5.4.0
Release date: 15-07-2024
Visual NLP 5.4.0 Release Notes 🕶️
we’re glad to announce that Visual NLP 5.4.0 has been released. New transformers, notebooks, metrics, bug fixes and more!!! 📢📢📢
Highlights 🔴
- Improvements in Table Processing.
- Dicom Transformers access to S3 directly.
- New Options for ImageToPdf transformer.
- Support for rotated text regions in ImageToTextV2.
- New Pdf-To-Pdf Pretrained Pipeline for De-Identification.
- ImageToTextV3 support for HOCR output.
- Performance Metrics for De-identification Pipelines.
- Other Changes.
Improvements in Table Processing
New RegionsMerger component for merging Text Regions and Cell Regions to improve accuracy in Table Extraction Pipelines:
| PretrainedPipeline | Score Improvement(*) | Comments |
|---|---|---|
| table_extractor_image_to_text_v2 | 0.34 to 0.5 | Internally it uses ImageToTextV2(case insensitive) |
| table_extractor_image_to_text_v1 | 0.711 to 0.728 | Internally it uses ImageToText(case sensitive) |
(*) This is the cell adjacency Table Extraction metric as defined by ICDAR Table Extraction Challenge. The improvements are measured against previous release of Visual NLP.
Dicom Transformers access to S3 directly
Now Dicom Transformers can access S3 directly from executors instead of reading through the Spark Dataframe. This is particularly advantageous in the situation where we only care about the metadata of each file because we don’t need to load the entire file into memory, also,
- It reduces memory usage and allows processing of files larger than 2 GB (a limitation of Spark).
- It improves performance when computing statistics over large DICOM datasets.
\
New Options for ImageToPdf transformer.
New options have been added to ImageToPdf. ImageToPdf is the transformer we use to create PDFs from images, we use it for example when we de-identify PDFs and we want to write back to the PDF to obtain a redacted version of the PDF. The new options are intended to control the size of the resulting PDF document by controlling the resolution and compression of the images that are included in the PDF,
-
compression: Compression type for images in PDF document. It can be one of
CompressionType.LOSSLESS,CompressionType.JPEG. -
resolution: Resolution in DPI used to render images into the PDF document. There are three sources for the resolution(in decreasing order or precedence): this parameter, the image schema in the input image, or the default value of 300DPI.
-
quality: Quality of images in PDF document for JPEG compression. A value that ranges between 1.0(best quality) to 0.0(best compression). Defaults to 0.75.
-
aggregatePages: Aggregate pages in one PDF document.
Support for rotated text regions in ImageToTextV2
Text regions at the input of ImageToTextV2 support rotation. Detected text regions come with an angle to represent the rotation that the detected text has in the image.
Now, this angle is used to extract a straightened version of the region, and fed to the OCR. The resulting text is placed into the returned output text using the center of the region to decide its final location.
