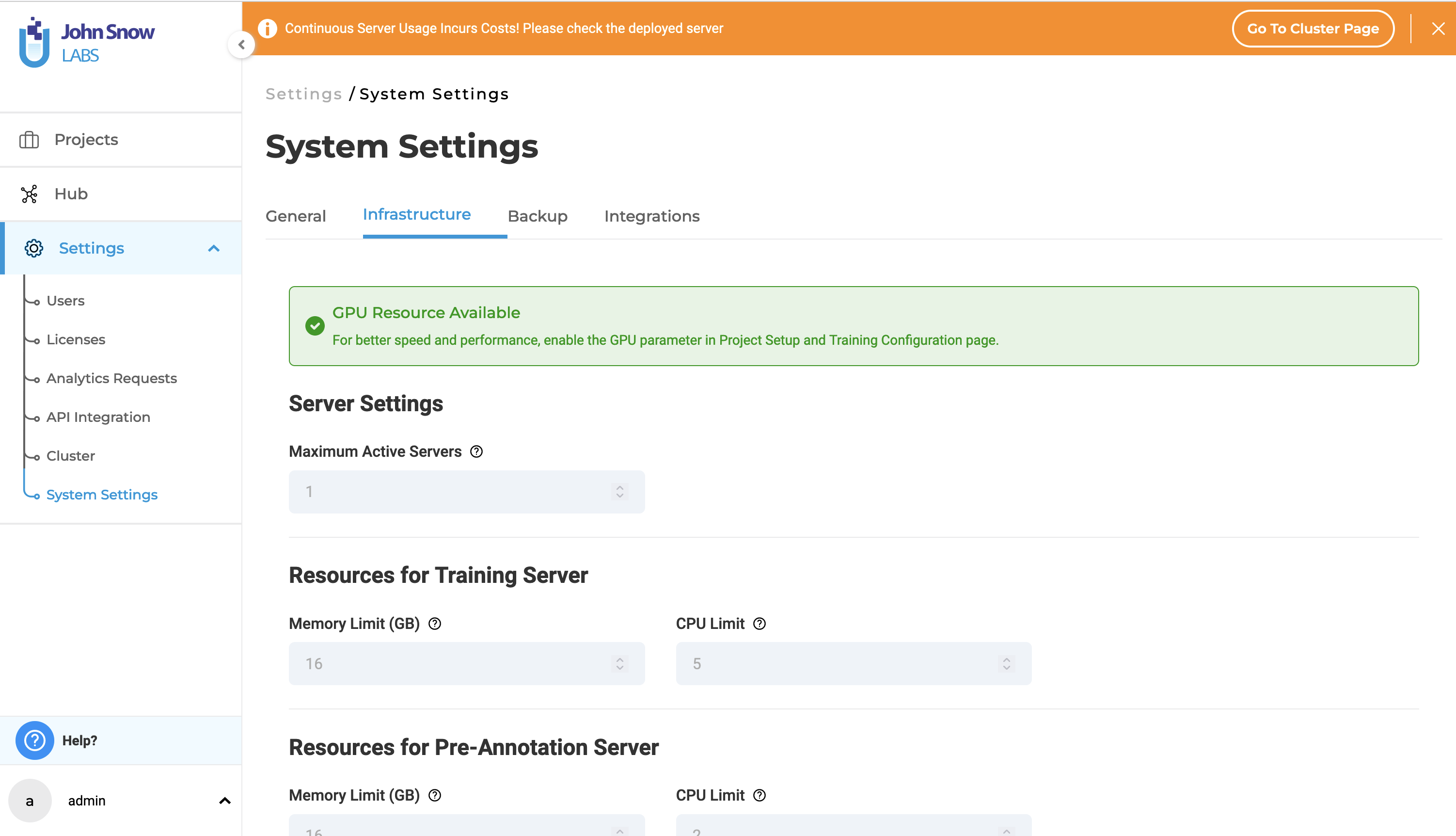
The admin user can now define the infrastructure configurations for the prediction and training tasks.
Resource allocation for Training and Pre-annotation
Generative AI Lab gives users the ability to change the configuration for the training and pre-annotation processes. This is done from the Settings > Infrastructure page. The settings can be edited by admin user and they are read-only for the other users. The Infrastructure page consists of three sections namely Resource For Training, Resource For Preannotation Server, Resources for Prenotation Pipeline.
