Once a new project is created and its configuration is saved, the user is redirected to the Import page. Here the user has multiple options for importing tasks.

Users can import the accepted file formats in multiple ways. They can drag and drop the file(s) to the upload box, select the file from the file explorer, provide the URL of the file in JSON format, or import it directly from the S3 bucket. To import from Amazon S3 bucket the user needs to provide the necessary connection details (credentials, access keys, and S3 bucket path). All documents present in the specified path, are then imported as tasks in the current project.

Plain text file
When you upload a plain text file, only one task will be created which will contain the entire data in the input file.
Previously, plain text files were split by newline characters into multiple tasks, but the system now treats the entire file as a single unit for more accurate and efficient processing.
Json file
For bulk importing a list of documents you can use the json import option. The expected format is illustrated in the image below. It consists of a list of dictionaries, each with 2 keys-values pairs (“text” and “title”).
[{"text": "Task text content.", "title":"Task title"}]
CSV, TSV file
When CSV / TSV formatted text file is used, column names are interpreted as task data keys:
Task text content, Task title
this is a first task, Colon Cancer.txt
this is a second task, Breast radiation therapy.txt
Import annotated tasks
When importing tasks that already contain annotations (e.g. exported from another project, with predictions generated by pre-trained models) the user has the option to overwrite completions/predictions or to skip the tasks that are already imported into the project.

NOTE: When importing tasks from different projects with the purpose of combining them in one project, users should take care of the overlaps existing between tasks IDs. Generative AI Lab will simply overwrite tasks with the same ID.
Flexible Label Matching & Mapping
When importing annotated JSON files, label names no longer need to exactly match the labels configured in the destination project.
During import, Generative AI Lab automatically compares the labels in the uploaded JSON with the project’s configured labels. If differences are detected—such as variations in capitalization or naming conventions—the system presents an interactive mapping interface instead of rejecting the import.
Users can:
- Review unmatched labels
- Accept automatically suggested mappings
- Map uploaded labels to existing project labels
- Ignore labels that are not needed
Suggested mappings are generated automatically using case-insensitive comparison, normalized label matching, and string similarity detection.
For example, an uploaded label named Problem can be automatically mapped to an existing project label named PROBLEM, allowing the import to proceed without modifying the original JSON file.

This feature is supported for:
- Text NER projects
- Visual NER projects
- Named Entity Recognition (NER)
- Classification
- Relation annotations
Note: Label mappings are applied only during the import process. The uploaded JSON file is not modified, and the destination project’s label configuration remains unchanged.
Dynamic Task Pagination
Dynamic pagination allows annotators and reviewers to control how large documents are displayed during annotation.
Instead of relying on static <pagebreak> tags or manual preprocessing, users can now define pagination settings directly from the Labeling page, making the workflow more flexible and efficient.
Annotators can choose the number of words to include on a single page from a predefined list or specify a custom value, tailoring the page size to their preference or task complexity.

An additional setting is available to prevent sentences from being split across pages, ensuring better readability and preserving context during annotation.

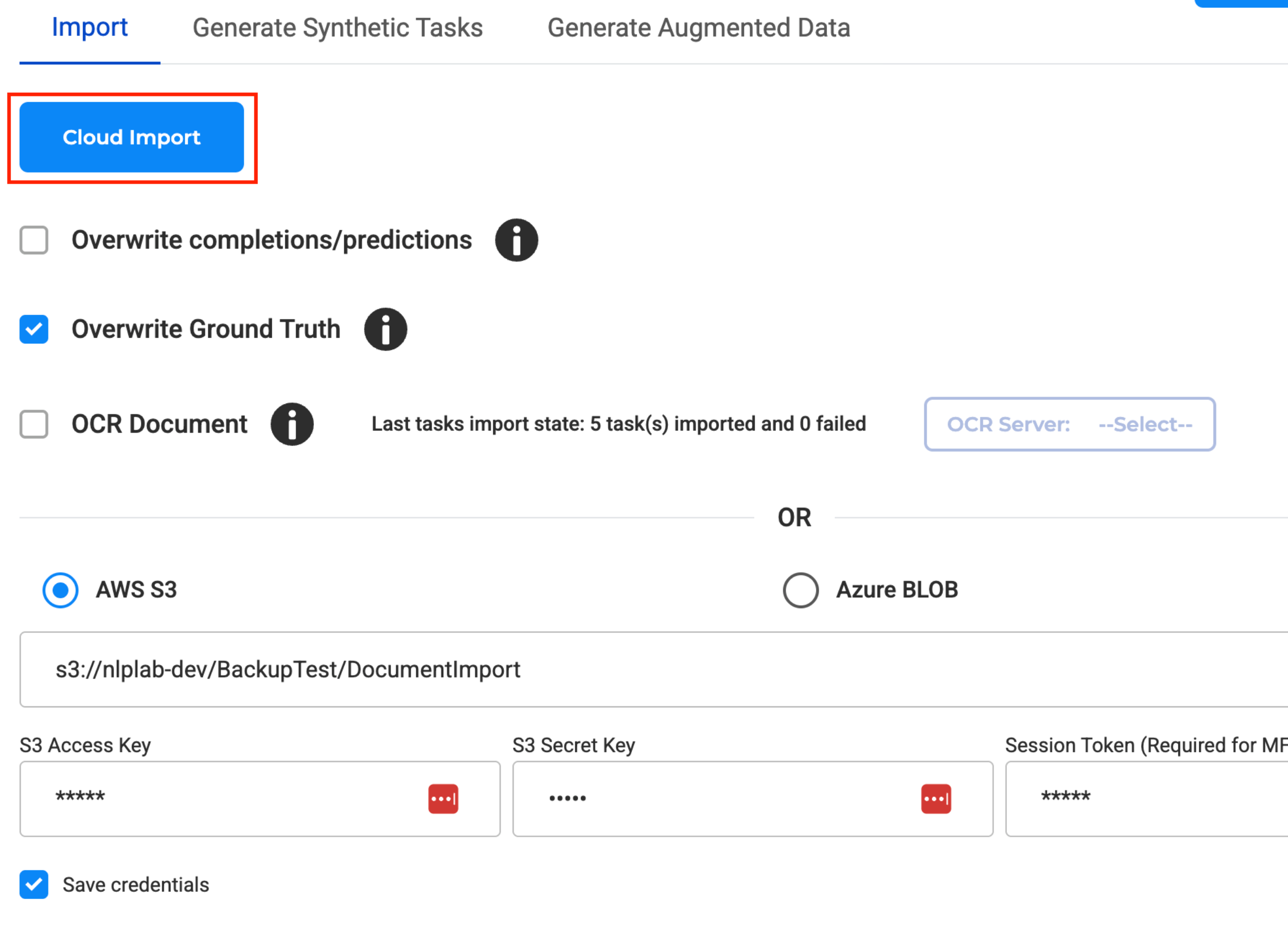
Import from Cloud Storage
Generative AI Lab supports importing tasks and entire projects directly from cloud storage, including AWS S3 and Azure Blob Storage.
