Schemas
Image Schema
Images are loaded as a DataFrame with a single column called “image.”
It is a struct-type column, that contains all information about image:
image: struct (nullable = true)
| |-- origin: string (nullable = true)
| |-- height: integer (nullable = false)
| |-- width: integer (nullable = false)
| |-- nChannels: integer (nullable = false)
| |-- mode: integer (nullable = false)
| |-- resolution: integer (nullable = true)
| |-- data: binary (nullable = true)
Fields
| Field name | Type | Description |
|---|---|---|
| origin | string | source URI |
| height | integer | image height in pixels |
| width | integer | image width in pixels |
| nChannels | integer | number of color channels |
| mode | ImageType | the data type and channel order the data is stored in |
| resolution | integer | resolution of image in dpi |
| data | binary | image data in a binary format |
NOTE: Image data stored in a binary format. Image data is represented
as a 3-dimensional array with the dimension shape (height, width, nChannels)
and array values of type t specified by the mode field.
Coordinate Schema
element: struct (containsNull = true)
| | |-- index: integer (nullable = false)
| | |-- page: integer (nullable = false)
| | |-- x: float (nullable = false)
| | |-- y: float (nullable = false)
| | |-- width: float (nullable = false)
| | |-- height: float (nullable = false)
| Field name | Type | Description |
|---|---|---|
| index | integer | Chunk index |
| page | integer | Page number |
| x | float | The lower left x coordinate |
| y | float | The lower left y coordinate |
| width | float | The width of the rectangle |
| height | float | The height of the rectangle |
| score | float | The score of the object |
| label | string | The label of the object |
PageMatrix Schema
element: struct (containsNull = true)
| | |-- mappings: array[struct] (nullable = false)
| Field name | Type | Description |
|---|---|---|
| mappings | Array[Mapping] | Array of mappings |
Mapping Schema
element: struct (containsNull = true)
| | |-- c: string (nullable = false)
| | |-- p: integer (nullable = false)
| | |-- x: float (nullable = false)
| | |-- y: float (nullable = false)
| | |-- width: float (nullable = false)
| | |-- height: float (nullable = false)
| | |-- fontSize: integer (nullable = false)
| Field name | Type | Description |
|---|---|---|
| c | string | Character |
| p | integer | Page number |
| x | float | The lower left x coordinate |
| y | float | The lower left y coordinate |
| width | float | The width of the rectangle |
| height | float | The height of the rectangle |
| fontSize | integer | Font size in points |
Enums
PageSegmentationMode
- OSD_ONLY: Orientation and script detection only.
- AUTO_OSD: Automatic page segmentation with orientation and script detection.
- AUTO_ONLY: Automatic page segmentation, but no OSD, or OCR.
- AUTO: Fully automatic page segmentation, but no OSD.
- SINGLE_COLUMN: Assume a single column of text of variable sizes.
- SINGLE_BLOCK_VERT_TEXT: Assume a single uniform block of vertically aligned text.
- SINGLE_BLOCK: Assume a single uniform block of text.
- SINGLE_LINE: Treat the image as a single text line.
- SINGLE_WORD: Treat the image as a single word.
- CIRCLE_WORD: Treat the image as a single word in a circle.
- SINGLE_CHAR: Treat the image as a single character.
- SPARSE_TEXT: Find as much text as possible in no particular order.
- SPARSE_TEXT_OSD: Sparse text with orientation and script detection.
EngineMode
- TESSERACT_ONLY: Legacy engine only.
- OEM_LSTM_ONLY: Neural nets LSTM engine only.
- TESSERACT_LSTM_COMBINED: Legacy + LSTM engines.
- DEFAULT: Default, based on what is available.
PageIteratorLevel
- BLOCK: Block of text/image/separator line.
- PARAGRAPH: Paragraph within a block.
- TEXTLINE: Line within a paragraph.
- WORD: Word within a text line.
- SYMBOL: Symbol/character within a word.
Language
- ENG: English
- FRA: French
- SPA: Spanish
- RUS: Russian
- DEU: German
- VIE: Vietnamese
- ARA: Arabic
ModelType
- BASE: Block of text/image/separator line.
- BEST: Paragraph within a block.
- FAST: Line within a paragraph.
ImageType
- TYPE_BYTE_GRAY
- TYPE_BYTE_BINARY
- TYPE_3BYTE_BGR
- TYPE_4BYTE_ABGR
NoiseMethod
- VARIANCE
- RATIO
KernelShape
- SQUARE
- DIAMOND
- DISK
- OCTAHEDRON
- OCTAGON
- STAR
MorphologyOperationType
- OPENING
- CLOSING
- EROSION
- DILATION
CropSquareType
- TOP_LEFT
- TOP_CENTER
- TOP_RIGHT
- CENTER_LEFT
- CENTER
- CENTER_RIGHT
- BOTTOM_LEFT
- BOTTOM_CENTER
- BOTTOM_RIGHT
SplittingStrategy
- FIXED_NUMBER_OF_PARTITIONS
- FIXED_SIZE_OF_PARTITION
AdaptiveThresholdingMethod
- GAUSSIAN
- MEAN
- MEDIAN
- WOLF
- SINGH
TresholdingMethod
- GAUSSIAN
- OTSU
- SAUVOLA
- WOLF
CellDetectionAlgos
- CONTOURS - Detect cells in bordered tables
- MORPHOPS - Detected calls in: bordered, borderless and combined tables
TableOutputFormat
- TABLE - Table struct format
- CSV - Comma separated CSV
Parameters
| Param name | Type | Default | Description |
|---|---|---|---|
| outputCol | string | image | output column name |
| contentCol | string | content | input column name with binary content |
| pathCol | string | path | input column name with path to original file |
Example:
import com.johnsnowlabs.ocr.OcrContext.implicits._
val imagePath = "path to image"
// Read image file as binary file
val df = spark.read
.format("binaryFile")
.load(imagePath)
.asImage("image")
df.show()
storeImage
storeImage stores the image(s) to tmp location and return Dataset with path(s) to stored image files.
