LLM Evaluation & Response Comparison
Generative AI Lab provides dedicated project types for evaluating, comparing, and reviewing responses generated by Large Language Models (LLMs).
The platform supports:
- Single-model evaluation workflows
- Multi-model response comparison
- Blind response evaluation
- Human ranking and scoring workflows
- Multi-provider and Custom LLM integration
These project types enable structured human evaluation of LLM outputs within the same collaborative annotation environment used for NLP and healthcare annotation workflows.
Blind LLM Response Comparison
Blind LLM Response Comparison is used when you want reviewers to compare multiple responses without seeing which provider or model generated each response.
In blind comparison projects:
- Responses are displayed using neutral identifiers (for example, Response A, Response B, Response C)
- The ordering of responses is shuffled per task
- Provider and model identity is hidden during review
Depending on project configuration, reviewers may also be asked to rank responses (best to worst). Ranking can be required or optional based on how the project is configured.
Supported LLM Providers & Custom Integrations
Generative AI Lab integrates with multiple leading LLM providers:
- OpenAI
- Azure OpenAI
- Amazon SageMaker
- Anthropic Claude
- Custom LLM providers
Custom LLM providers allow organizations to integrate private, self-hosted, or organization-specific LLM endpoints directly into evaluation and comparison workflows alongside supported providers.
You can configure one or more providers globally from System Settings → Integration, where credentials for each service can be securely added.
All provider communication is routed through the Generative AI Lab integration layer, enabling centralized credential handling, request management, and standardized provider communication.
The procedure is consistent across providers: enter the required API keys or access tokens, validate, and save.
Once configured, these providers are available for selection when creating LLM Evaluation or LLM Comparison projects.

Creating an LLM Evaluation Project
- Navigate to the Projects page and click New.
- After filling in the project details and assigning to the project team, proceed to the Configuration page.
- Under the Text tab in step 1 (Content Type), select LLM Evaluation task and click Next.
- On the Select LLM Providers page, you can either:
- Click Add to create an LLM provider specific to the project (this provider will only be used within this project), or
- Click Go to External Service Page to be redirected to the Integration page, associate the project with one or more integrated or Custom LLM providers, and return to Project → Configuration → Select LLM Response Provider
- Choose the provider you want to use, save the configuration, and click Next.
- Customize labels and choices as needed in the Customize Labels section, and save the configuration.
For LLM Comparison projects, follow the same steps, but associate the project with two or more different LLM providers and select them on the LLM Response Provider page.
Importing Prompts for LLM Evaluation (No Pre-Filled Responses)
To start working with prompts:
- Go to the Tasks page and click Import.
- Upload your prompts in either
.jsonor.zipformat using the structure below.
Sample JSON for LLM Evaluation Project
{
"data": {
"prompt": "Give me a diet plan for a diabetic 35 year old with reference links",
"response1": "",
"title": "DietPlan"
}
}
Sample JSON for LLM Comparison Project
{
"data": {
"prompt": "Give me a diet plan for a diabetic 35 year old with reference links",
"response1": "",
"response2": "",
"title": "DietPlan"
}
}
- Once the prompts are imported as tasks, click the Generate Response button to fetch LLM responses directly from the configured providers. Generated responses can originate from supported providers or organization-hosted Custom LLM integrations configured through the Integrations page.