Task Import from AWS S3 and Azure Blob
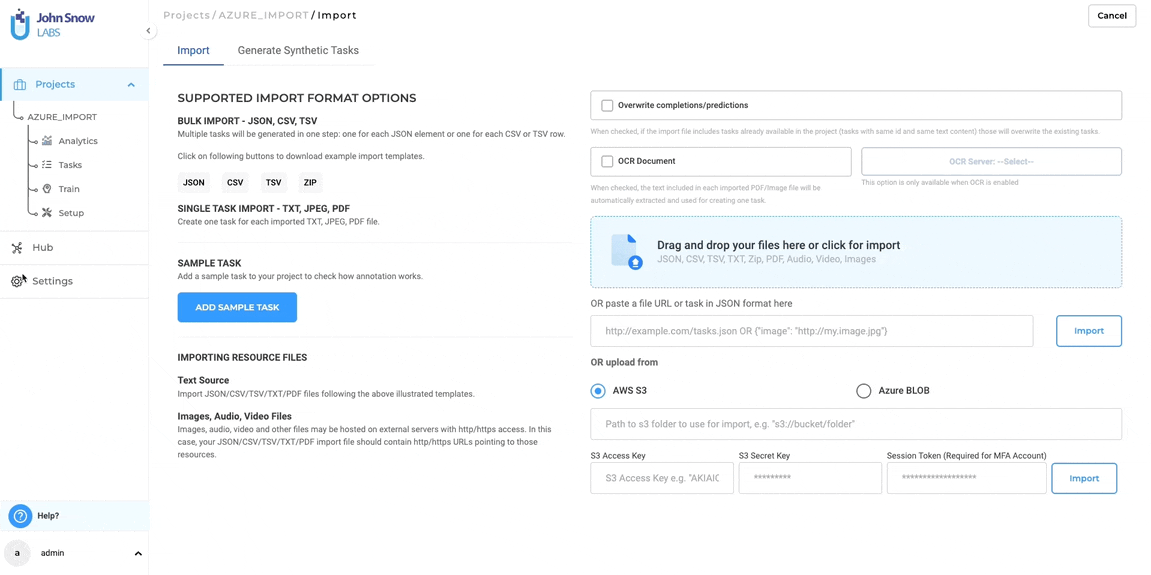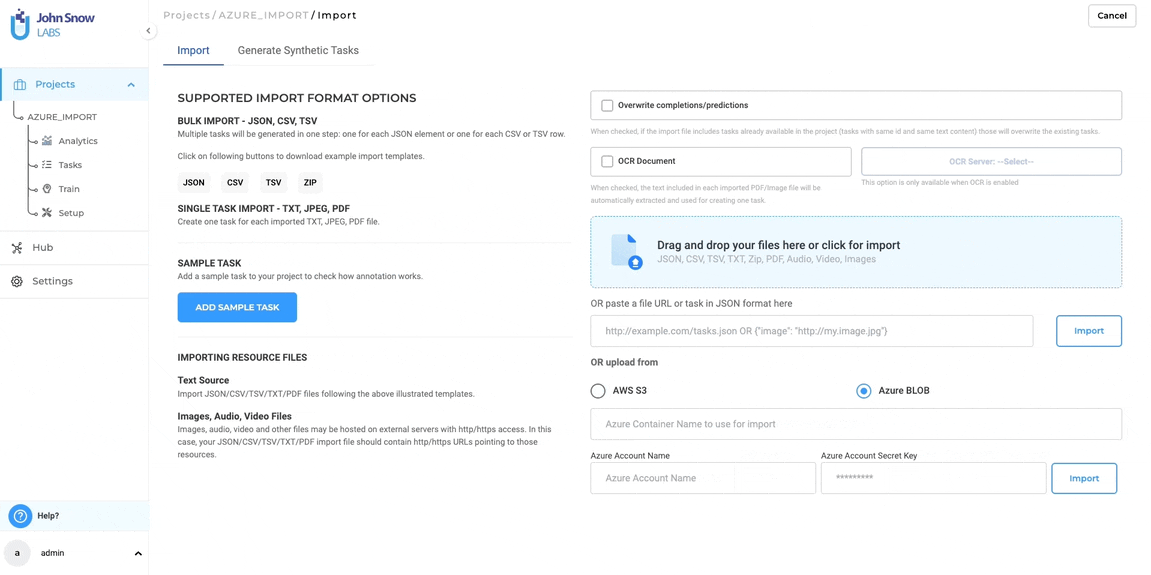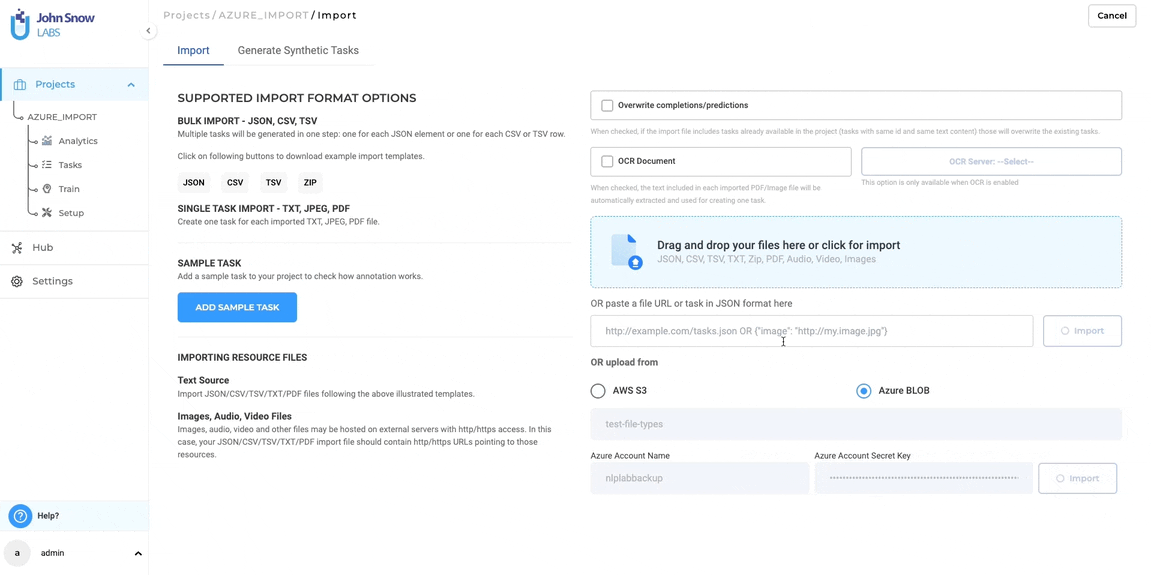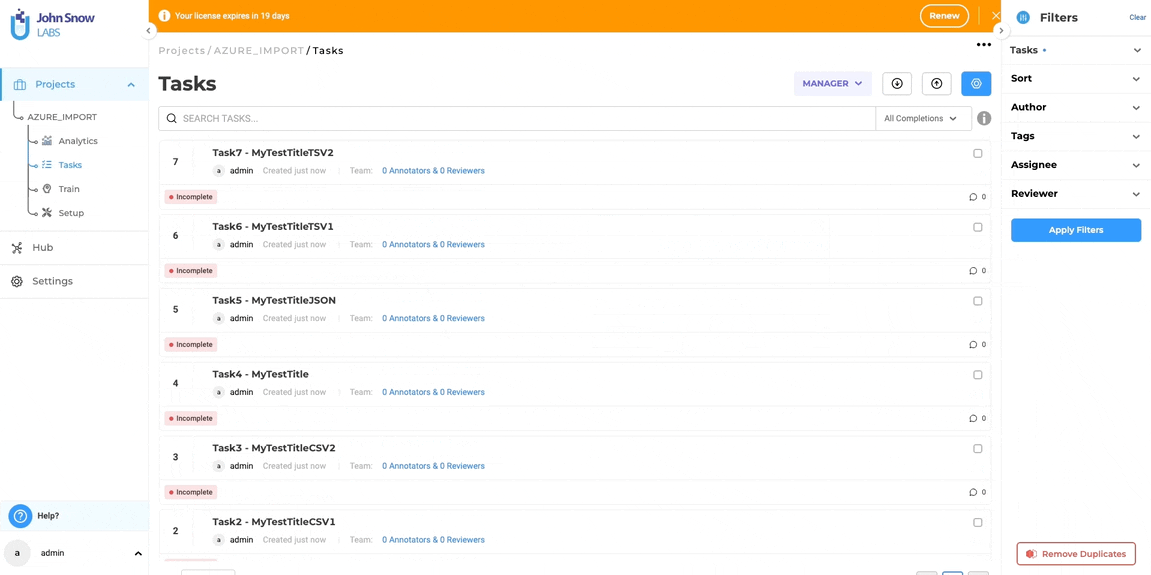
You can import individual documents (e.g., PDFs, images, videos, audio, plain text) as tasks into your project using the Import Page:
How to Import Tasks from Cloud:
- Go to the Import Page in your target project.
