4.2.1
Release date: 11-28-2022
We’re glad to announce that Spark-OCR 4.2.1 has been released! This release is almost completely about LightPipelines.
LightPipeline added to Spark-OCR
Originally introduced by Spark-NLP, this has been one of the most celebrated features by our users. In a nutshell, LightPipelines allow you switching your pipeline from distributed processing to local mode, in a single line of code. Also, results are much easier to post-process as they come in plain Python data structures.
Now, LightPipelines are available in Spark-OCR as well! This is an initial implementation only covering three of our most popular annotators: ImageToText, PdfToImage, and BinaryToImage. Although not all the annotators from Spark-OCR are included in this initial release, a number of interesting features are being delivered:
- Latency has been dramatically reduced for small input dataset sizes.
- Interoperability with Spark-NLP and Spark-NLP healthcare: you can mix any NLP annotator with supported OCR annotators on the same LightPipeline.
Following is a chart comparing performance of different techniques on batches of different page counts: 8, 16, 24, 32, 40, 48, and 80 pages.
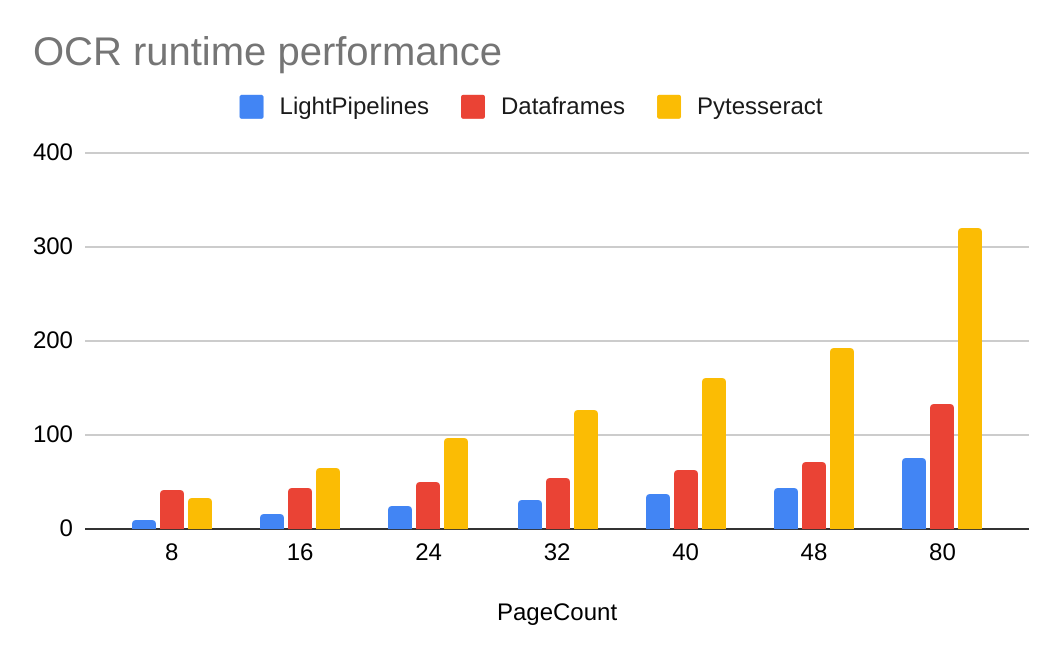
For the 8 pages case, on the left side of the chart, LightPipelines average 1.25s per page vs. 4s per page that were scored by a similar Pytesseract implementation. That makes LightPipelines a great candidate to achieve low latency on small sized batches, while still leveraging parallelism.
Korean Support
You can start using Korean language by just passing the ‘KOR’ option to ImageToText,
...
# Run OCR
ocr = ImageToText()
# Set Korean language
ocr.setLanguage(Language.KOR)
# Download model from JSL S3
ocr.setDownloadModelData(True)
Bug Fixes
- AlabReader has been updated to handle the new structure present in Annotation Lab’s exported annotations.
New Notebooks
- Check how to use LightPipelines in this notebook: SparkOcrLightPipelines.ipynb
Versions
- 6.4.2
- 6.4.0
- 6.3.0
- 6.0.0
- 5.5.0
- 5.4.2
- 5.4.1
- 5.4.0
- 5.3.2
- 5.3.1
- 5.3.0
- 5.2.0
- 5.1.2
- 5.1.0
- 5.0.2
- 5.0.1
- 5.0.0
- 4.4.4
- 4.4.3
- 4.4.2
- 4.4.1
- 4.4.0
- 4.3.3
- 4.3.0
- 4.2.4
- 4.2.1
- 4.2.0
- 4.1.0
- 4.0.2
- 4.0.0
- 3.14.0
- 3.13.0
- 3.12.0
- 3.11.0
- 3.10.0
- 3.9.1
- 3.9.0
- 3.8.0
- 3.7.0
- 3.6.0
- 3.5.0
- 3.4.0
- 3.3.0
- 3.2.0
- 3.1.0
- 3.0.0
- 1.11.0
- 1.10.0
- 1.9.0
- 1.8.0
- 1.7.0
- 1.6.0
- 1.5.0
- 1.4.0
- 1.3.0
- 1.2.0
- 1.1.2
- 1.1.1
- 1.1.0
- 1.0.0