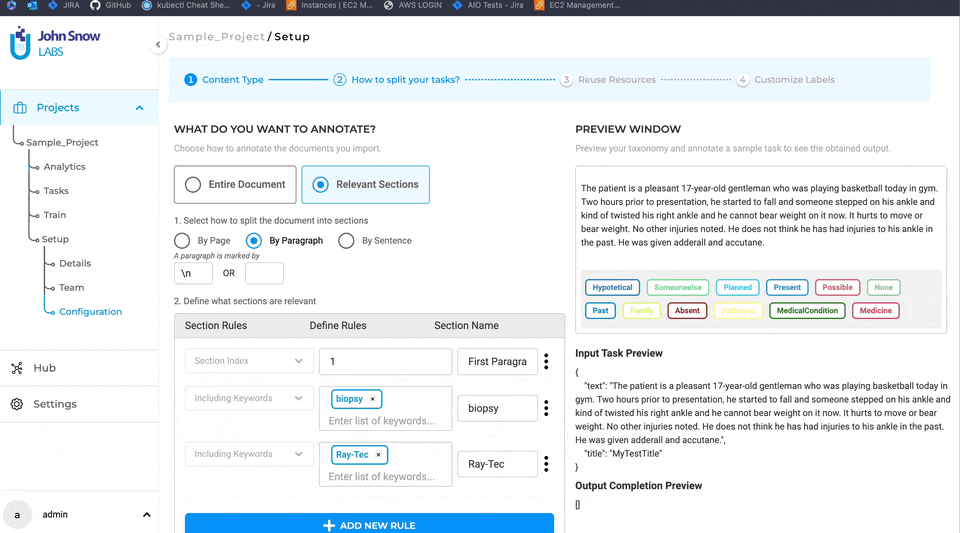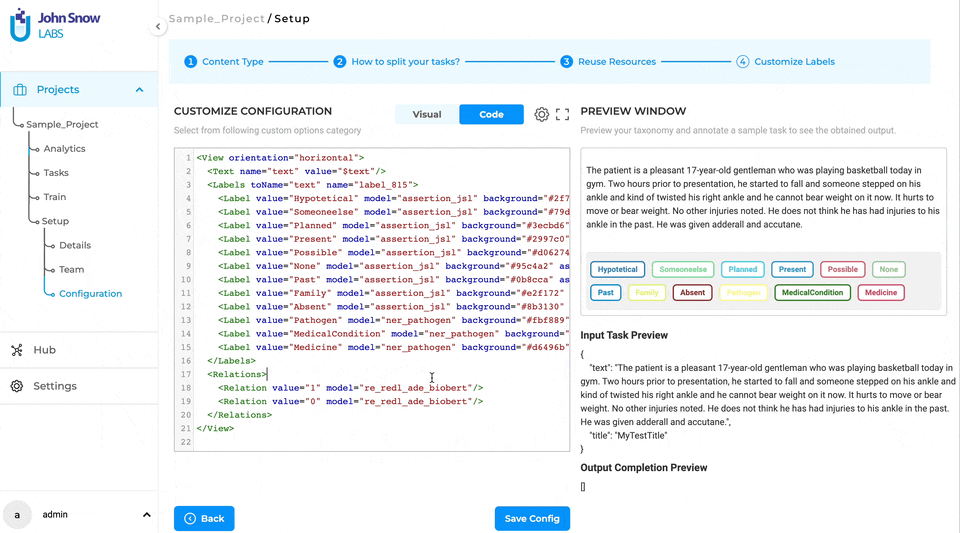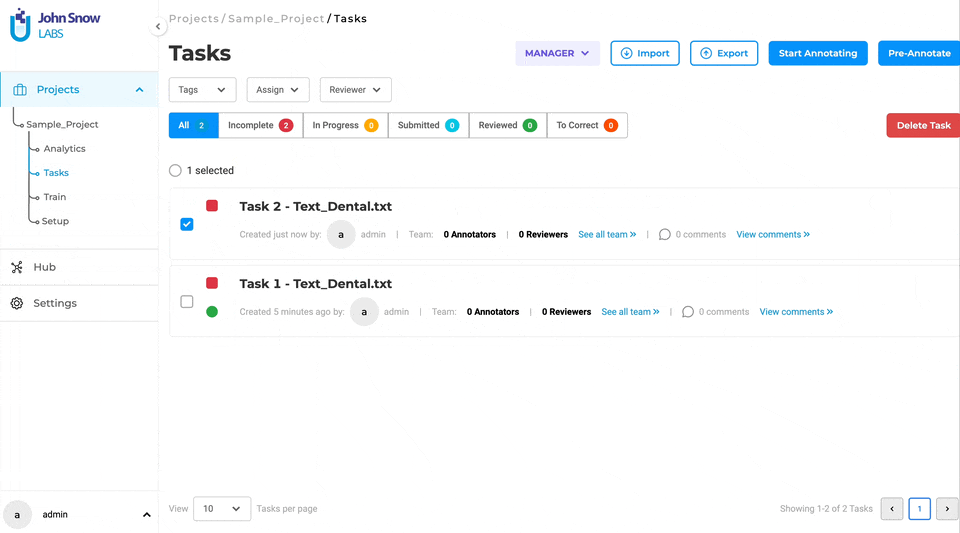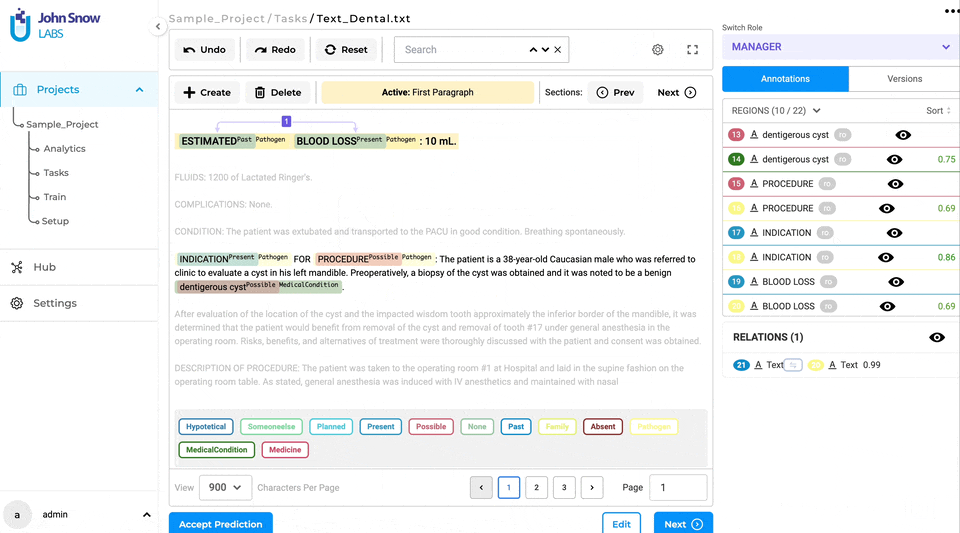
The section-based annotation options provide users with the flexibility to customize and configure the labels and choices that are displayed in specific sections. This setup can be conveniently accomplished via the project configuration page, which presents a visual mode for label customization.