See the following example,
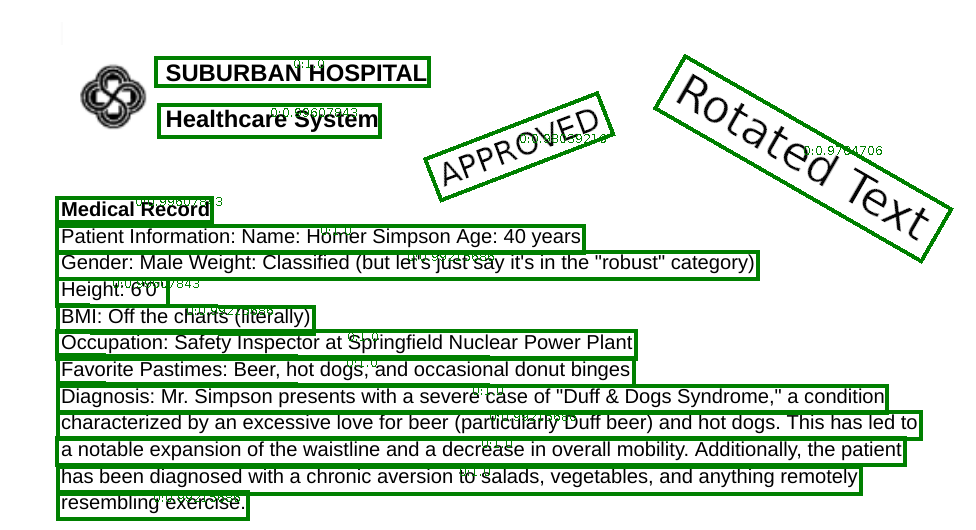
and the resulting(truncated) text,
SUBURBAN HOSPITAL
HEALTHCARE SYSTEM
APPROVED ROTATED TEXT
MEDICAL RECORD
PATIENT INFORMATION: NAME: HOMER SIMPSON AGE: 40 YEARS
GENDER: MALE WEIGHT: CLASSIFIED (BUT LET'S JUST SAY ITS IN THE "ROBUST" CATEGORY)
HEIGHT: 6'0"
BML: OFF THE CHARTS (LITERALLY)
OCCUPATION: SAFETY INSPECTOR AT SPRINGFIELD NUCLEAR POWER PLANT
New Pdf-To-Pdf Pretrained Pipelines for De-Identification.
New de-ideintification pipeline that consumes PDFs and produces de-identified PDFs: pdf_deid_pdf_output.
For a description of this pipeline please check its
card on Models Hub, and also this notebook example.
ImageToTextV3 support for HOCR output
ImageToTextV3 is an LSTM based OCR model that can consume high quality text regions to perform the text recognition. Adding HOCR support to this annotator, allows it to be placed in HOCR pipelines like Visual NER or Table Extraction. Main advantage compared to other OCR models is case sensitivity, and high recall due to the use of independent Text Detection models. Check an example here
Performance Metrics for Deidentification Pipelines
In order to make it easier for users to estimate runtime figures, we have published the following metrics. This metrics corresponds to a pipeline that performs the following actions,
- Extract PDF pages as images.
- Perform OCR on these Images.
- Run NLP De-identification stages(embeddings, NER, etc).
- Maps PHI entities to regions.
- Writes PHI regions back to PDF. The goal is for these numbers to be used as proxies when estimating hardware requirements of new jobs.
Other Changes & Bug Fixes
- start() functions now accepts the new
apple_siliconparameter. apple_silicon: whether to use Apple Silicon binaries or not. Defaults to ‘False’. - Bug Fix: ImageDrawRegions removes image resolution after drawing regions.
- Bug Fix: RasterFormatException in ImageToTextV2.
- Bug Fix: PdfToTextTable, PptToTextTable, DocToTextTable didn’t include a
load()method.
Previous versions
- 6.4.2
- 6.4.0
- 6.3.0
- 6.0.0
- 5.5.0
- 5.4.2
- 5.4.1
- 5.4.0
- 5.3.2
- 5.3.1
- 5.3.0
- 5.2.0
- 5.1.2
- 5.1.0
- 5.0.2
- 5.0.1
- 5.0.0
- 4.4.4
- 4.4.3
- 4.4.2
- 4.4.1
- 4.4.0
- 4.3.3
- 4.3.0
- 4.2.4
- 4.2.1
- 4.2.0
- 4.1.0
- 4.0.2
- 4.0.0
- 3.14.0
- 3.13.0
- 3.12.0
- 3.11.0
- 3.10.0
- 3.9.1
- 3.9.0
- 3.8.0
- 3.7.0
- 3.6.0
- 3.5.0
- 3.4.0
- 3.3.0
- 3.2.0
- 3.1.0
- 3.0.0
- 1.11.0
- 1.10.0
- 1.9.0
- 1.8.0
- 1.7.0
- 1.6.0
- 1.5.0
- 1.4.0
- 1.3.0
- 1.2.0
- 1.1.2
- 1.1.1
- 1.1.0
- 1.0.0