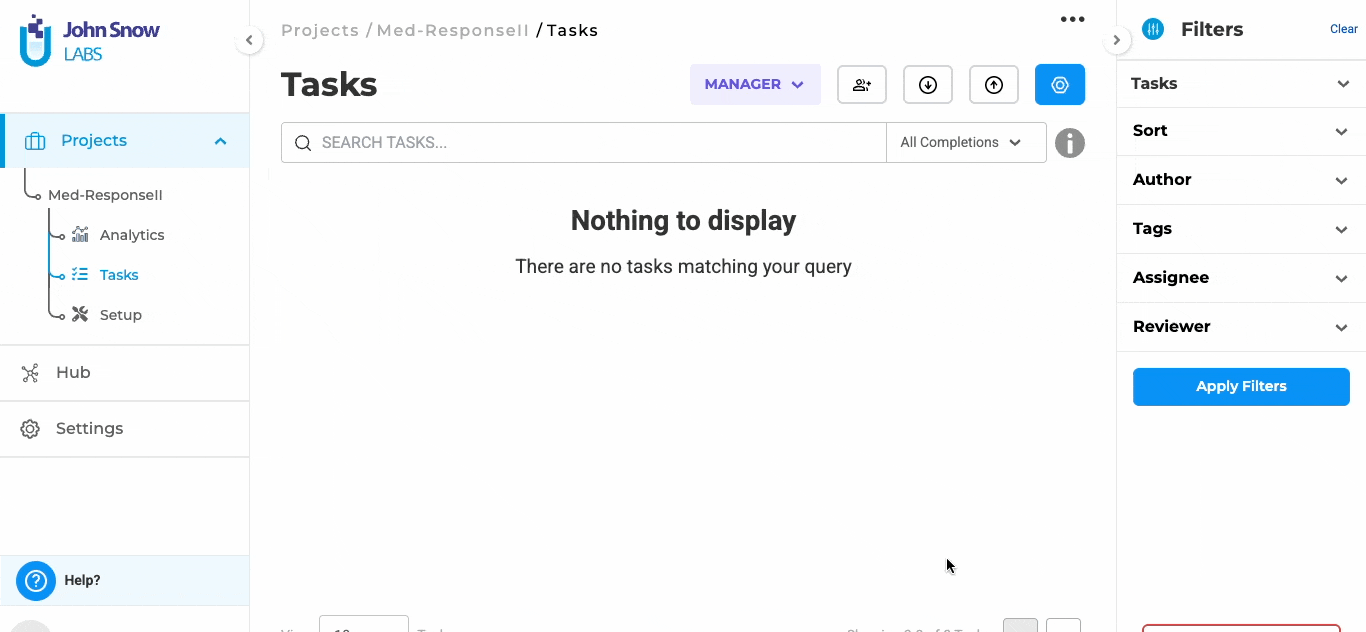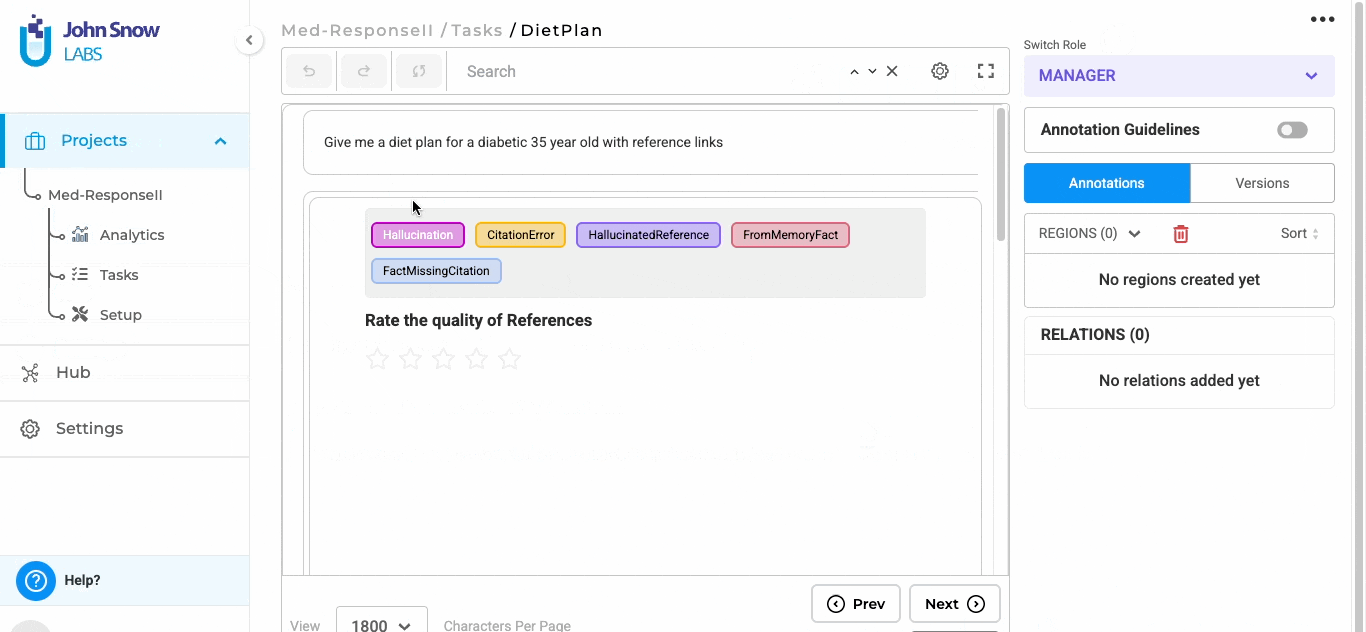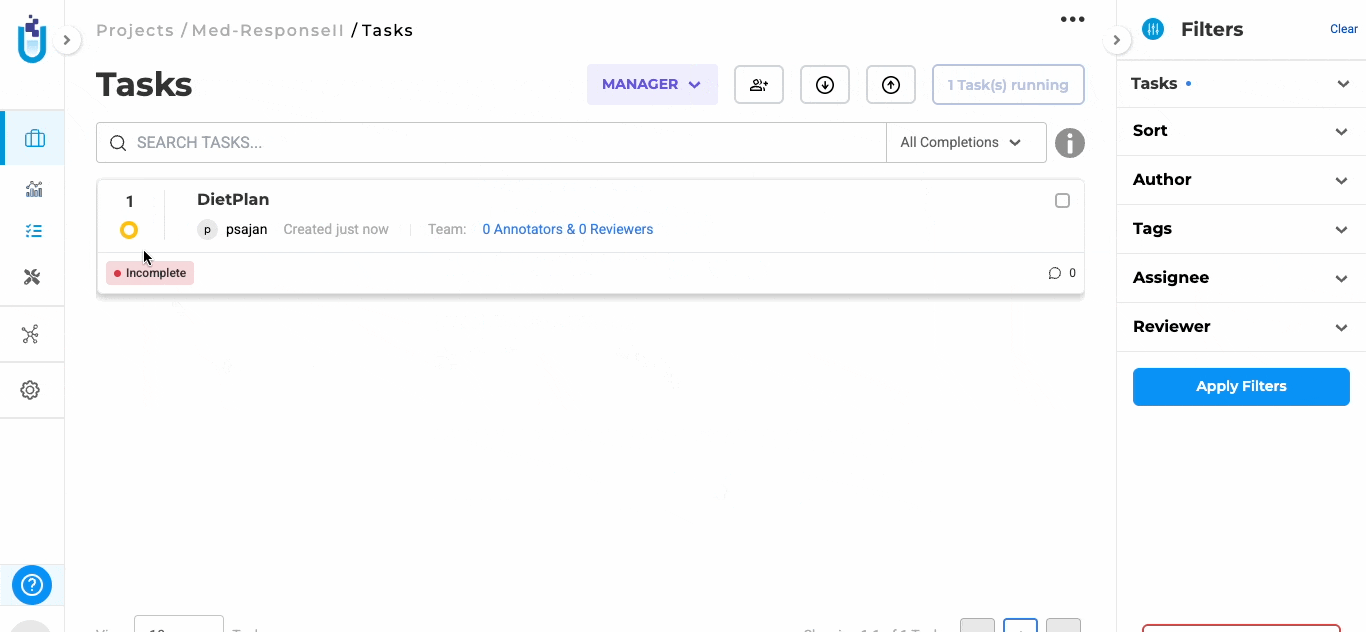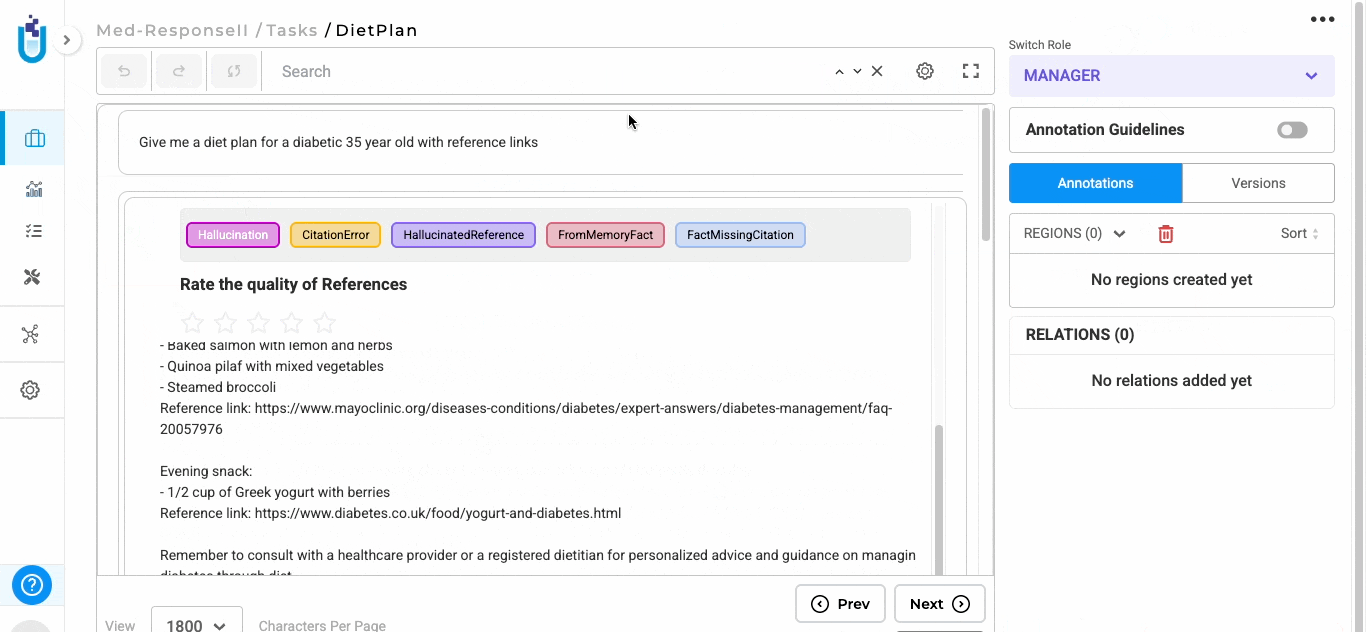
After the responses are generated, users can begin evaluating them directly within the task interface.
Importing Prompts and LLM Responses for Evaluation
Users can also import prompts and LLM-generated responses using a structured JSON format. This feature supports both LLM Evaluation and LLM Comparison project types and is useful when responses are generated outside Generative AI Lab.
Below are example JSON formats:
- LLM Evaluation: includes a prompt and one LLM response mapped to a provider
- LLM Comparison: supports multiple LLM responses to the same prompt
Sample JSON for LLM Evaluation Project with Response
{
"data": {
"prompt": "Give me a diet plan for a diabetic 35 year old with reference links",
"response1": "Prompt Response 1 Here",
"llm_details": [
{ "synthetic_tasks_service_provider_id": 1, "response_key": "response1" }
],
"title": "DietPlan"
}
}
Sample JSON for LLM Comparison Project with Responses
{
"data": {
"prompt": "Give me a diet plan for a diabetic 35 year old with reference links",
"response1": "Prompt Response1 Here",
"response2": "Prompt Response2 Here",
"llm_details": [
{ "synthetic_tasks_service_provider_id": 1, "response_key": "response1" },
{ "synthetic_tasks_service_provider_id": 2, "response_key": "response2" }
],
"title": "DietPlan"
}
}
When used in blind comparison projects, imported responses are anonymized during review.
Analytics Dashboard for LLM Evaluation Projects
LLM Evaluation and Response Comparison projects include dedicated analytics dashboards for monitoring reviewer behavior, provider selection trends, evaluation labels, and quality scoring metrics.