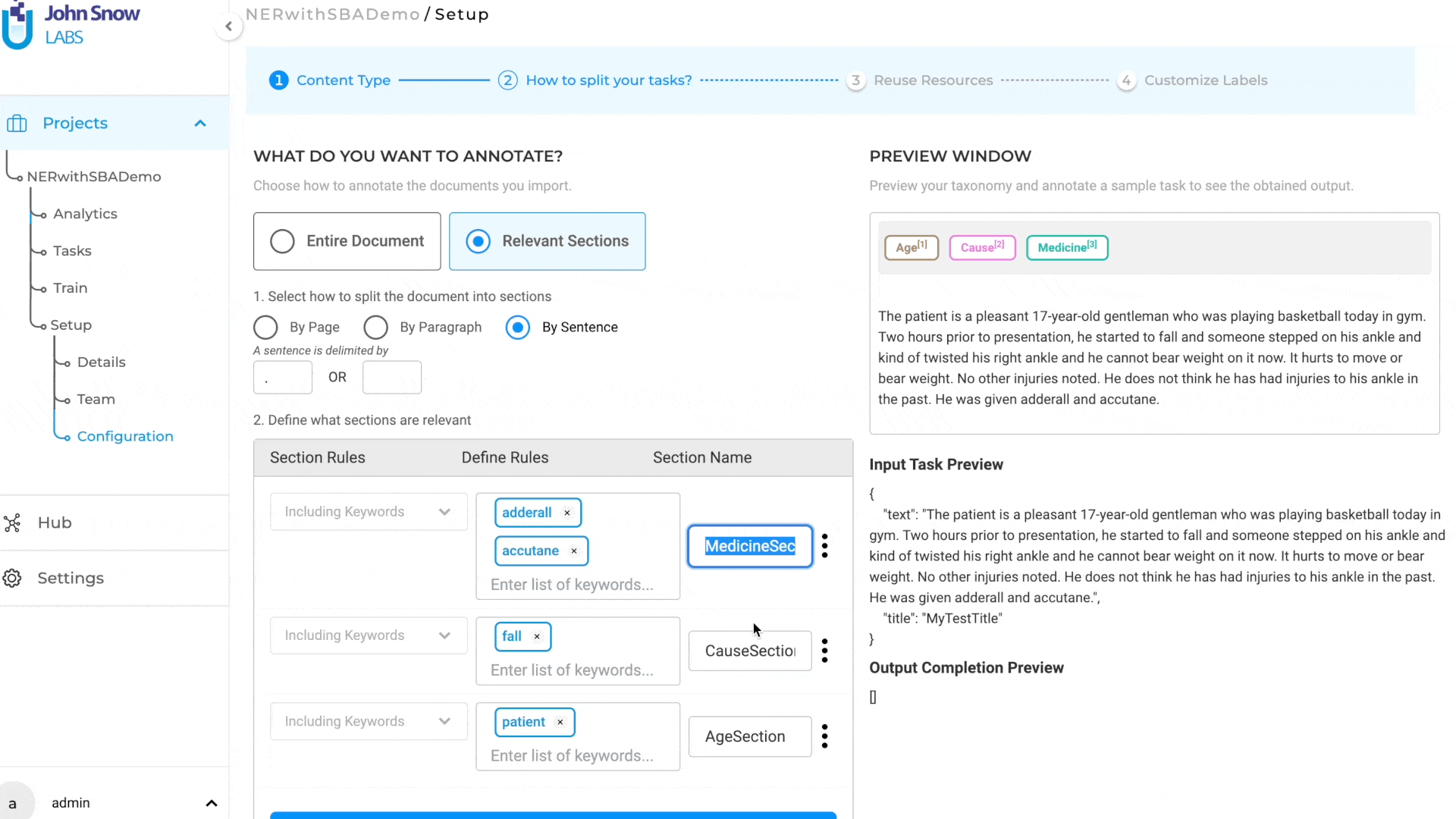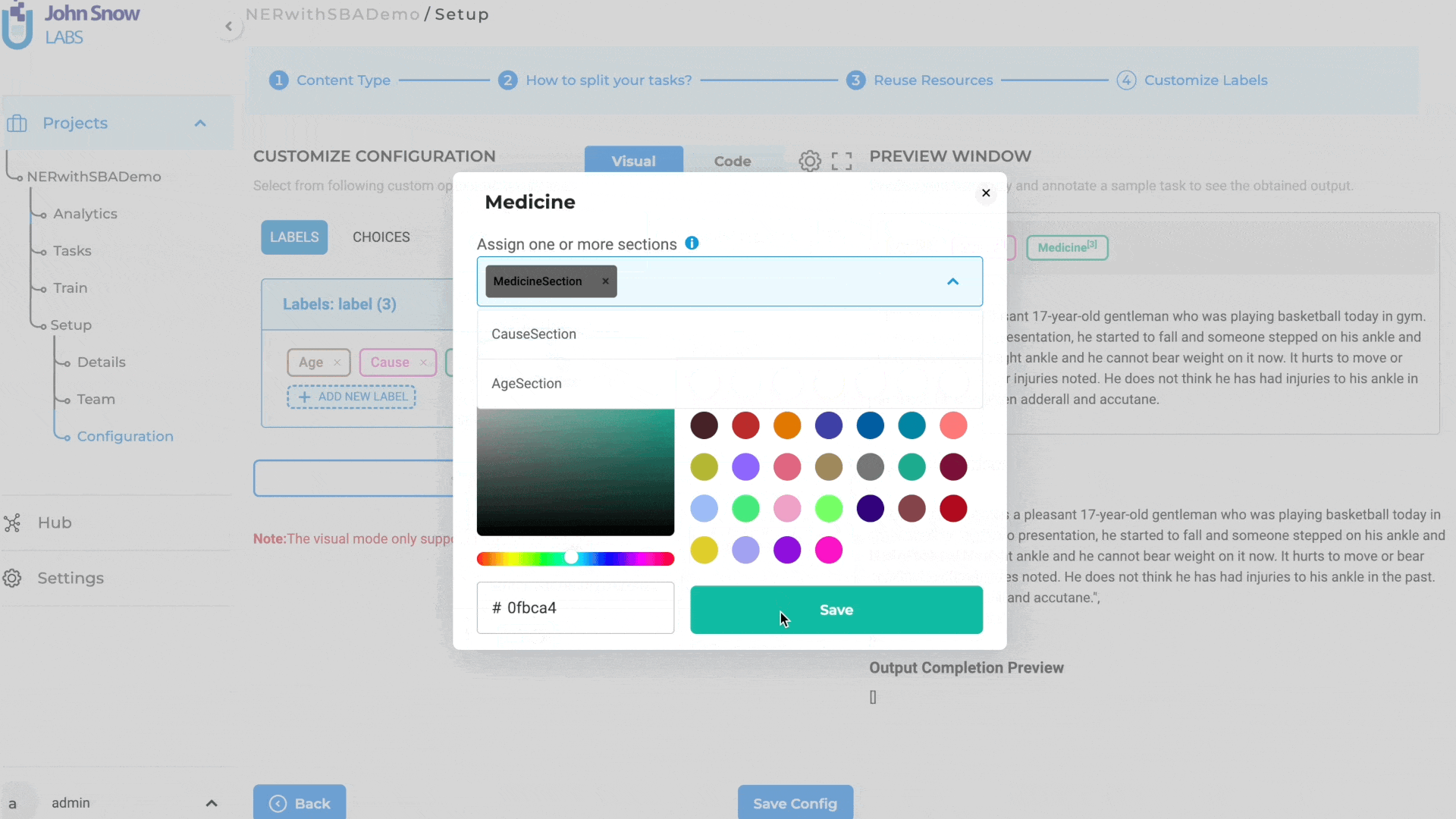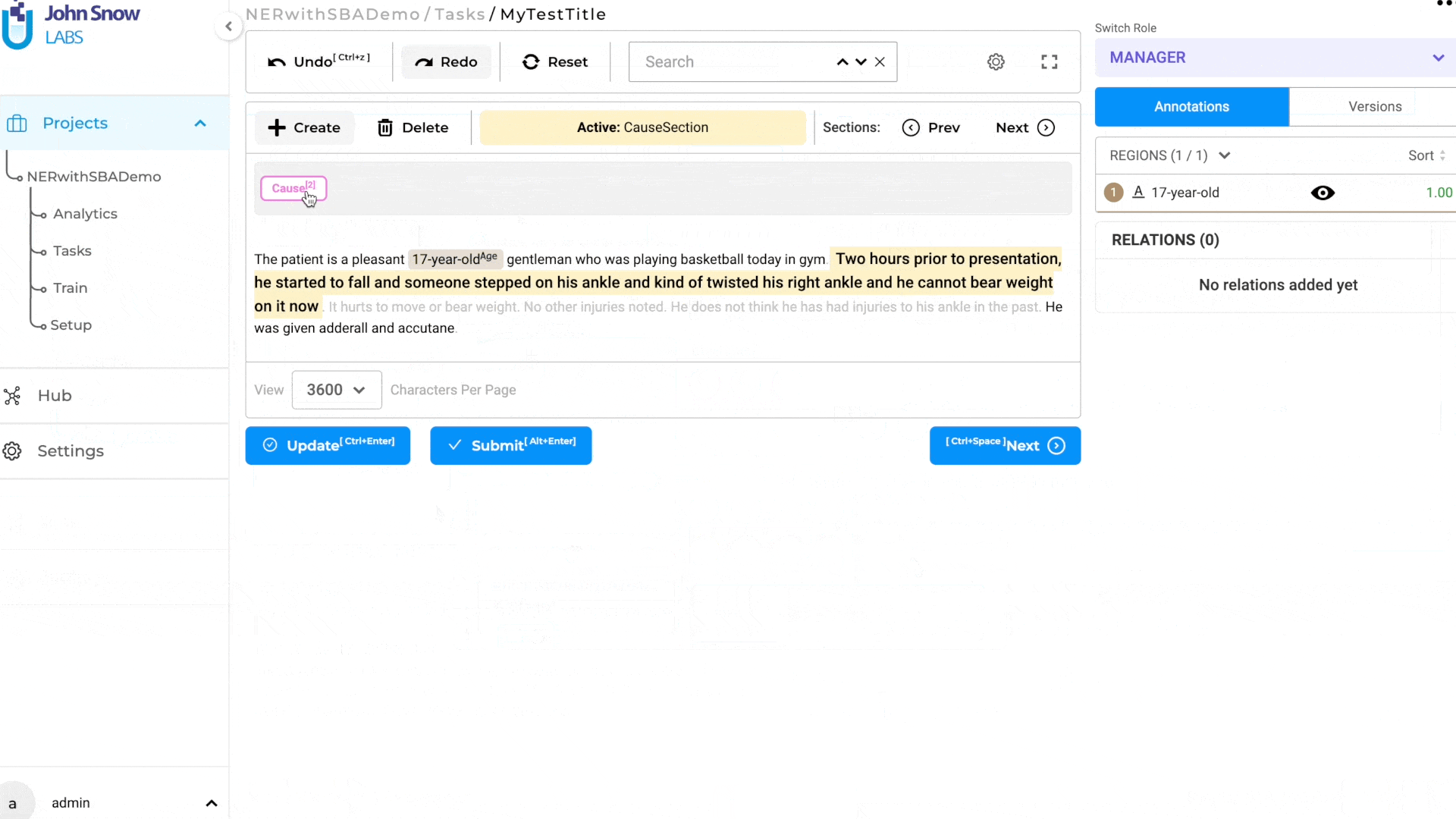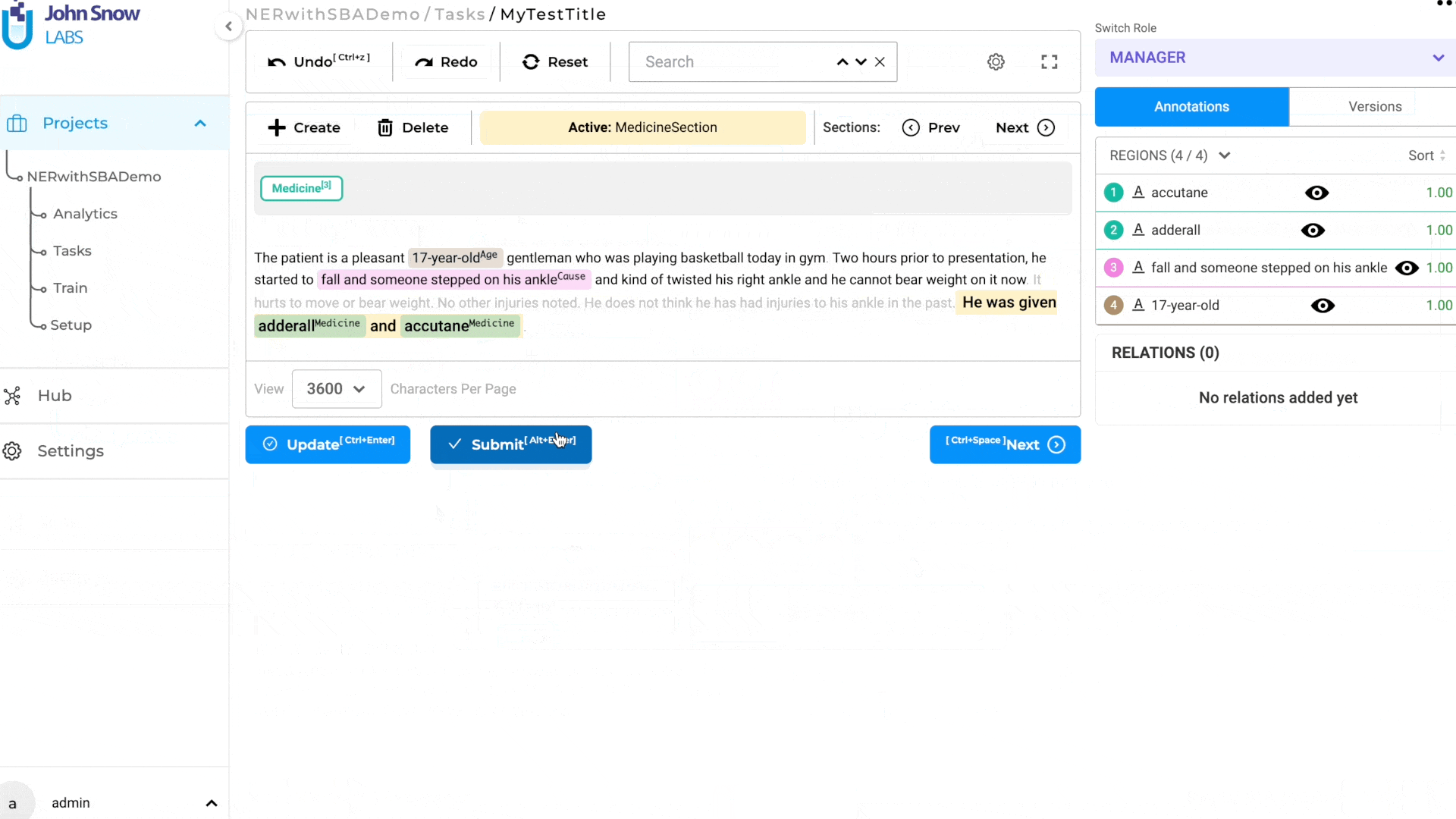
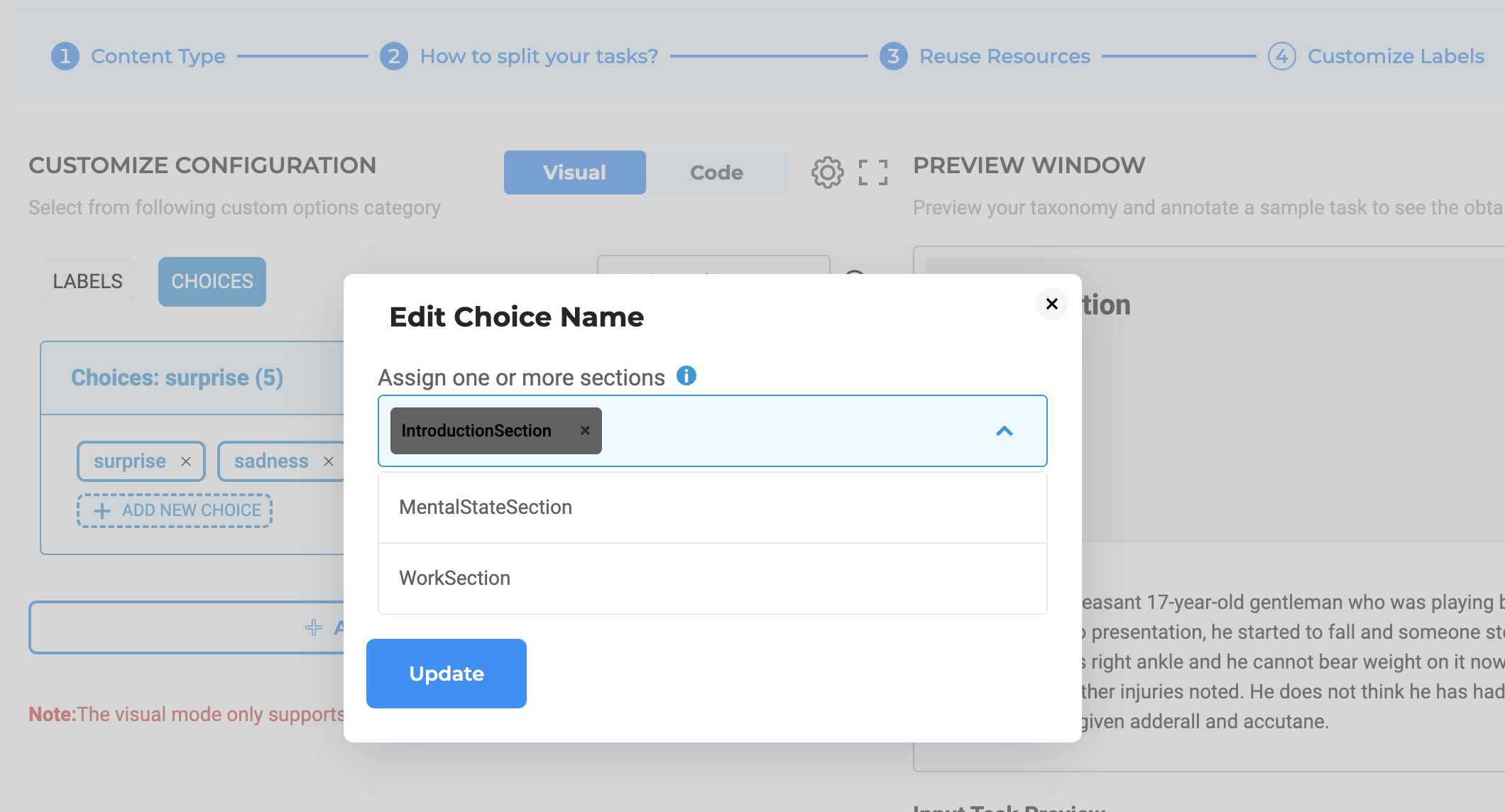
In the case of Named Entity Recognition (NER) labels, users can simply click on individual labels and choose the specific sections where they want the label to be visible. By doing so, users have the ability to define the sections within the task where each NER label should appear, ensuring that the annotation is precise and applicable to the intended sections.
