5.2.0
Release date: 23-02-2024
Visual NLP 5.2.0 Release Notes 🕶️
We are glad to announce that Visual NLP 5.2.0 has been released. This release comes with new models, bug fixes, blog posts, and more!! 📢📢📢
Highlights 🔴
- New Chart-To-Text dePlot based models.
- Support for Confidence Scores in Visual Question Answering Models.
- Improved stability and new metrics for ImageToTextV2 models.
- New Blog Post on ImageToTextV2 models.
- Docker image for Visual NLP.
- New Pretrained pipeline basic_table_extractor
- Spark 3.5 support.
- Bug Fixes
- Other Changes
New Chart-To-Text dePlot based models 📈
Chart To Text is the task of converting an image chart into a serialized textual version representation of the chart. To understand this, consider the following example,
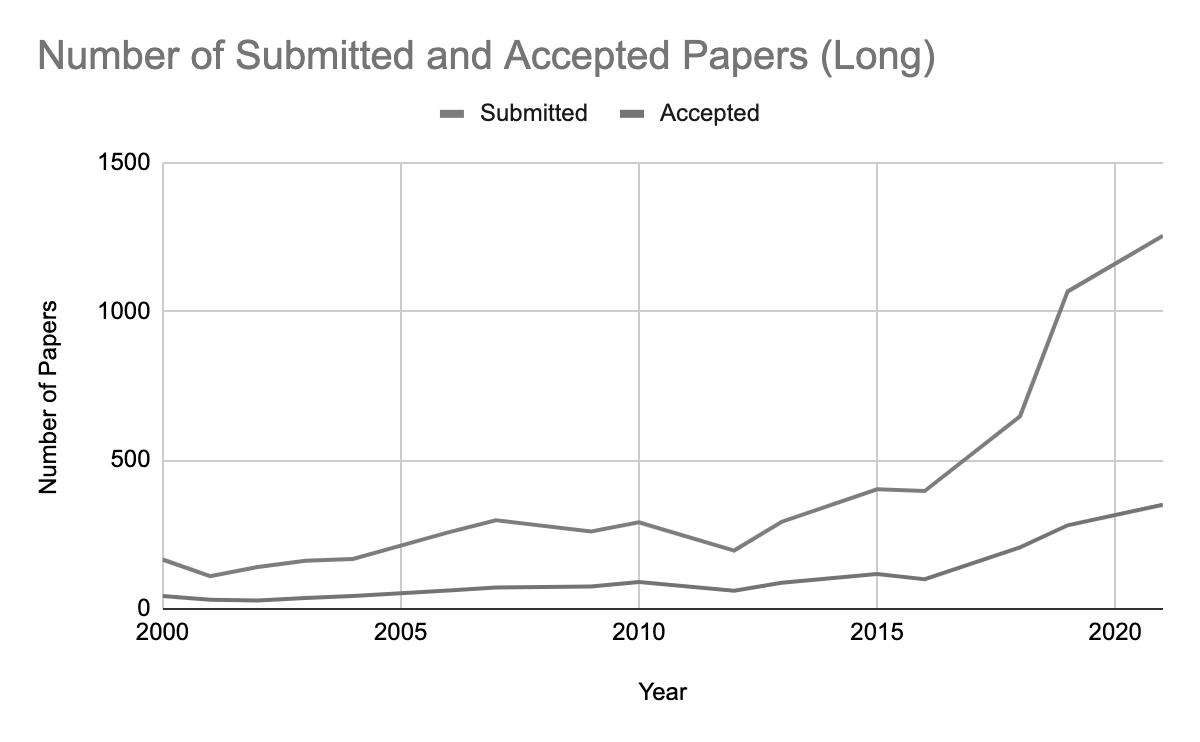
Maps to the following text based representation,
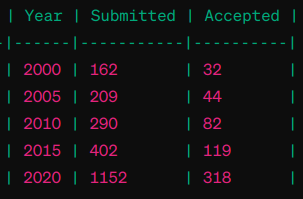
For an end-to-end example, please check this notebook.