Available analytics sections include:
- LLM Choices
- Label Insights
- Quality Scores
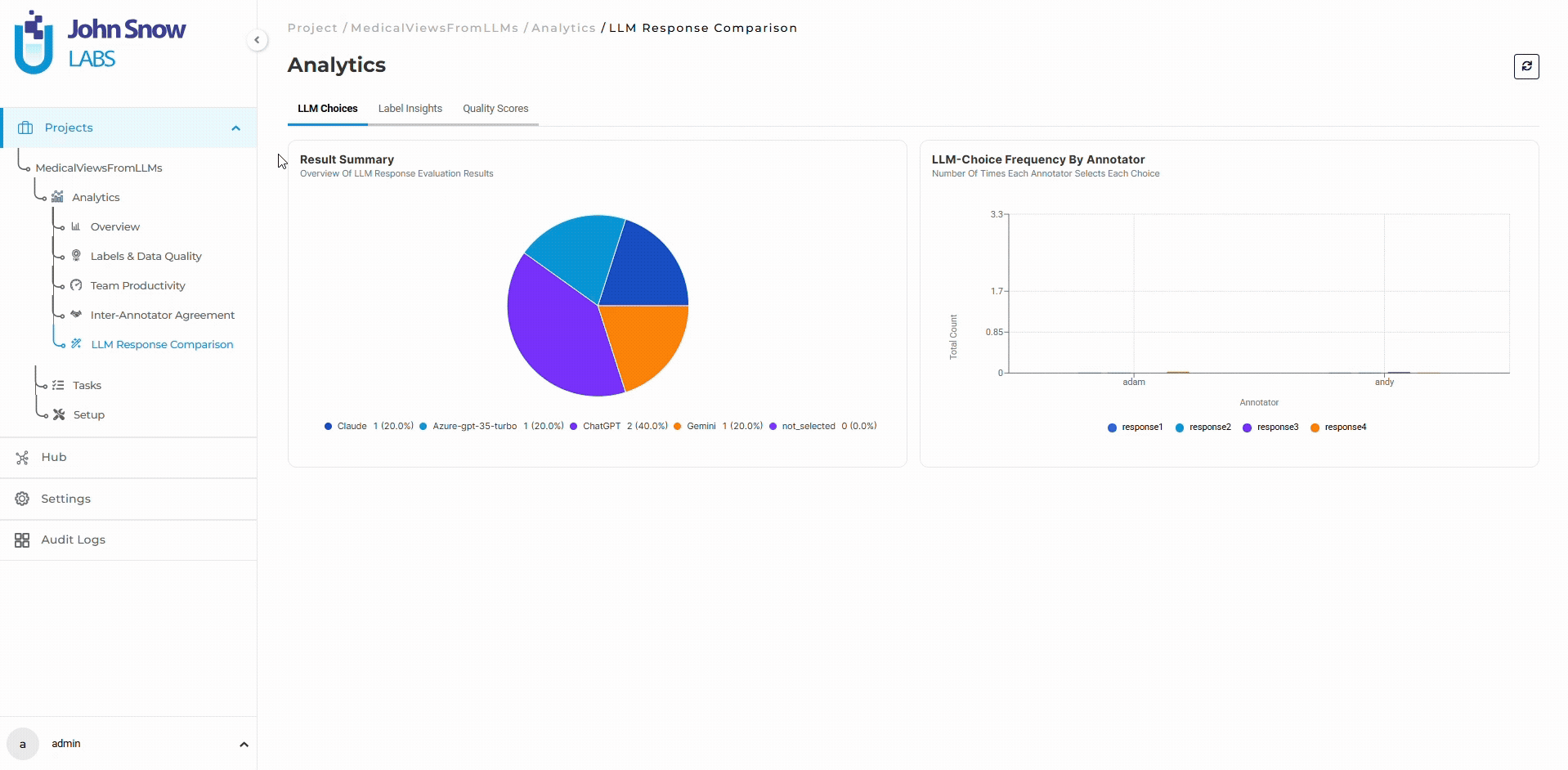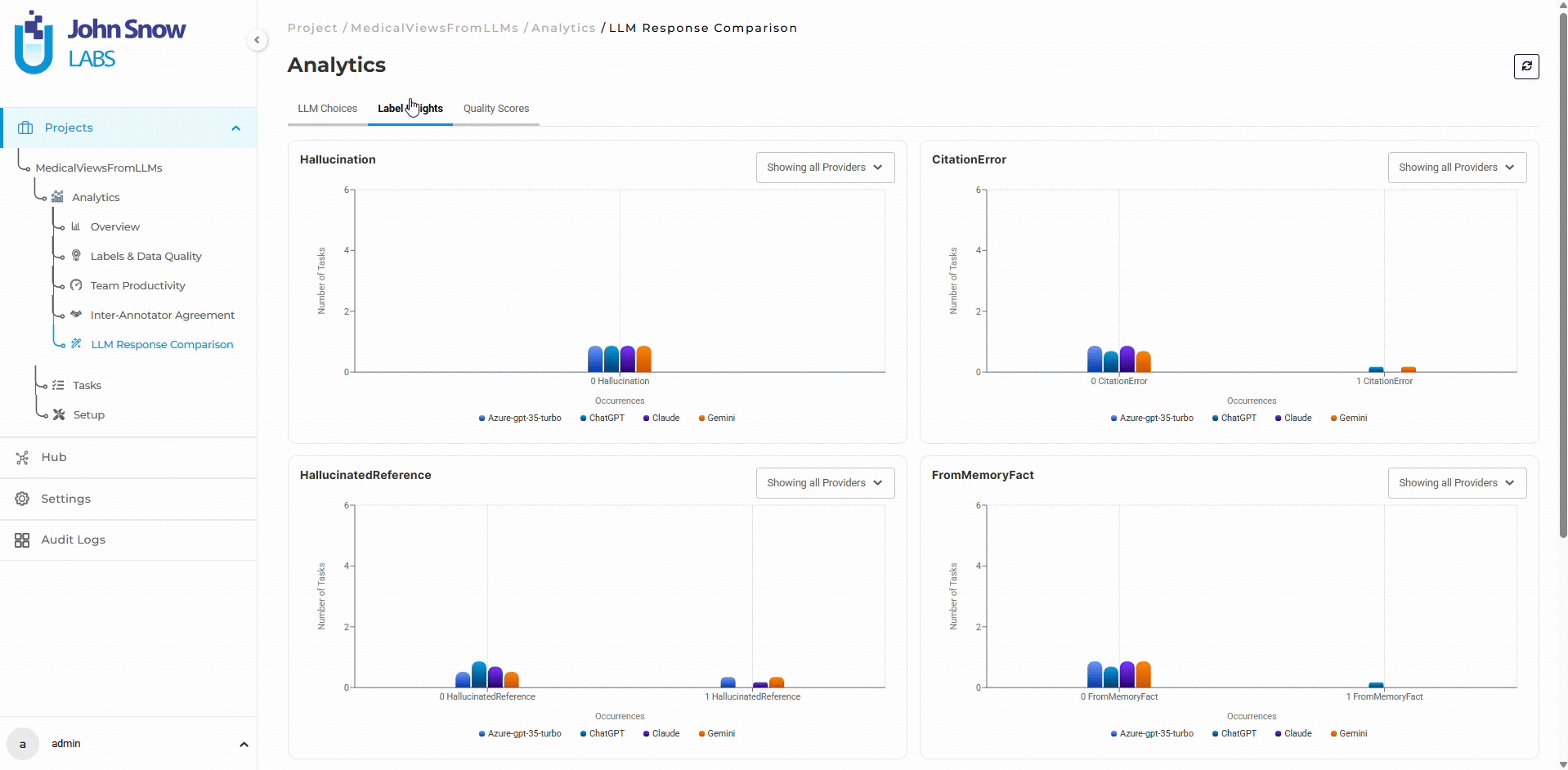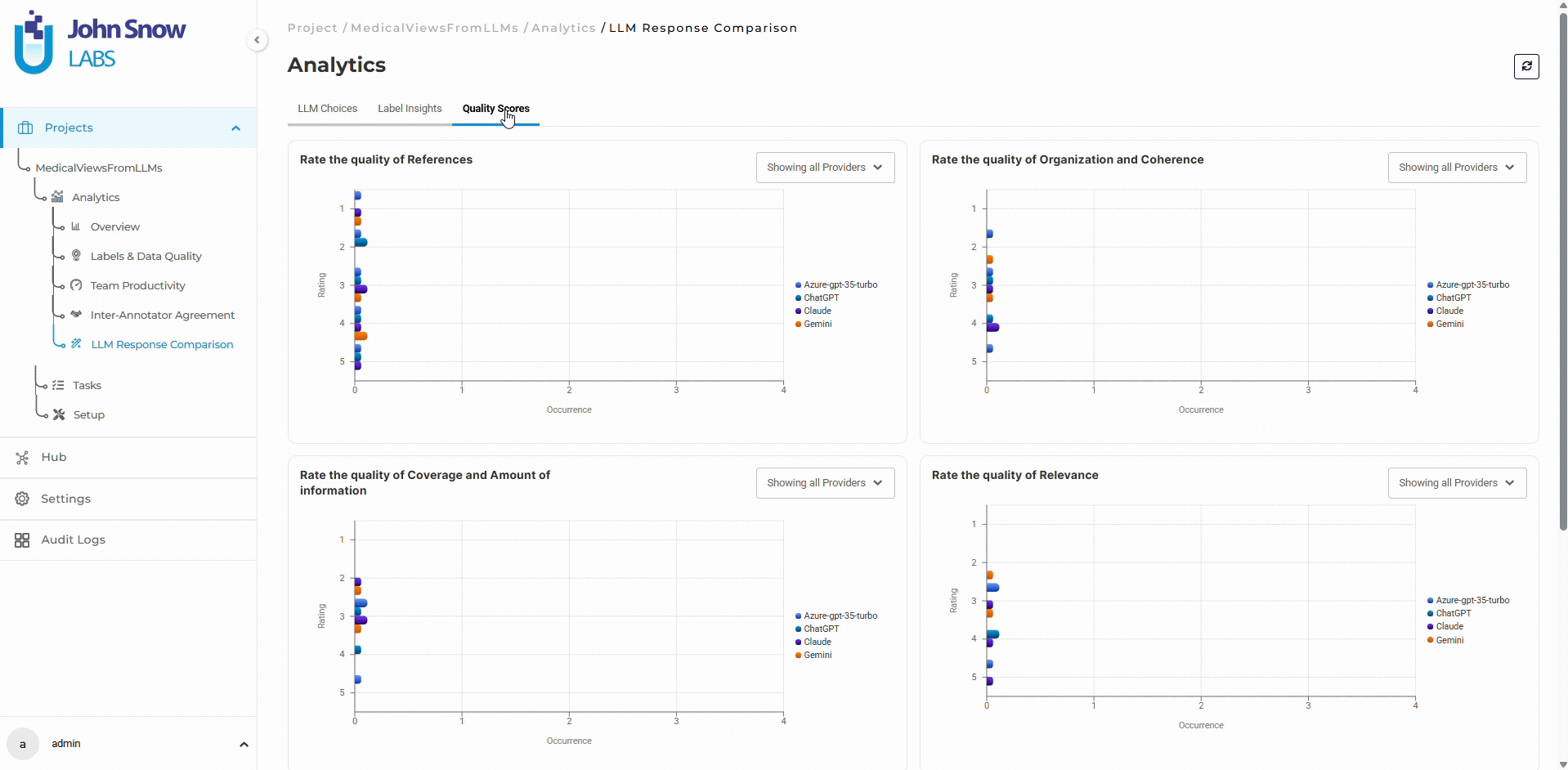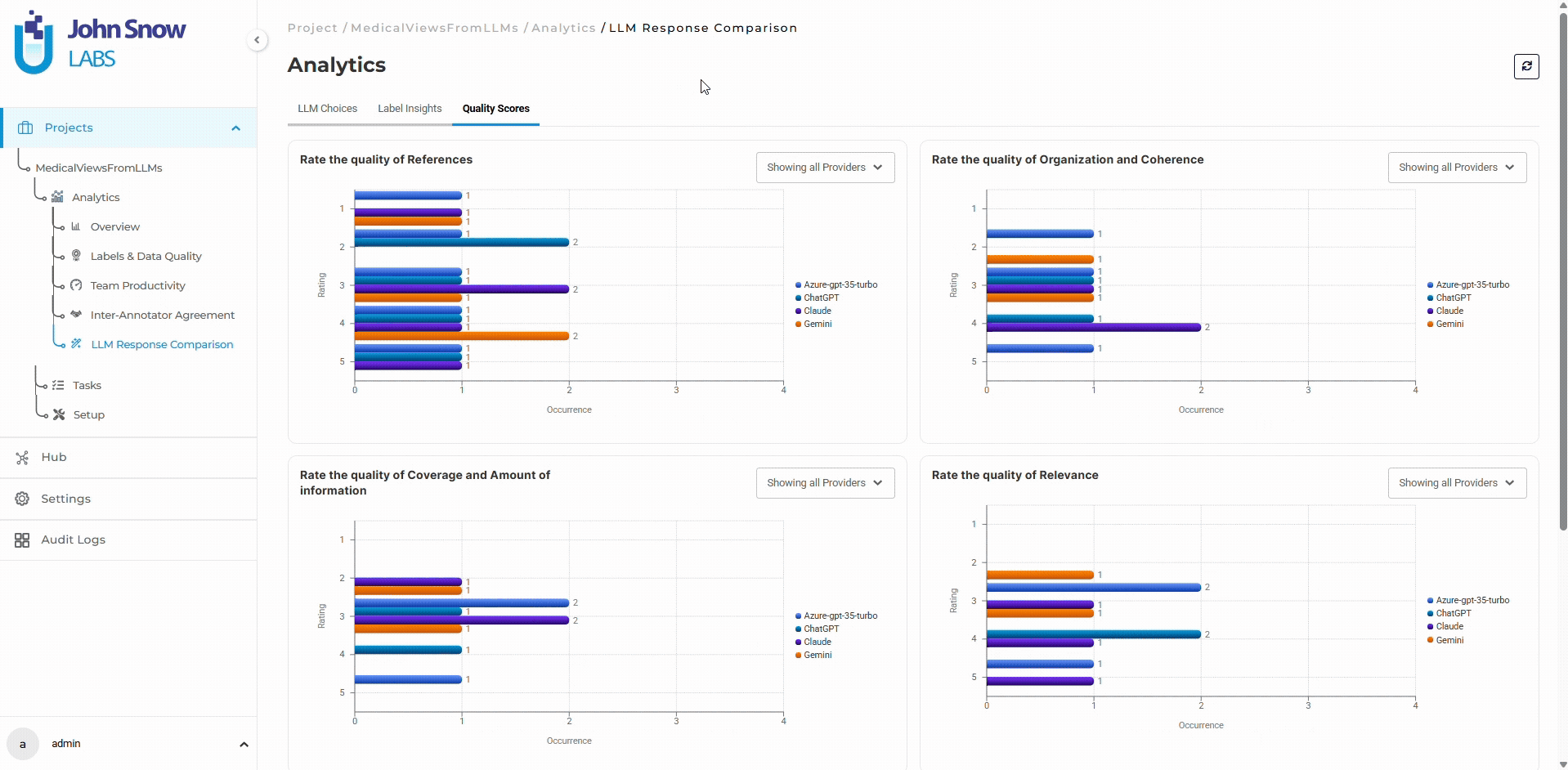
These dashboards support:
- Provider selection analysis
- Annotator preference tracking
- Hallucination and citation analytics
- Quality scoring distribution
- Comparative provider evaluation
- Multi-annotator evaluation analysis
Analytics dashboards support filtering, provider selection, and export functionality directly within the interface. For more information about Analytics dashboards and evaluation metrics, see the Analytics Dashboard documentation.
The general workflow for these projects aligns with the existing annotation flow in Generative AI Lab. These project types extend standard annotation workflows with integrated LLM response generation, multi-provider evaluation, blind comparison capabilities, and structured human review directly within the platform.
These project types provide teams with a structured approach to assess and compare LLM outputs efficiently, whether for performance tuning, QA validation, or human-in-the-loop benchmarking.