Similarly, for choices, users can navigate to the three-dot menu, typically located next to each choice name. By selecting this menu, users can access the configuration settings to designate the relevant sections where the particular choice should be displayed. This feature allows users to tailor the choices available for annotation in specific sections, making the annotation process more precise and efficient.
By providing the ability to configure labels and choices at the section level, users can ensure that their annotation efforts are focused on the most relevant parts of the text. This ensures that the annotation process is efficient, saving valuable time and resources. Ultimately, this level of customization empowers users to create high-quality annotations tailored to their specific tasks and objectives.
Pre-annotation Focused on Relevant Sections
In Section-Based Annotation projects, users can mix DL models, rules, and prompts for pre-annotating relevant sections according to their specific taxonomies. By splitting tasks into relevant sections, pre-annotation leverages the trained/deployed model to generate predictions focusing exclusively on those smaller chunks of text. This significantly streamlines the pre-annotation workflow, enabling users to leverage the precision and efficiency of predictions derived from DL models, LLM prompts, and rules.
Also when leveraging prompts-based annotation it is important to consider the context limitations. The LLMs can only process a certain number of tokens (words or characters, depending on the model) at a time. For instance, for OpenAI’s GPT-3, the maximum limit is approximately 6500 words, while the context length of GPT-4 is limited to approximately 25,000 words. There is also a version that can handle up to 50 pages of text, but the more context you send to LLM the higher the costs.
If the document you are trying to preannotate is larger than the LLM’s limit, you will need to break it down into smaller sections. This is where section-based annotation becomes particularly useful. It allows you to focus on the most relevant parts of the document without exceeding the token limit.