Parameters
| Param name | Type | Default | Description |
|---|---|---|---|
| inputColumn | string | input column name with image struct | |
| formatName | string | png | image format name |
| prefix | string | sparknlp_ocr_ | prefix for output file |
Example:
import com.johnsnowlabs.ocr.OcrContext.implicits._
val imagePath = "path to image"
// Read image file as binary file
val df = spark.read
.format("binaryFile")
.load(imagePath)
.asImage("image")
df.storeImage("image")
showImages
Show images on Databrics notebook.
Parameters
| Param name | Type | Default | Description |
|---|---|---|---|
| field | string | image | input column name with image struct |
| limit | integer | 5 | count of rows for display |
| width | string | “800” | width of image |
| show_meta | boolean | true | enable/disable displaying metadata of image |
Jupyter Python helpers
display_image
Show single image with metadata in Jupyter notebook.
Parameters
| Param name | Type | Default | Description |
|---|---|---|---|
| width | string | “600” | width of image |
| show_meta | boolean | true | enable/disable displaying metadata of image |
Example:
from sparkocr.utils import display_image
from sparkocr.transformers import BinaryToImage
images_path = "/tmp/ocr/images/*.tif"
images_example_df = spark.read.format("binaryFile").load(images_path).cache()
display_image(BinaryToImage().transform(images_example_df).collect()[0].image)
display_images
Show images from dataframe.
Parameters
| Param name | Type | Default | Description |
|---|---|---|---|
| field | string | image | input column name with image struct |
| limit | integer | 5 | count of rows for display |
| width | string | “600” | width of image |
| show_meta | boolean | true | enable/disable displaying metadata of image |
Example:
from sparkocr.utils import display_images
from sparkocr.transformers import BinaryToImage
images_path = "/tmp/ocr/images/*.tif"
images_example_df = spark.read.format("binaryFile").load(images_path).cache()
display_images(BinaryToImage().transform(images_example_df), limit=3)
display_images_horizontal
Show one or more images per row from dataframe.
Parameters
| Param name | Type | Default | Description |
|---|---|---|---|
| fields | string | image | comma separated input column names with image struct |
| limit | integer | 5 | count of rows for display |
| width | string | “600” | width of image |
| show_meta | boolean | true | enable/disable displaying metadata of image |
Example:
from sparkocr.utils import display_images_horizontal
display_images_horizontal(df_with_few_image_fields, fields="images, image_with_regions", limit=10)
display_pdf
Show pdf from dataframe.
Parameters
| Param name | Type | Default | Description |
|---|---|---|---|
| field | string | content | input column with binary representation of pdf |
| limit | integer | 5 | count of rows for display |
| width | string | “600” | width of image |
| show_meta | boolean | true | enable/disable displaying metadata of image |
Example:
from sparkocr.utils import display_pdf
pdf_df = spark.read.format("binaryFile").load(pdf_path)
display_pdf(pdf_df)
display_pdf_file
Show pdf file using embedded pdf viewer.
Parameters
| Param name | Type | Default | Description |
|---|---|---|---|
| string | Path to the file name | ||
| size | integer | size=(600, 500) | count of rows for display |
Example:
from sparkocr.utils import display_pdf_file
display_pdf_file("path to the pdf file")
Example output:
display_table
Display table from the dataframe.
display_tables
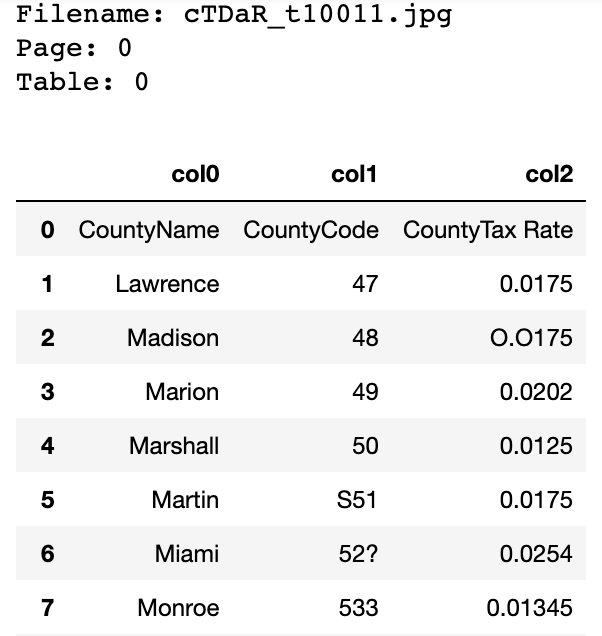
Display tables from the dataframe. It is useful for display results of table recognition from the multipage documents/few tables per page.
Example output:
Databricks Python helpers
display_images
Show images from dataframe.
Parameters
| Param name | Type | Default | Description |
|---|---|---|---|
| field | string | image | input column name with image struct |
| limit | integer | 5 | count of rows for display |
| width | string | “800” | width of image |
| show_meta | boolean | true | enable/disable displaying metadata of image |
Example:
from sparkocr.databricks import display_images
from sparkocr.transformers import BinaryToImage
images_path = "/tmp/ocr/images/*.tif"
images_example_df = spark.read.format("binaryFile").load(images_path).cache()
display_images(BinaryToImage().transform(images_example_df), limit=3)
