The audio template is split into three parts: audio classification, emotion segmentation, and transcription. To play the audio, you need an Audio tag which requires a name and a value parameter.
Audio Classification
Suppose you have a sample JSON which contains some audio that you wish to classify (This input is set as default when you click on the template in Generative AI Lab):
{
"audio": "/static/samples/game.wav",
"title": "MyTestTitle"
}
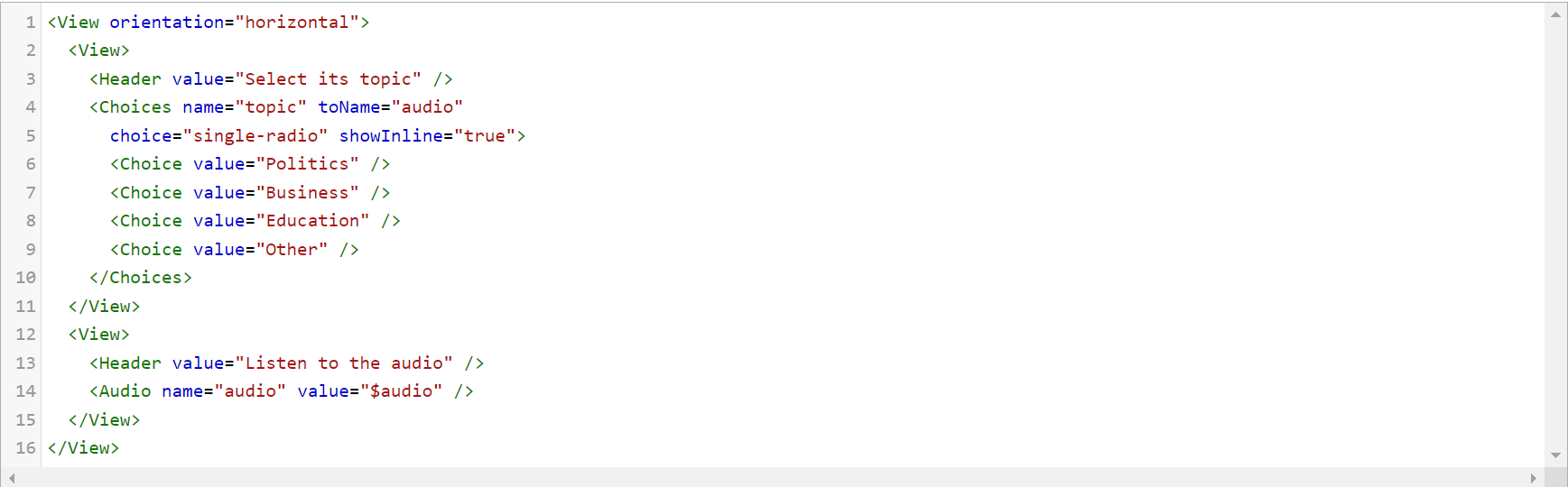
The configuration for classification task can look as shown below.
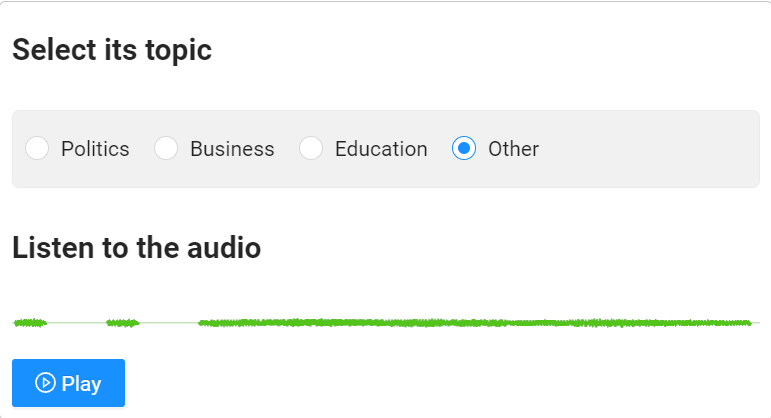
The preview should look as shown below.