It’s also important to note that LLMs do not have a memory of previous requests. Therefore, the context that is sent for each request should contain all the necessary information for generating accurate predictions.
Model Training with Section-Level Annotations
In projects that support Section-Based Annotation, each section is treated as an individual document during the training process. This means that the annotations contained within a given section, along with the section’s text, are provided to the training pipeline. By considering the specific content and context of the relevant sections, the training process becomes more targeted and accurate, resulting in improved model performance.
This advanced training approach allows for a more focused training experience by excluding irrelevant sections and solely focusing on the sections that contain annotations. Training specifically on these relevant sections optimizes the training process, resulting in improved pre-annotation efficiency and accuracy. This targeted approach enhances the precision and overall accuracy of trained models.
Manual Annotation of Relevant Sections
Start from the Default Relevant Sections
When importing a new task, the relevant sections are automatically created based on the rules defined on the section configuration page. This division allows the annotator to focus on annotating the relevant sections individually. By breaking down the task into manageable sections, the annotation process becomes more focused and efficient.
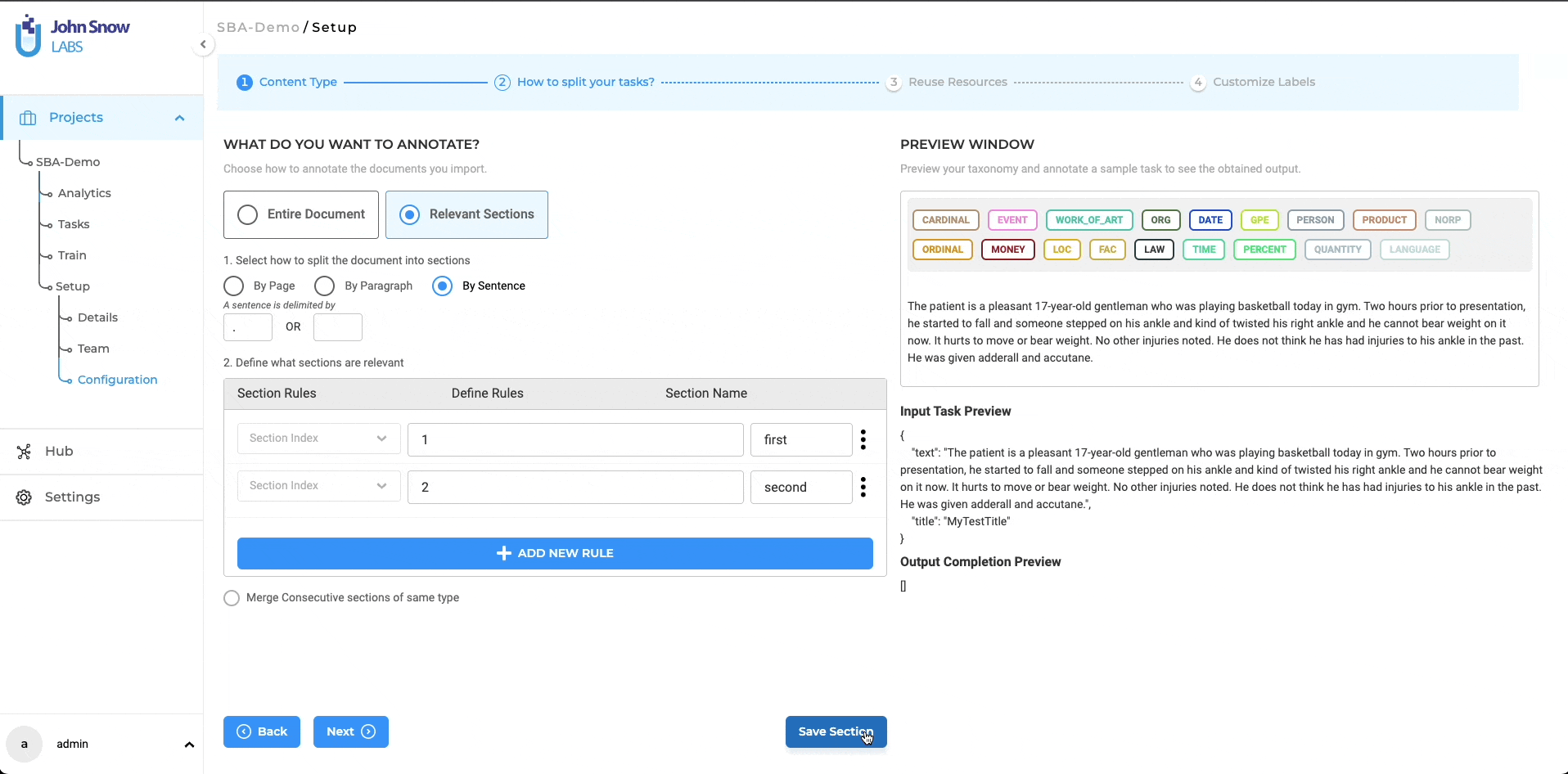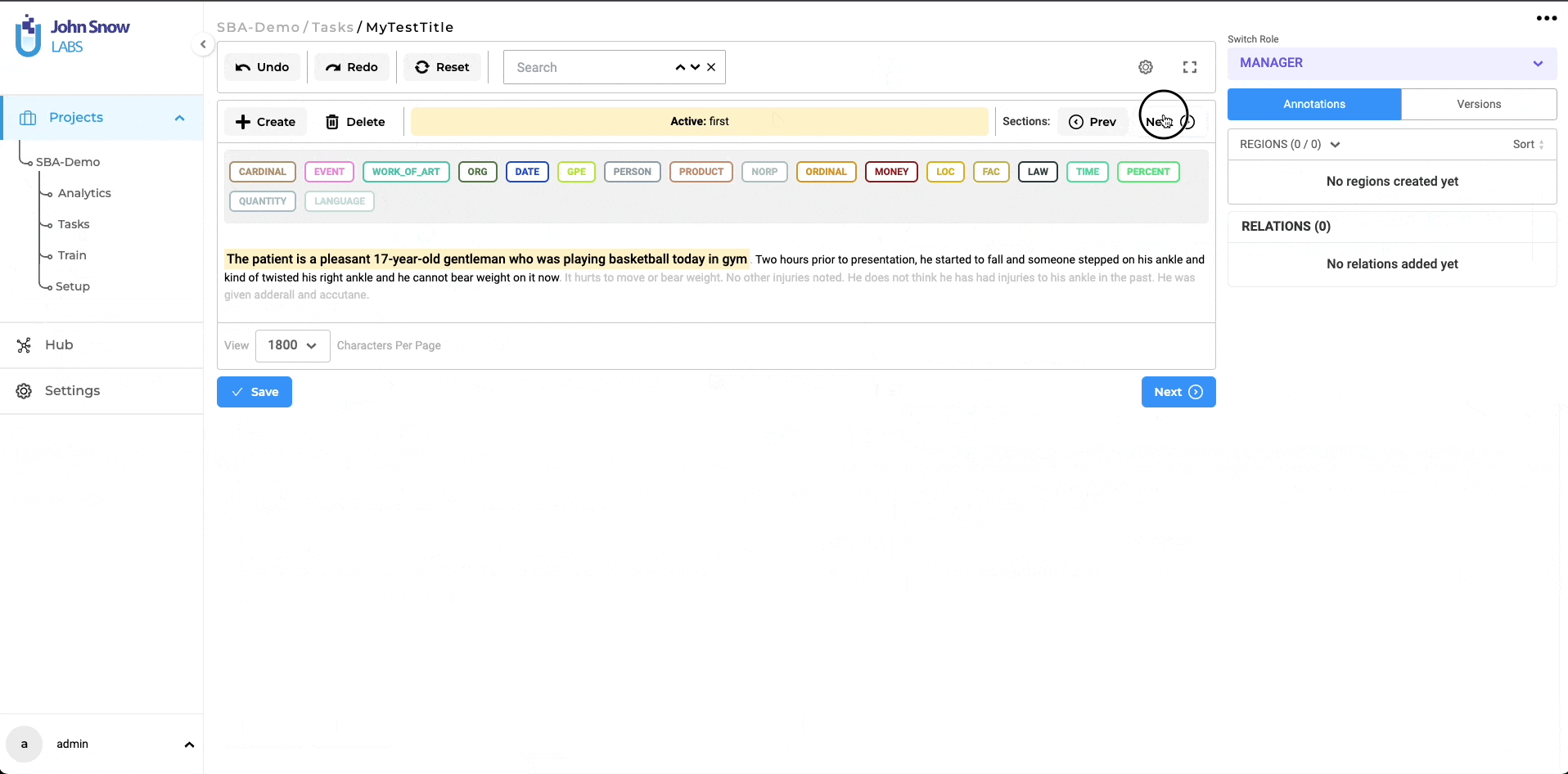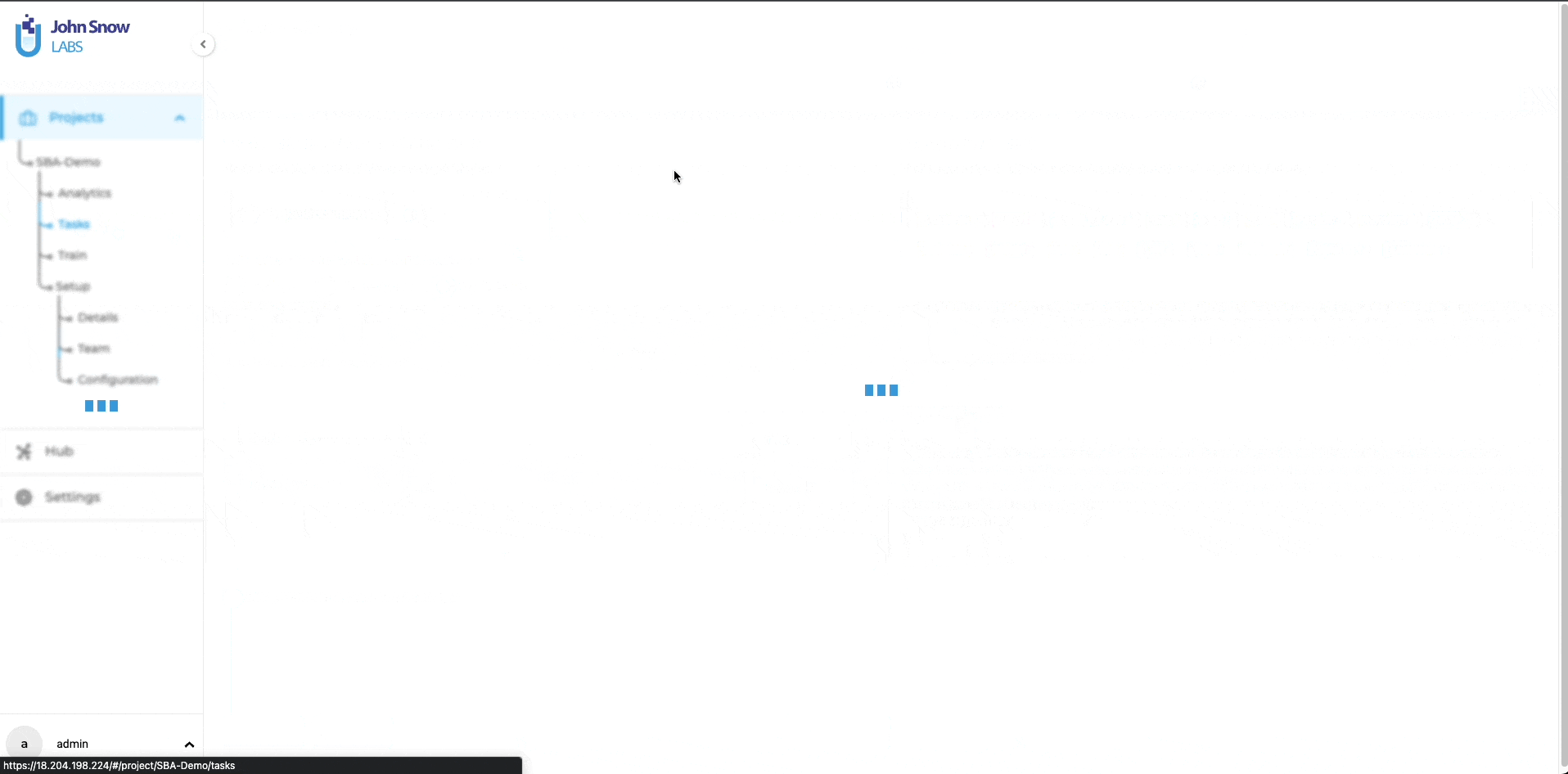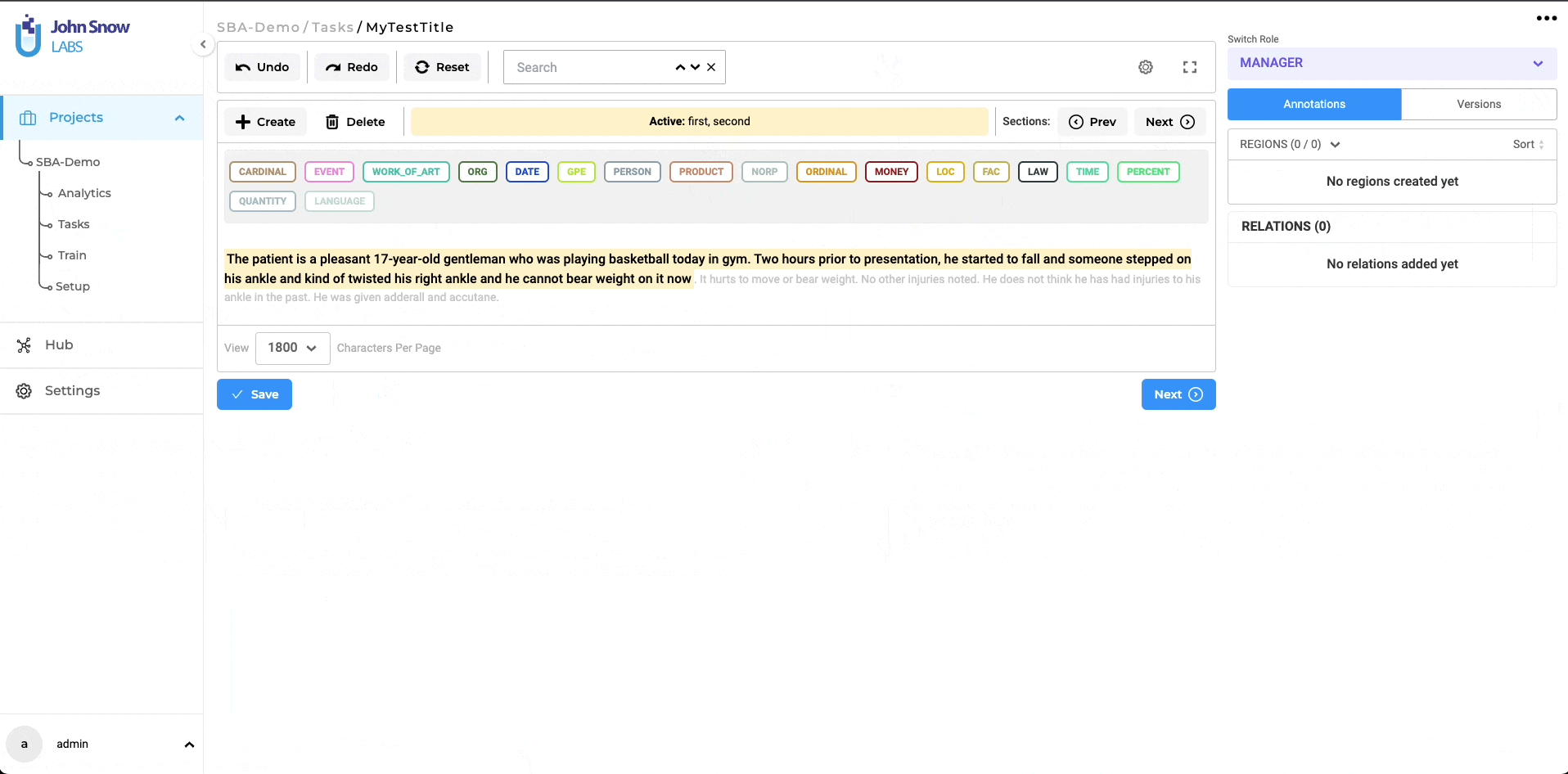
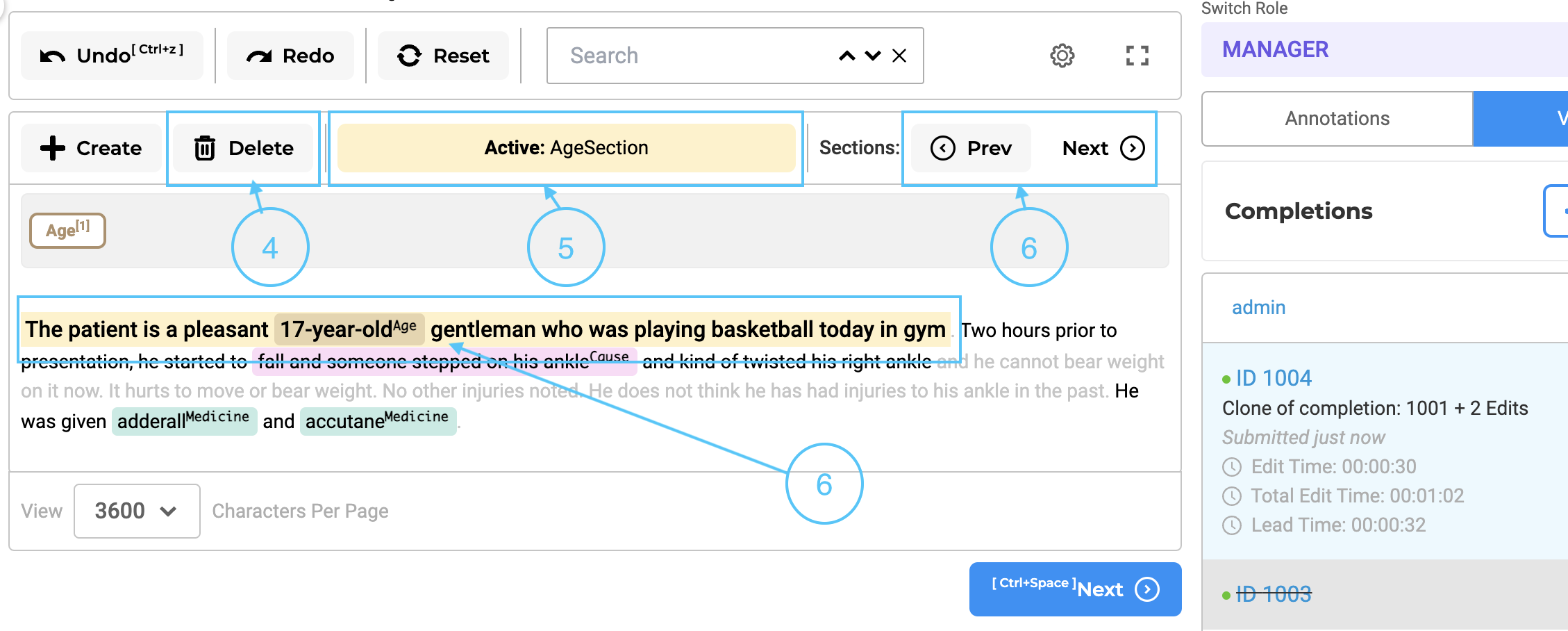
When a task is opened in the annotation screen, a new completion is generated by default, based on the automatically detected sections. The first relevant section is active by default and shown as highlighted in the yellow background (see item 7 on the below image) on the UI. Additionally, the name of the active section is displayed in the top bar (5), providing clear context to the user.