- Select your cloud provider:
- Choose AWS S3 or Azure Blob as the import source.
- Enter cloud connection details:
- For AWS S3: Bucket name, path, Access Key, Secret Key (and Session Token for MFA).
- For Azure Blob: Container name, Account name, and Account Secret Key.
- Click “Import” to fetch all files from the specified path and load them as tasks into your project.
- If your Generative AI Lab instance is running on an AWS EC2 machine that has an IAM role attached, you can skip filling the Access Key and Secret Key fields. The Lab automatically uses the instance role credentials for S3 import and export operations, offering a secure, credential-free connection.
Note:- All compatible documents in the specified cloud path will be automatically converted into tasks in the current project. Note: When re-importing from the same AWS S3 path, previously imported files are automatically skipped. Only new or updated files are added as tasks, preventing duplicates and streamlining incremental imports.
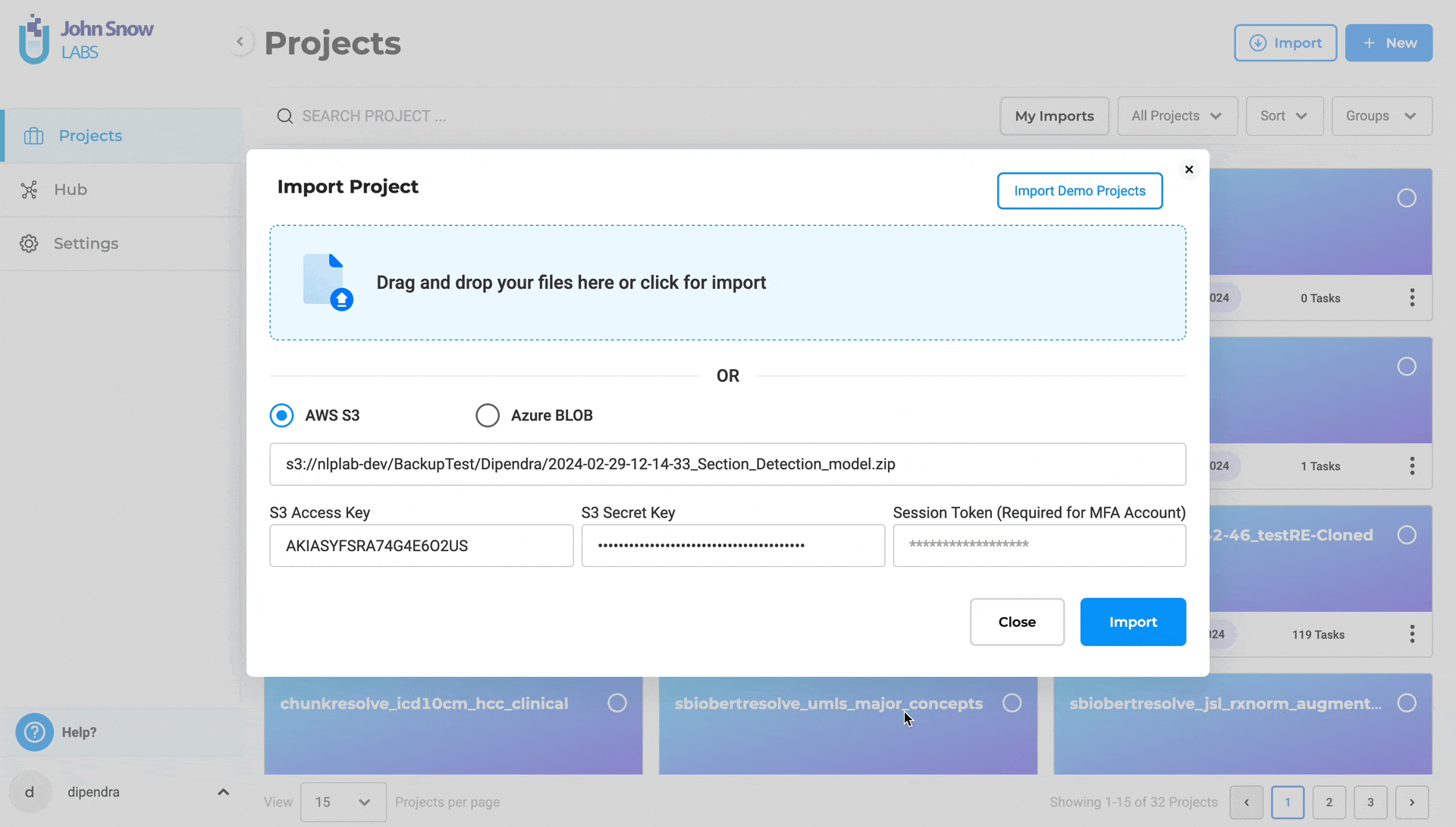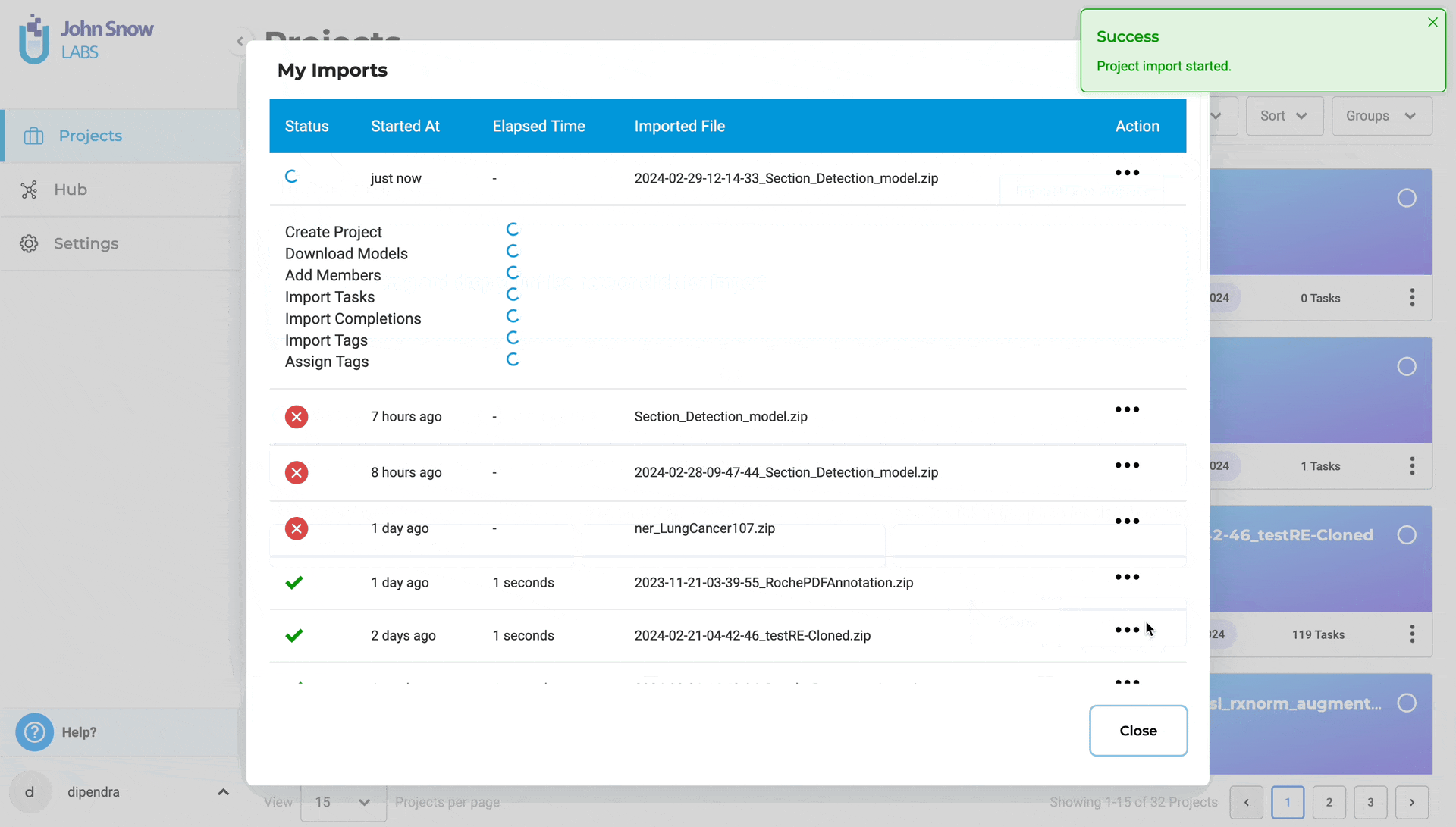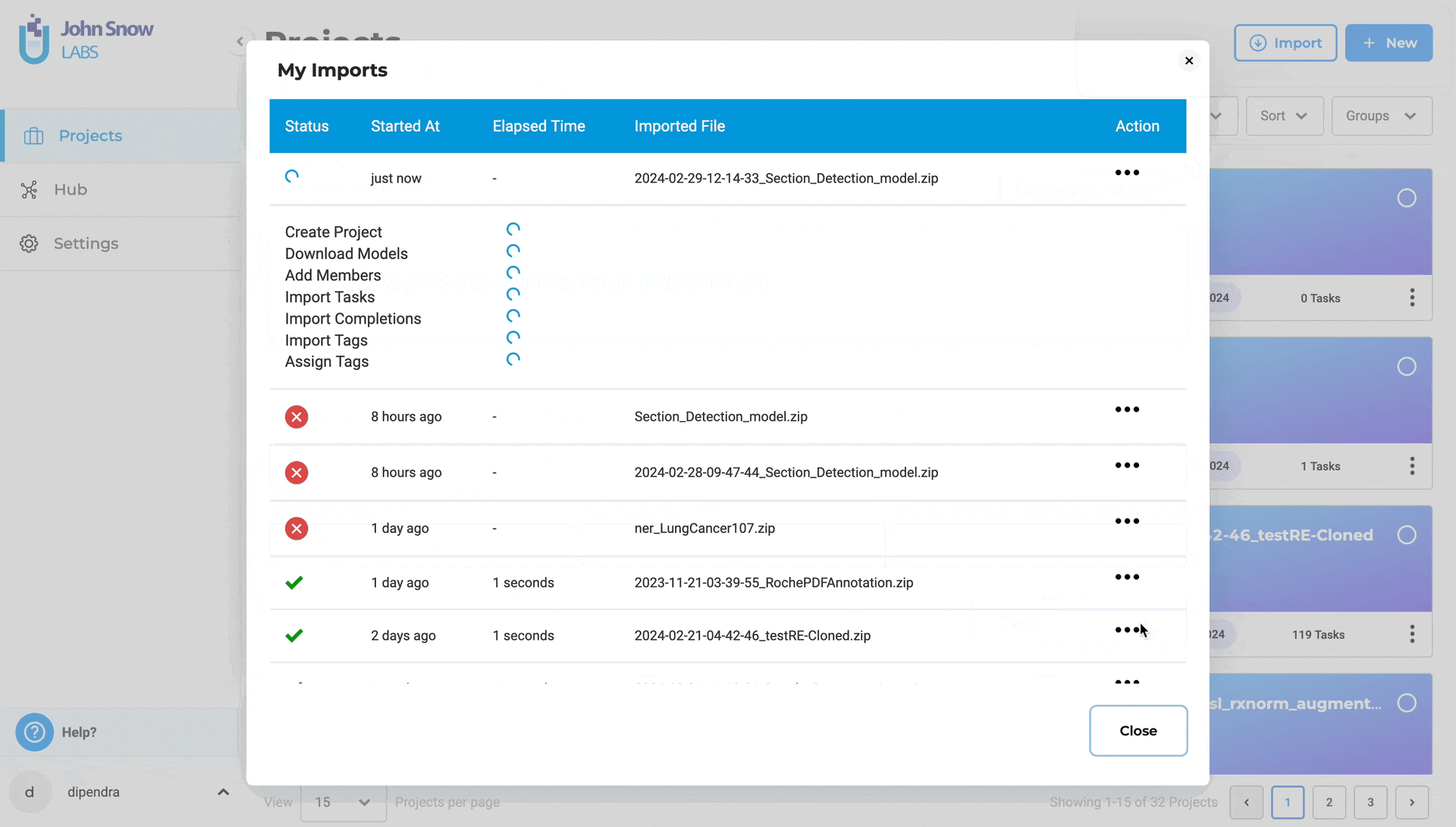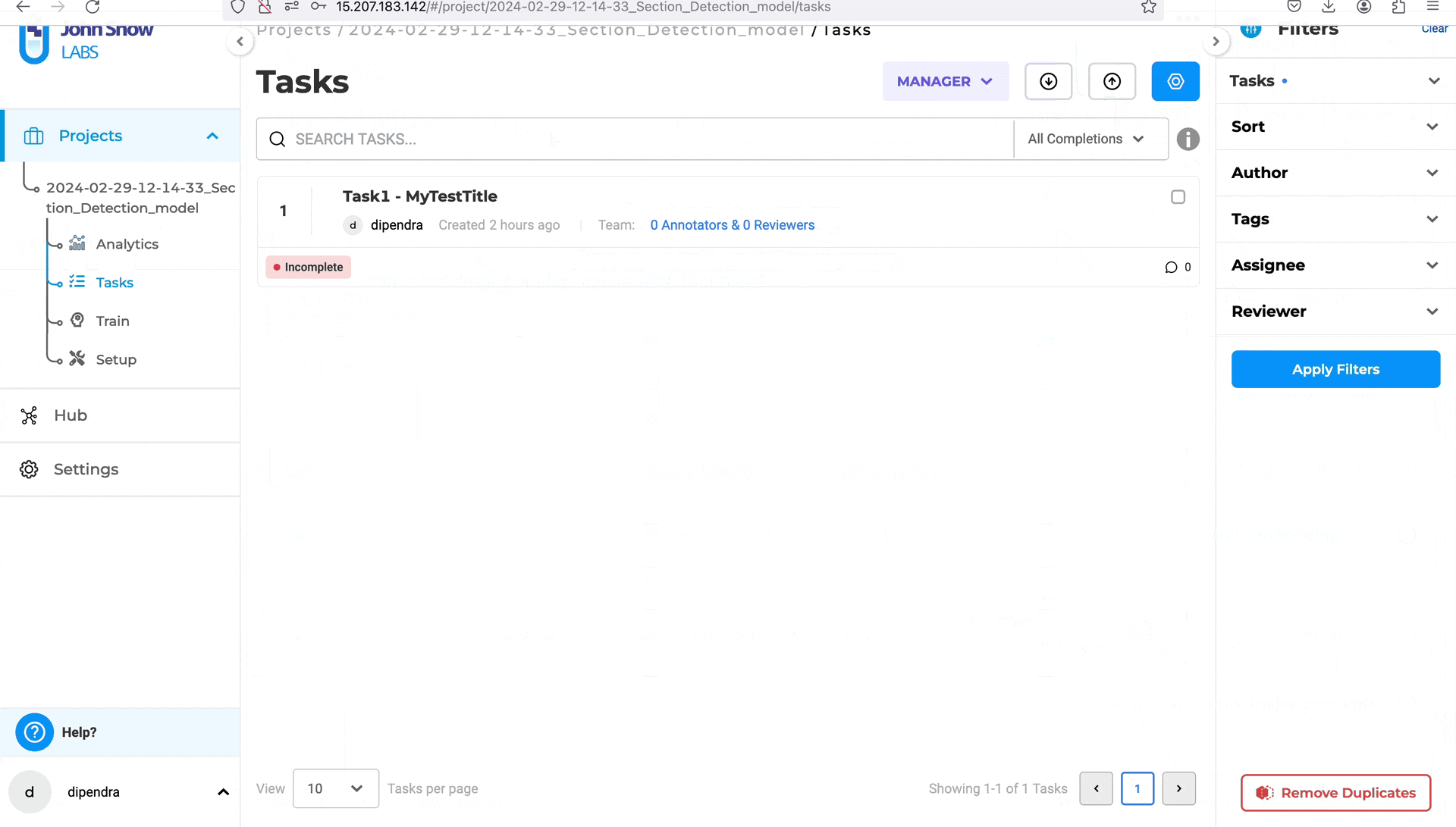
Import Project from S3 and Blob
SUsers are able to import a full project archive (including tasks, labels, configurations) stored as a .zip file in cloud storage.
How to Import a Project from AWS S3:
- Go to the Import Project section.
- Select AWS S3.
- Provide:
- File path (e.g., s3://bucket/folder/project.zip)
- Access Key, Secret Key, and Session Token (if required)
- Click “Import”.