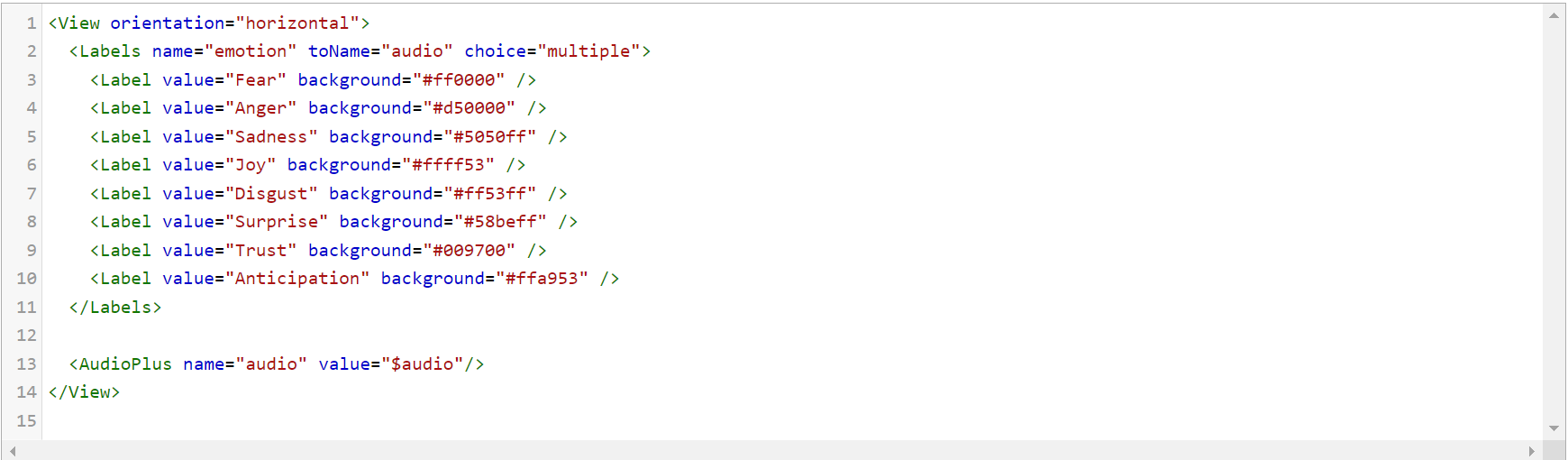
Emotion Segmentation
This is a labeling task, and requires the Label tags to assign variables. The configuration is very straightforward, as shown below.
Audio Transcription
The transcription task is further divided into two parts - either by transcription per region or transcripting whole audio. If you are transcripting per region then it will become both labeling and transcription task. For this case the configuration would look as shown below.
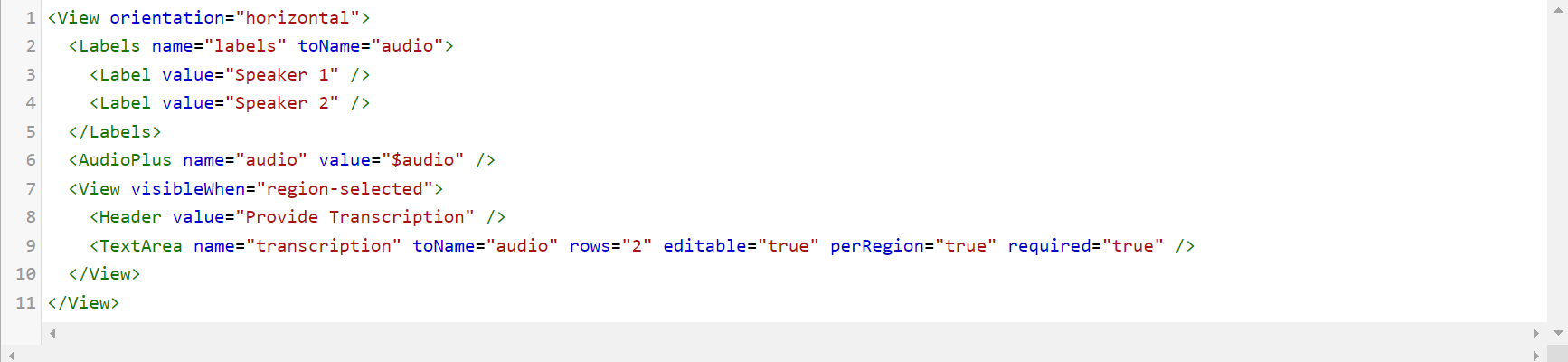
As shown in the image above, audio transcription requires a TextArea tag to enable a text box. The parameters name and toName are mandatory. For transcription of whole audio, the Label tags from the above image will disappear.