Manual Creation/Removal of Relevant Section
There may be occasions when the predefined rules do not accurately capture the necessary relevant sections. For such scenarios, the user has the option to manually select the required text regions within the document and add a new section using the ‘Create’ button located at the top of the annotation area (see item 2 in the below image). A pop-up window allows users to choose the section to which the selected region belongs. (see item 3 in the image below). This ensures that no relevant information is overlooked or omitted during the annotation process. The custom-created sections are specific to the completions created by each user, and it can be possible that different users will submit starred completions with different relevant sections for the same task. This type of situation should be discussed in Inter Annotator Agreement meetings and consensus should be reached on what defines a relevant section.
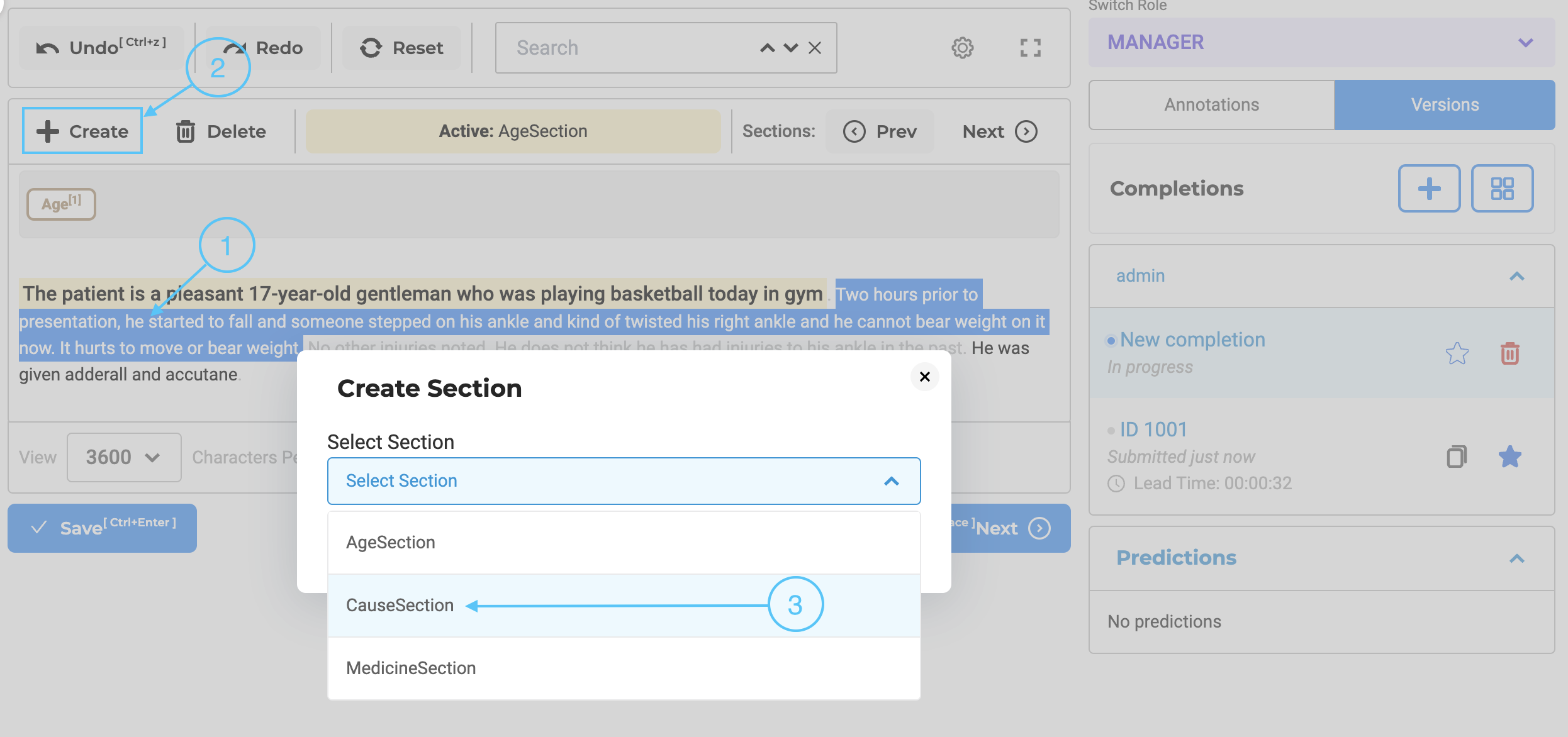
By incorporating both automated section generation based on configuration rules and the ability to manually create sections, the annotation system offers a comprehensive approach that balances convenience and customization. Annotators can annotate efficiently on the automatically detected sections, while also having the flexibility to modify or create sections manually when necessary. It is also possible to remove an existing section. For this, users can simply click on the delete button associated with that section (see item 4 on the above images).
Navigating Between Relevant sections
Users can easily navigate to relevant sections using the ‘Previous’ and ‘Next’ buttons. Clicking these navigation buttons moves the user’s view to the appropriate area where the relevant section is located. If the relevant section is on the next page, the display will automatically transition to that page, ensuring seamless access to the desired section.