The same approach should be taken to import a project from Azure Blob.
Cloud Storage Credential Management
Cloud storage credentials (AWS S3, Azure Blob Storage) can be saved at the project level, eliminating repetitive credential entry while maintaining security isolation.
Technical Implementation:
- Credentials stored per-project, not globally
- Automatic credential reuse for subsequent import/export operations within the same project
- Dedicated UI controls for managing credentials during Import and Export
- Credentials excluded from project ZIP exports for security compliance
- Support for credential updates through explicit save actions
 Task Import from AWS S3 Storage
Task Import from AWS S3 Storage
Note:- Credentials, once saved, will remain associated with the project and will be auto-filled when revisiting the Import or Export pages—even if a different path or new credentials are used temporarily. To update them, users must explicitly choose to save new credentials.*
Note:- If credentials are saved for a different cloud provider within the same project (e.g., switching from AWS to Azure), the previously stored credentials will be overwritten with the new set.
Example Use Case: A medical coding organization can save their S3 credentials once to import daily batches of clinical documents for human-in-the-loop validation, while simultaneously maintaining separate Azure credentials for exporting coded results to their analytics platform—eliminating daily credential re-entry across both cloud providers.
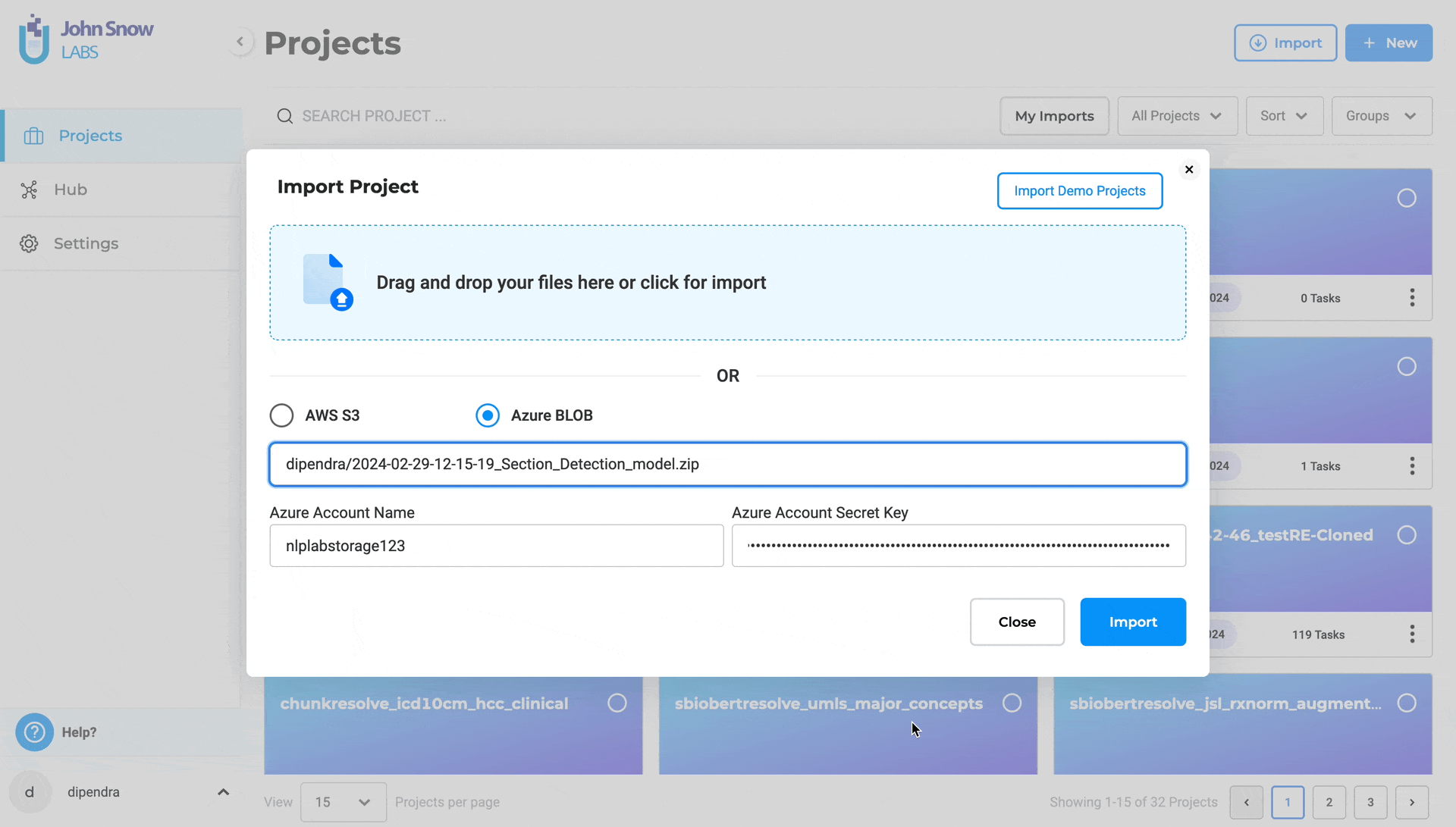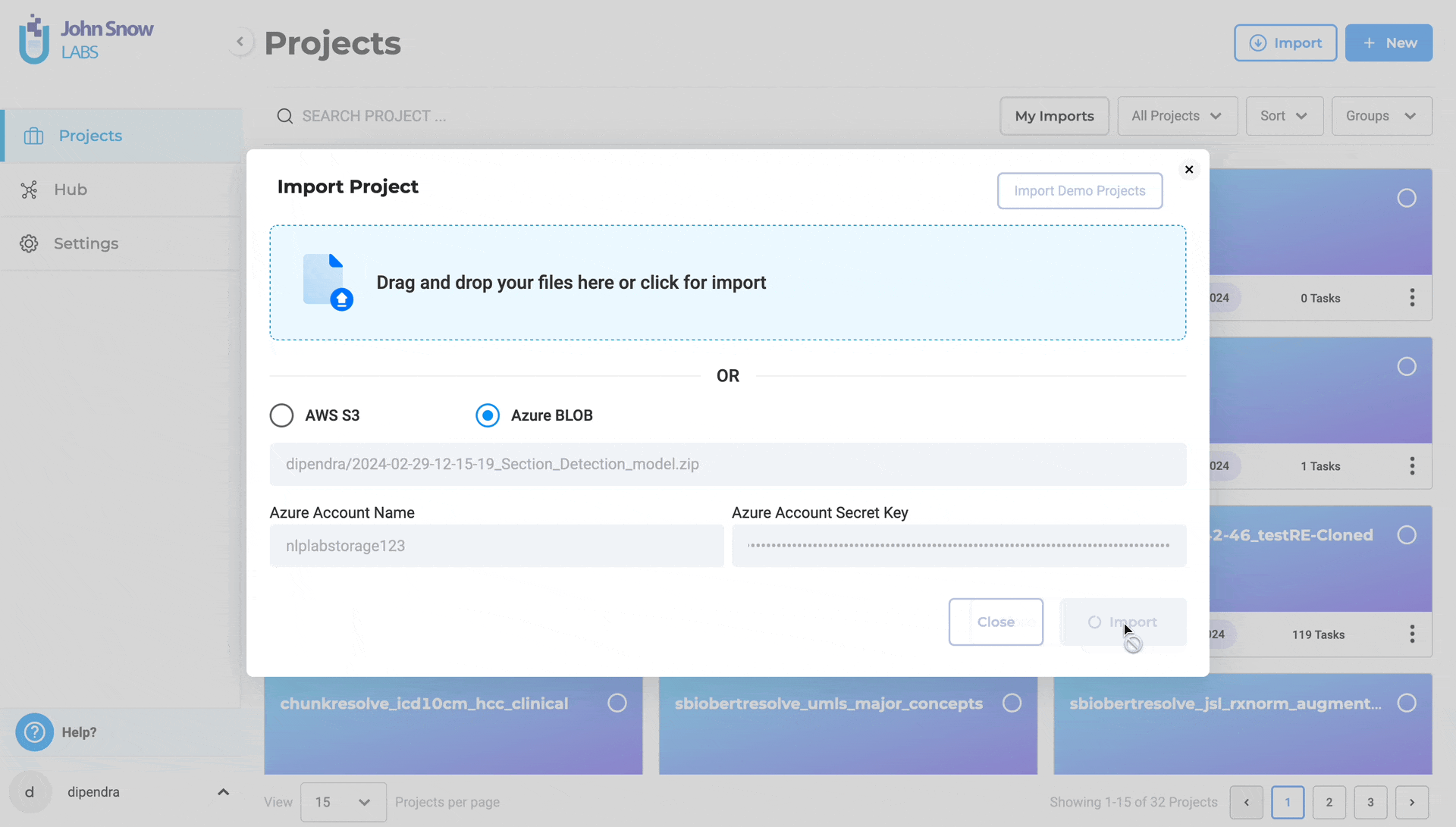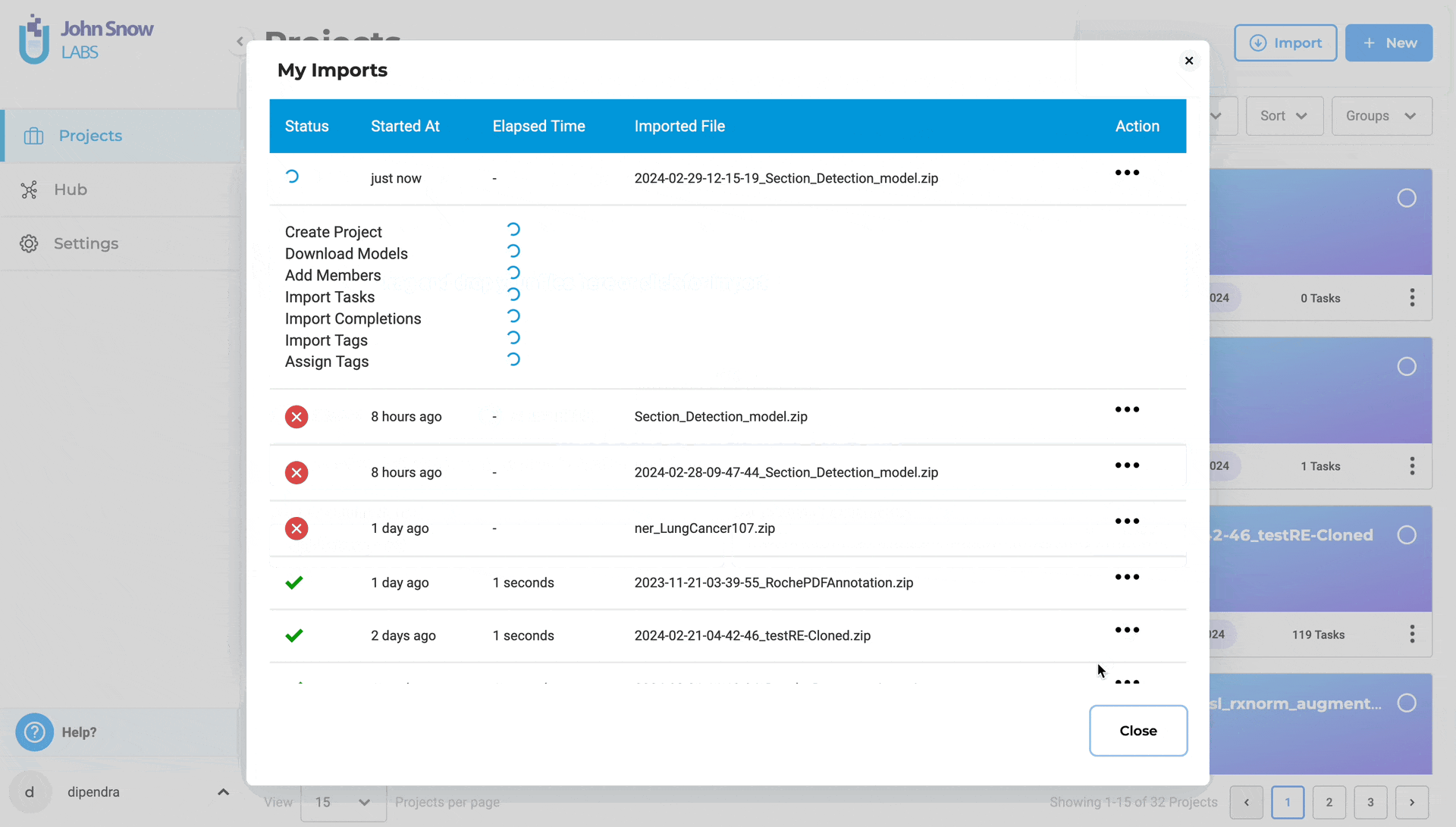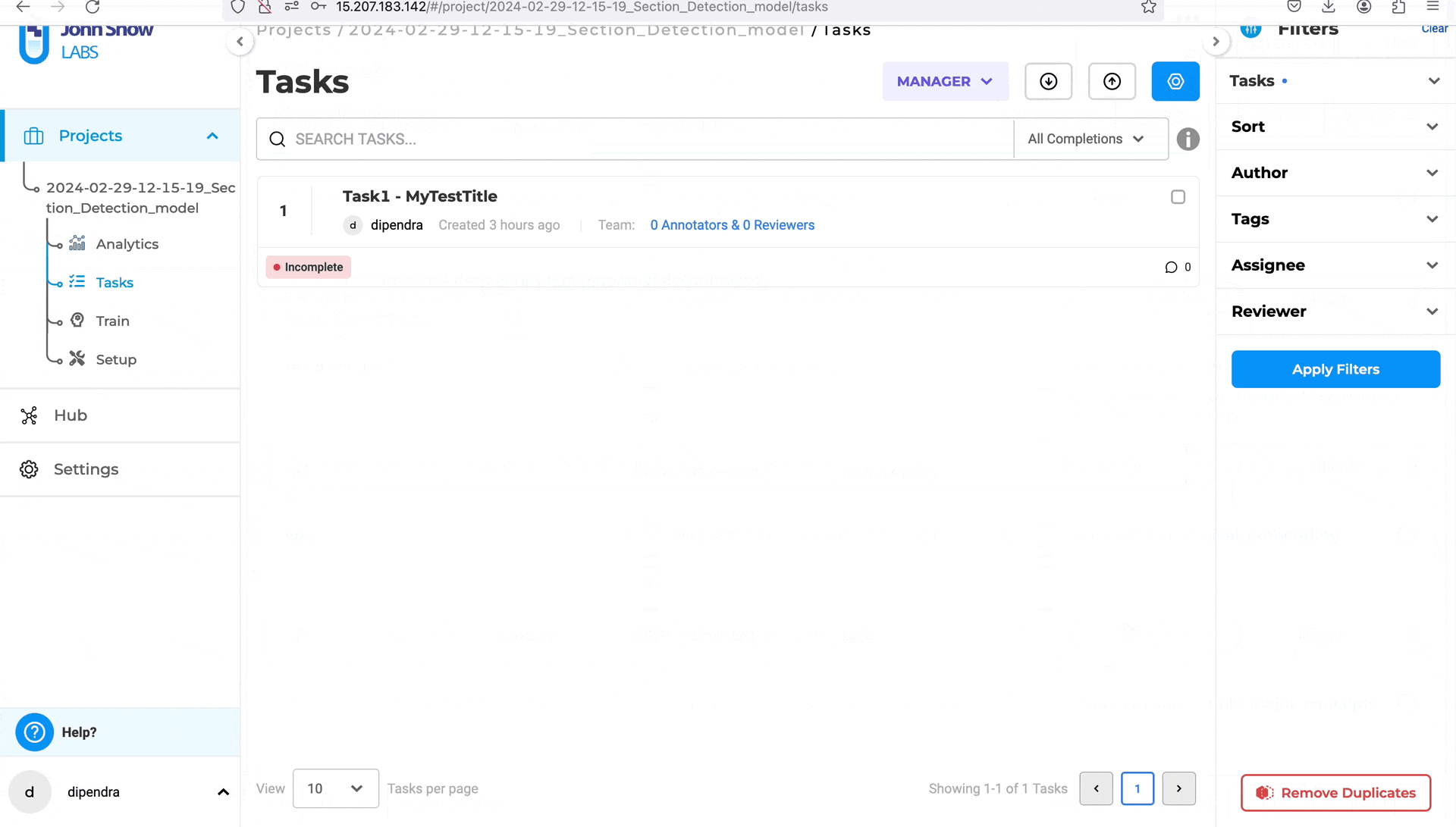
Import for Large Datasets
The background processing architecture now handles large-scale imports without UI disruption through intelligent format detection and dynamic resource allocation. When users upload tasks as a ZIP file or through a cloud source, Generative AI Lab automatically detects the format and uses the import server to handle the data in the background — ensuring smooth and efficient processing, even for large volumes.
For smaller, individual files — whether selected manually or added via drag-and-drop — imports are handled directly without background processing, allowing for quick and immediate task creation.
Note: Background import is applied only for ZIP and cloud-based imports.