Support for Confidence Scores in Visual Question Answering Models. 📍
Now, VisualQuestionAnswering models support confidence scores. The output schema for VisualQuestionAnswering models has been updated to include questions, answers and confidence scores. To enable confidence scores in the output of these models you should call setConfidenceScore(true). For example,

shows the schema and sample output for the case of two questions, with their corresponding answers and confidence scores.
Improved stability and new metrics for ImageToTextV2 models. ⚡️
ImageToTextV2, our Transformer-based OCR has been improved, and extensively stress tested for stability and reliability. These are the latest metrics for accuracy and runtime performance for all checkpoints,
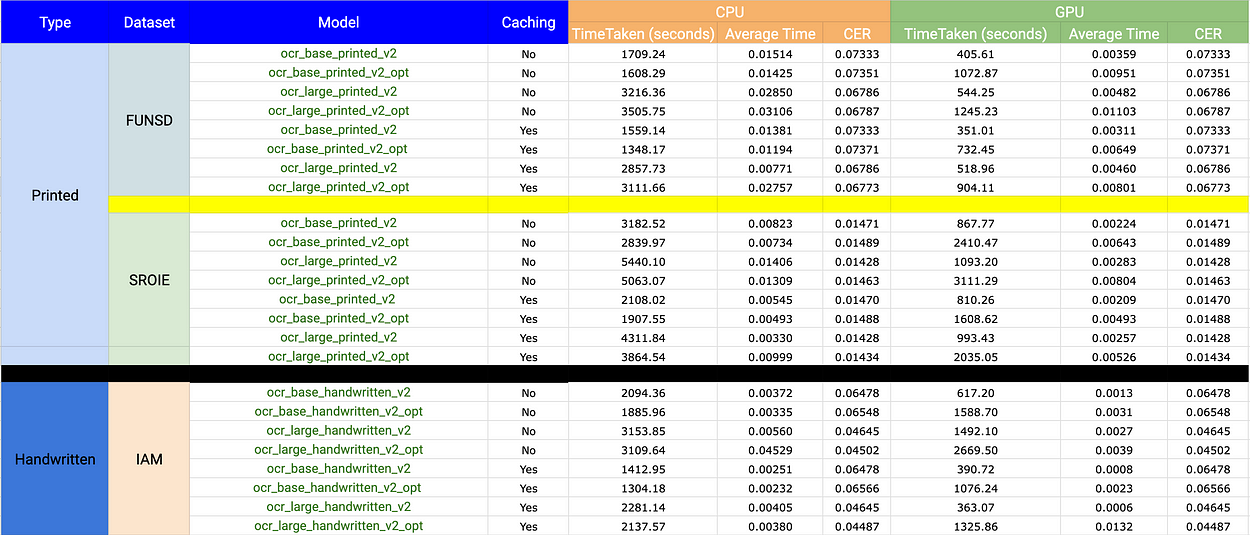
A key takeaway from this chart is the following: The [Dbu/h] is four times higher for CPU compared to GPU, with no variance in accuracy. Utilizing GPU can achieve identical outcomes at one-fourth of the cost. GPU is your friend!
New Blog Post in ImageToTextV2 models. 💥
Want to learn about the best practices to scale out your OCR pipelines?. Read the full article here.
Docker image for Visual NLP. 🔥
For users that require running inside a container we have created the following instructions and sample notebook.