Cloning Completions with Custom Sections
In section-based tasks, cloning a completion entails automatically duplicating the section as well as the associated annotations.
In other words, the process of copying completions ensures that the section structure, along with its corresponding annotations, is replicated in the new completion. This feature allows users to work on multiple iterations or variations of the task, each with its distinct relevant section, without losing any work - annotations, and labels - done in the original completion.
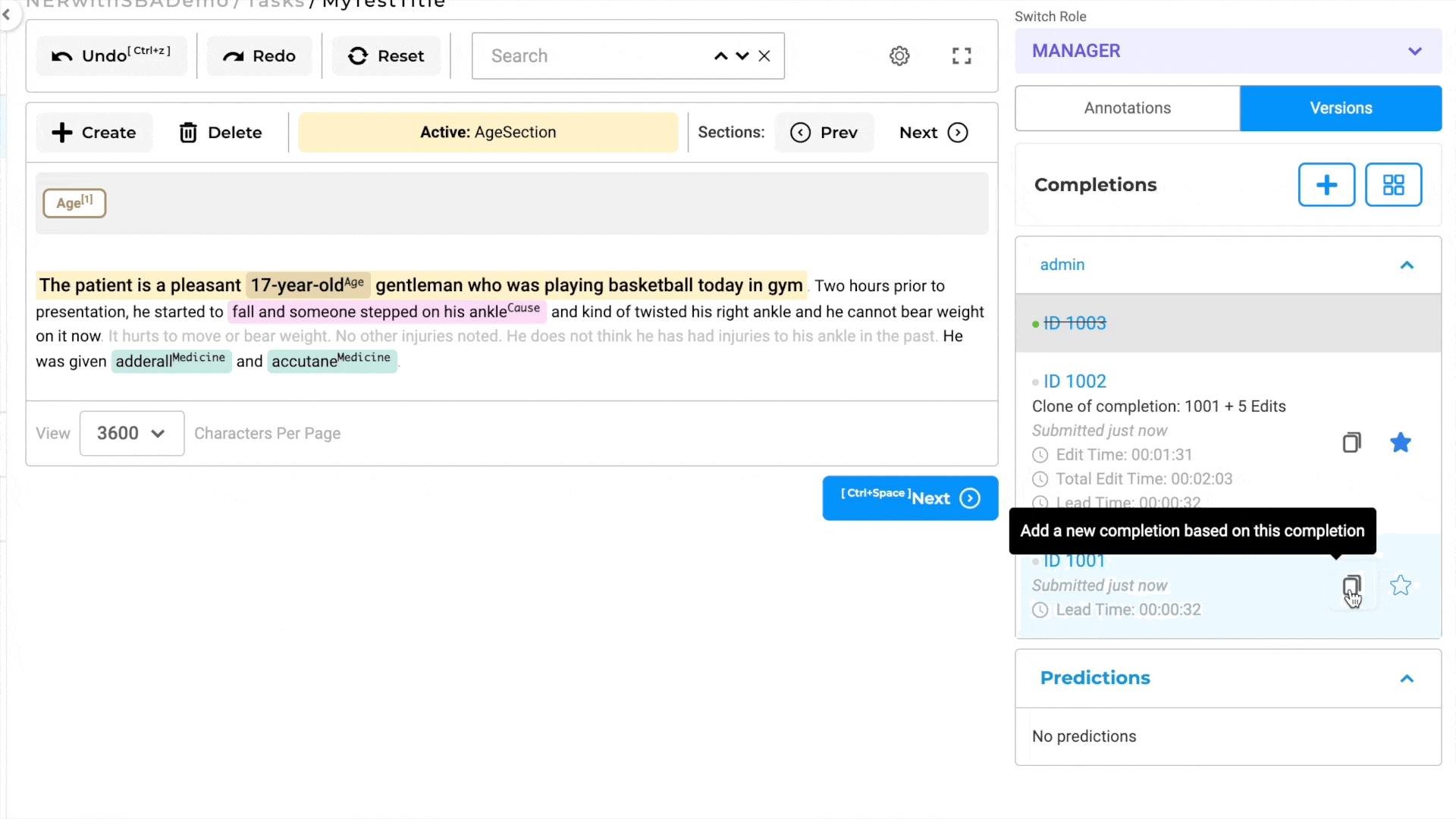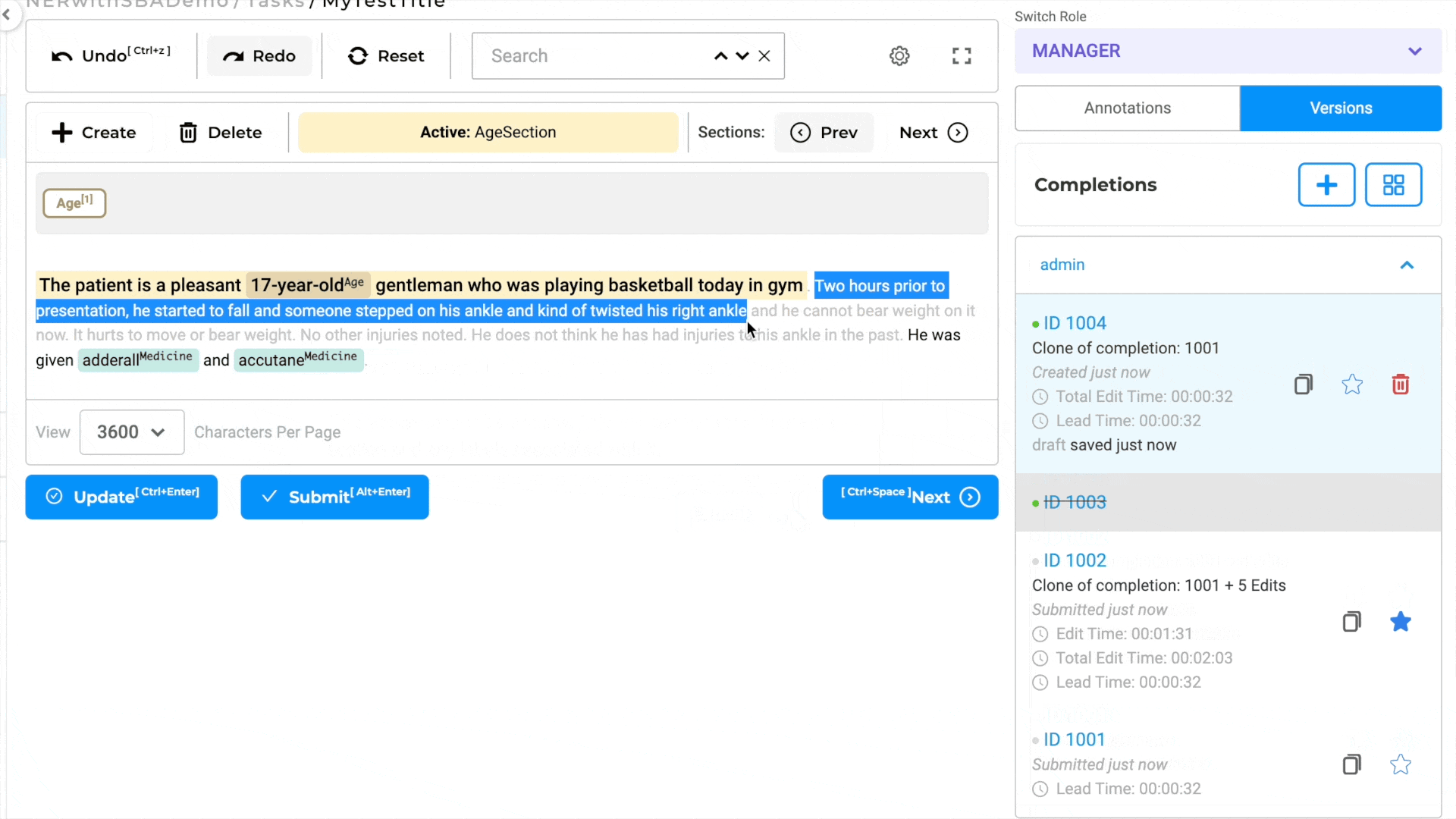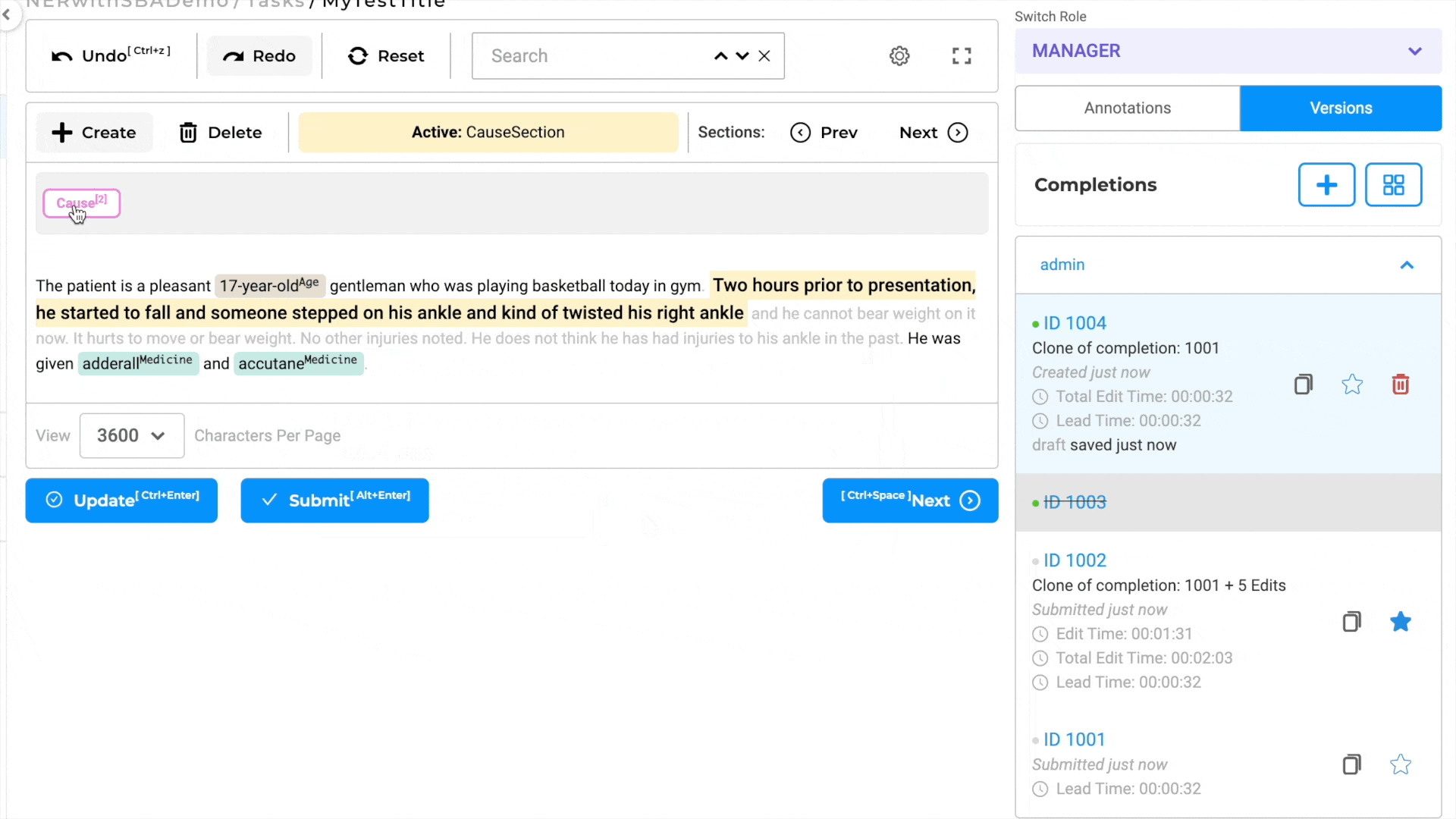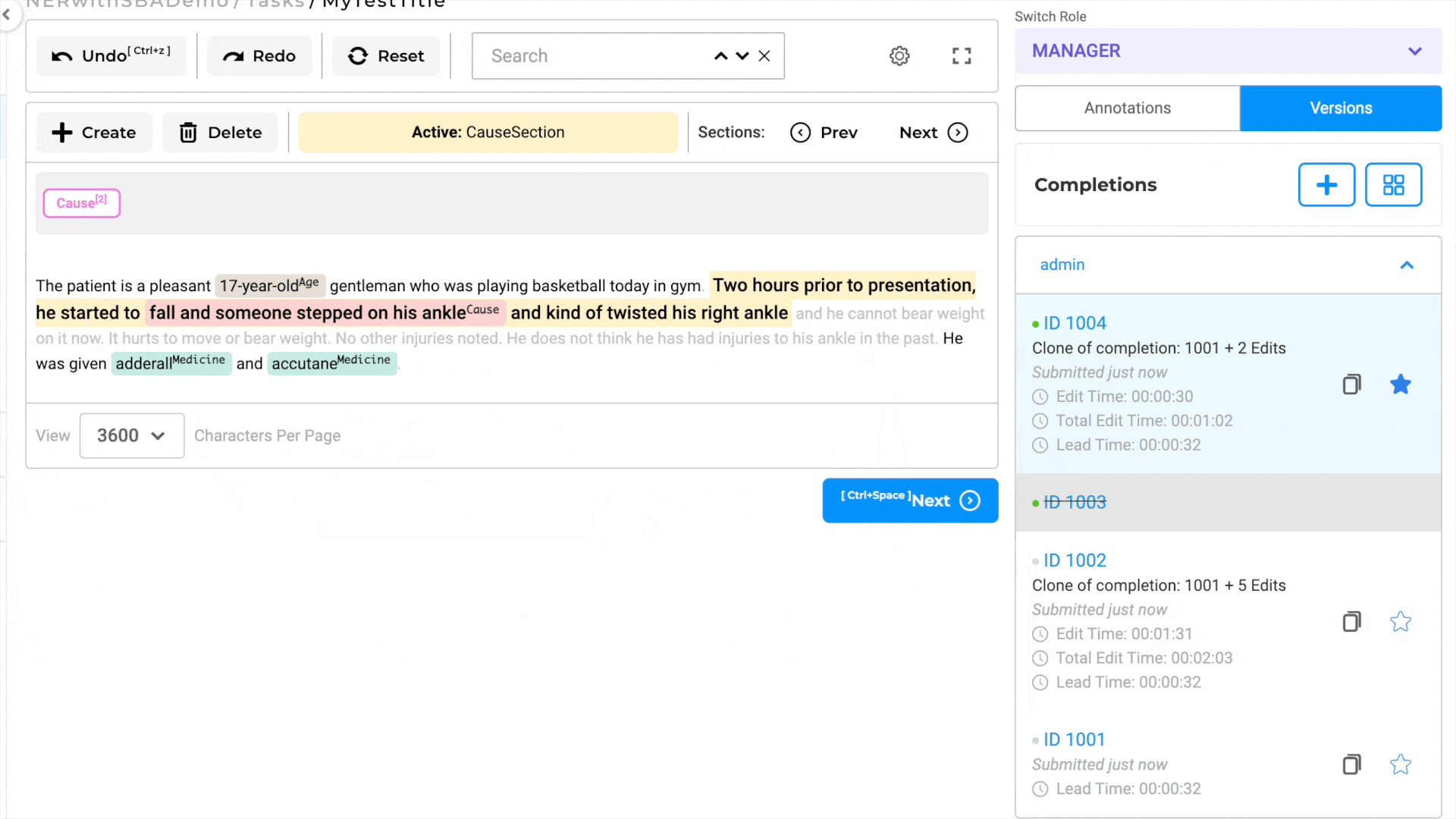
By supporting the duplication of completions while preserving the section-based context, the annotation system grants users the flexibility to modify and refine their work as needed. It enables users to submit different versions of completions, each with its unique relevant section, facilitating a more nuanced and specific analysis of the underlying data.