Resources Inclusion:
- Memory Limit – Represents the maximum memory size to allocate for the training/pre-annotation processes.
- CPU Limit – Specifies this maximum number of CPUs to use by the training/pre-annotation server.
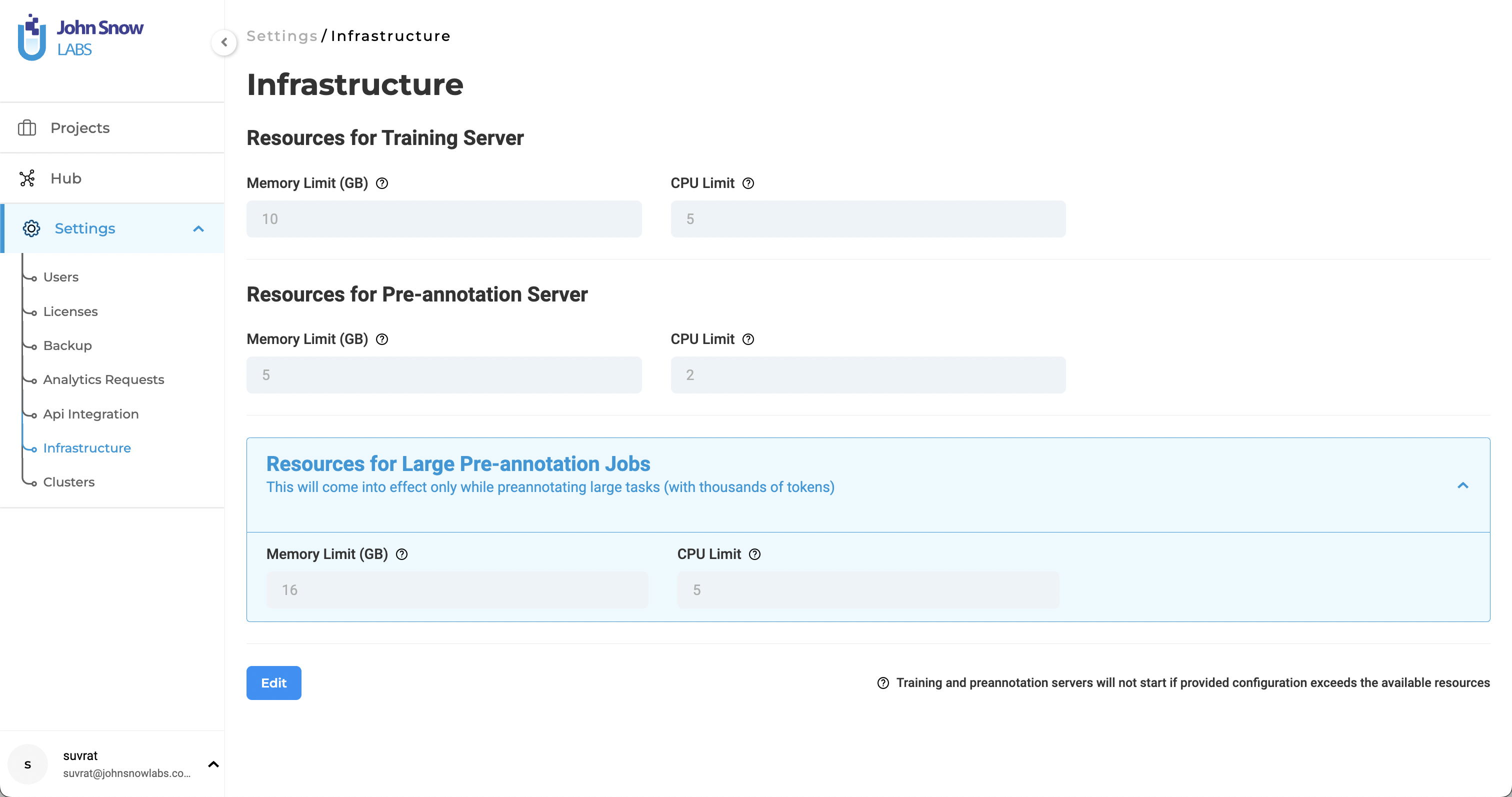
Note: If the specified configurations exceed the available resources, the server will not start.
GPU Resource Availability
If the Generative AI Lab is equipped with a GPU, the following message will be displayed on the infrastructure page:
“GPU Resource Available”.