New Pretrained pipeline basic_table_extractor
This is a complete Table Extraction Pipeline. Following, it’s a basic example of how to call this pipeline,
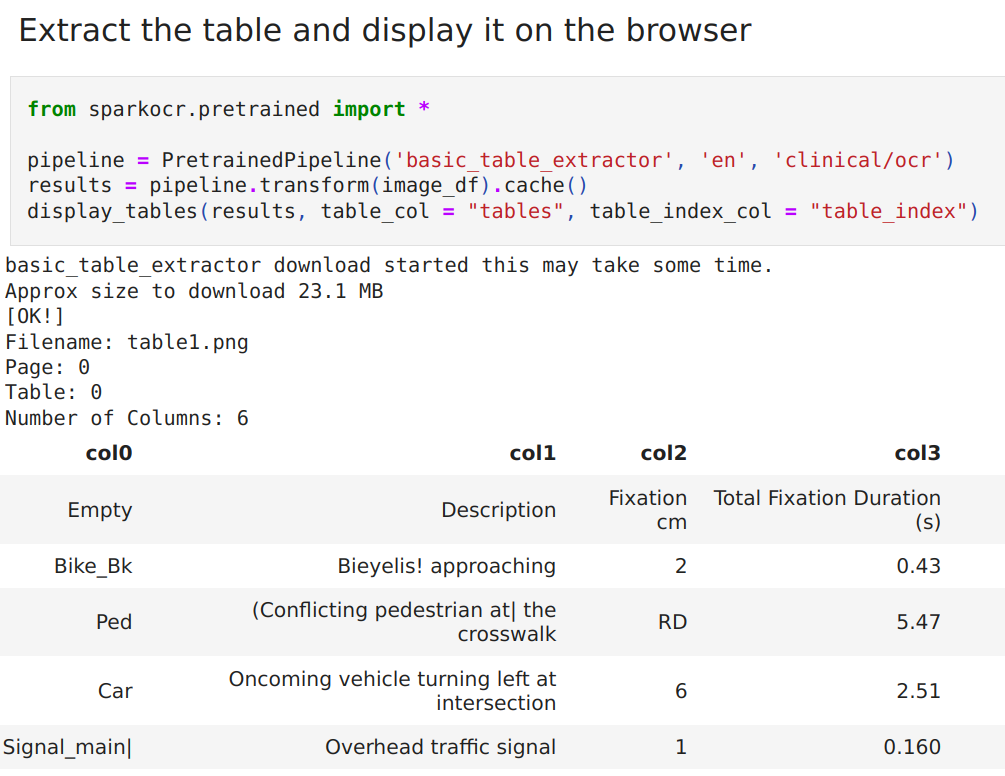
And you should also check the full example in this notebook.
Spark 3.5 support 🎯
We extended support to Apache Spark 3.5. All tests were run using Spark 3.5 and Python 3.10.
Other Changes
- Pix2struct models now support caching, both docvqa_pix2struct_jsl and docvqa_pix2struct_jsl_opt pix2struct based checkpoints now support caching, which is enabled by default.
- This release is compatible with
Spark NLP 5.2.2and Spark NLP forHealthcare 5.2.1
Previous versions
- 6.4.2
- 6.4.0
- 6.3.0
- 6.0.0
- 5.5.0
- 5.4.2
- 5.4.1
- 5.4.0
- 5.3.2
- 5.3.1
- 5.3.0
- 5.2.0
- 5.1.2
- 5.1.0
- 5.0.2
- 5.0.1
- 5.0.0
- 4.4.4
- 4.4.3
- 4.4.2
- 4.4.1
- 4.4.0
- 4.3.3
- 4.3.0
- 4.2.4
- 4.2.1
- 4.2.0
- 4.1.0
- 4.0.2
- 4.0.0
- 3.14.0
- 3.13.0
- 3.12.0
- 3.11.0
- 3.10.0
- 3.9.1
- 3.9.0
- 3.8.0
- 3.7.0
- 3.6.0
- 3.5.0
- 3.4.0
- 3.3.0
- 3.2.0
- 3.1.0
- 3.0.0
- 1.11.0
- 1.10.0
- 1.9.0
- 1.8.0
- 1.7.0
- 1.6.0
- 1.5.0
- 1.4.0
- 1.3.0
- 1.2.0
- 1.1.2
- 1.1.1
- 1.1.0
- 1.0.0