Automatic Processing Mode Selection:
- ZIP files and cloud-based imports: Automatically routed to background processing via dedicated import server
- Individual files (manual selection or drag-and-drop): Processed directly for immediate task creation
- The system dynamically determines optimal processing path based on import source and volume
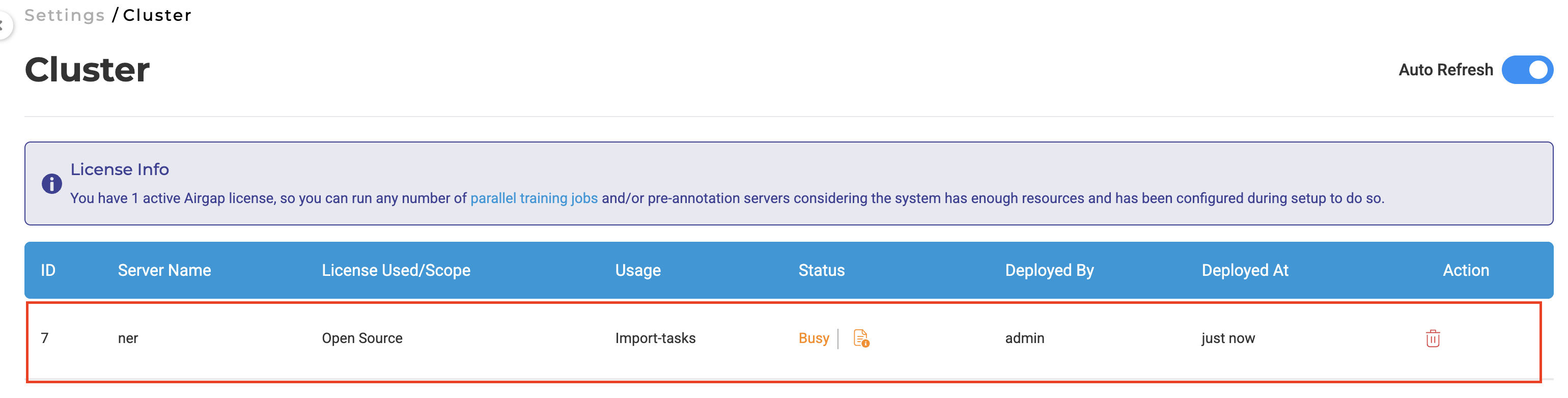
Technical Architecture:
- Dedicated import cluster with auto-provisioning: 2 CPUs, 5GB memory (non-configurable)
- Cluster spins up automatically during ZIP and cloud imports
- Automatic deallocation upon completion to optimize resource utilization
- Sequential file processing methodology reduces system load and improves reliability
- Import status is tracked and visible on the Import page, allowing users to easily monitor progress and confirm successful uploads.
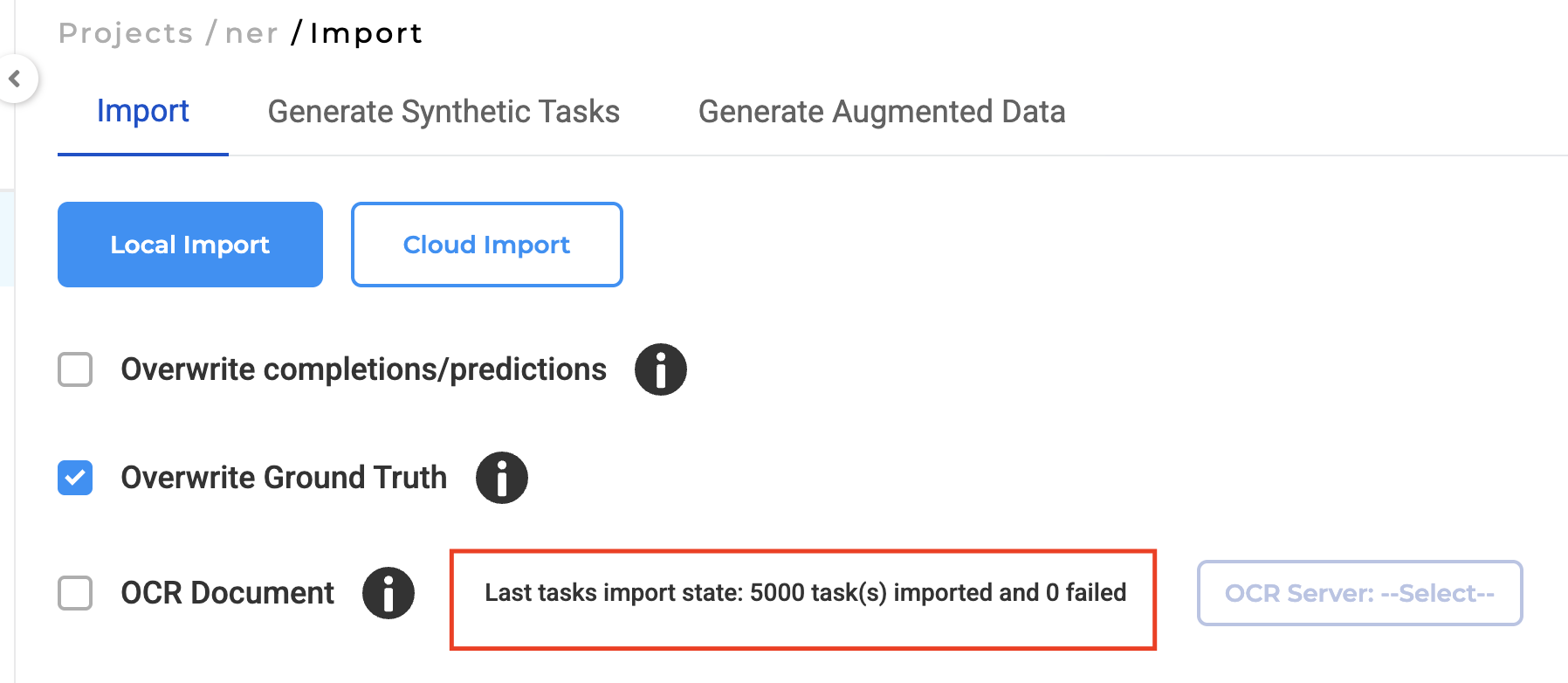
Performance Improvements:
- Large dataset imports (5000+ files): Previously 20+ minutes, now less than 10 minutes
- Elimination of UI freezing during bulk operations
- Improved system stability under high-volume import loads
Note: Import server created during task import is counted as an active server.
PDF Text Extraction for NER Projects
For NER text-based projects, the Import page includes a built-in “Text Extraction from PDFs” option that extracts text directly from PDFs and image-based documents without requiring a separate OCR server deployment.

This feature provides:
- Out-of-the-box text extraction from PDFs, scanned documents, and image-based files
- Preserved document structure including logical reading order, paragraph boundaries, and sections
- Stable and consistent output optimized for NER annotation workflows
- No additional setup required extraction happens during the import process
Configuration Requirement
To support the improved text formatting, the project configuration must include the following XML setup in the Customize Configuration view:
<View style="display: block; font-family: monospace; white-space: pre;">
<Text name="text" value="$text"/>
</View>

Note: This feature is currently available only for text-based NER projects. For Visual NER projects, use the standard PDF import workflow which preserves the visual document format.
Flexible OCR Strategy
The built-in text extraction handles standard PDF workflows reliably with no additional setup. For teams that need higher precision, such as domain-specific documents, complex layouts, or strict accuracy requirements advanced OCR capabilities from John Snow Labs are available as a seamless upgrade through licensed OCR servers.
Disabled Local Imports
Administrators can disable local file imports system-wide, complementing existing local export restrictions to create complete data flow control.
Technical Implementation:
- Control via the “Disable Local Import” setting in System Settings → General tab
- Project-level exceptions are available through the dedicated Exceptions widget
- When this option is enabled, only cloud storage imports (Amazon S3, Azure Blob Storage) are permitted.
- Setting applies globally across all projects unless explicitly exempted
User Benefits:
- Healthcare Organizations: Ensures all patient data flows through auditable, encrypted cloud channels rather than local file systems.
- Enterprise Teams: Eliminates the risk of sensitive data being imported from uncontrolled local sources.
- Compliance Officers: Provides granular control over data ingress while maintaining operational flexibility for approved projects.