Creating New Completions
If there are multiple completions submitted by different annotators and the user decides to create a new completion from scratch, the relevant sections will be generated based on the rules that were initially set when the task was imported.
IMPORTANT REMARKS: Changes made to the section rules do not apply to existing imported tasks. The updated rules are only applied to newly imported tasks.
Versions
- 8.2.1
- 8.2.0
- 8.1.3
- 8.1.2
- 8.1.1
- 8.1.0
- 8.0.1
- 8.0.0
- 7.8.2
- 7.8.1
- 7.8
- 7.7
- 7.6.0
- 7.5.1
- 7.5.0
- 7.4.0
- 7.3.1
- 7.3.0
- 7.2.2
- 7.2.1
- 7.2.0
- 7.1.0
- 7.0.1
- 7.0.0
- 6.11.3
- 6.11.2
- 6.11.1
- 6.11.0
- 6.10.1
- 6.10.0
- 6.9.1
- 6.9.0
- 6.8.1
- 6.8.0
- 6.7.2
- 6.7.0
- 6.6.0
- 6.5.1
- 6.5.0
- 6.4.1
- 6.4.0
- 6.3.2
- 6.3.0
- 6.2.1
- 6.2.0
- 6.1.2
- 6.1.1
- 6.1.0
- 6.0.2
- 6.0.0
- 5.9.3
- 5.9.2
- 5.9.1
- 5.9.0
- 5.8.1
- 5.8.0
- 5.7.1
- 5.7.0
- 5.6.2
- 5.6.1
- 5.6.0
- 5.5.3
- 5.5.2
- 5.5.1
- 5.5.0
- 5.4.1
- 5.3.2
- 5.2.3
- 5.2.2
- 5.1.1
- 5.1.0