5.3.1
Release date: 11-04-2024
Visual NLP 5.3.1 Release Notes 🕶️
we’re glad to announce that Visual NLP 5.3.1 has been released. New models, notebooks, bug fixes and more!!! 📢📢📢
Highlights 🔴
- Improved table extraction capabilities in HocrToTextTable.
- Improvements in LightPipelines.
- Confidence scores in ImageToTextV2.
- New HocrMerger annotator.
- Checkbox detection in Visual NER.
- New Document Clustering Pipeline using Vit Embeddings.
- Enhancements to color options in ImageDrawRegions.
- New notebooks & updates.
- Bug Fixes.
Improved table extraction capabilities in HocrToTextTable
Many issues related to column detection in our Table Extraction pipelines are addressed in this release, compared to previous Visual NLP version the metrics have improved. Table below shows F1-score(CAR or Cell Adjacency Relationship) performances on ICDAR 19 Track B dataset for different IoU values of our two versions in comparison with other results.
| Model | 0.6 | 0.7 | 0.8 | 0.9 |
|---|---|---|---|---|
| CascadeTabNet | 0.438 | 0.354 | 0.19 | 0.036 |
| NLPR-PAL | 0.365 | 0.305 | 0.195 | 0.035 |
| Multi-Type-TD-TSR | 0.589 | 0.404 | 0.137 | 0.015 |
| Visual NLP 5.3.0 | 0.463 | 0.420 | 0.355 | 0.143 |
| Visual NLP 5.3.1 | 0.509 | 0.477 | 0.403 | 0.162 |
Improvements in LightPipelines
- ImageSplitRegions, ImageToTextV2, ImageTextDetectorCraft are now supported to be used with LightPipelines.
- New
Base64ToBinary()annotator to enable the use of in-memory base64 string buffers as input to LightPipelines.
from sparkocr.enums import ImageType
# Transform base64 to binary
base64_to_bin = Base64ToBinary()
base64_to_bin.setOutputCol("content")
pdf_to_image = PdfToImage()
pdf_to_image.setInputCol("content")
pdf_to_image.setOutputCol("image")
# Run OCR for each region
ocr = ImageToText()
ocr.setInputCol("image")
ocr.setOutputCol("text")
# OCR pipeline
pipeline = PipelineModel(stages=[
base64_to_bin,
pdf_to_image,
ocr
])
lp = LightPipeline(pipeline)
result = lp.fromString(base64_pdf)
- new
LightPipeline.fromBinary()method that allows the usage of in-memory binary buffers as inputs to Visual NLP pipelines.
\
Confidence scores in ImageToTextV2
You can now enable confidence scores in ImageToTextV2 like this,
ocr = ImageToTextV2.pretrained("ocr_base_printed_v2_opt", "en", "clinical/ocr") \
.setIncludeConfidence(True)
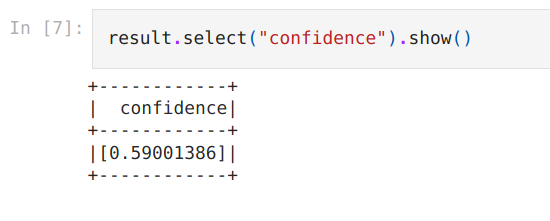
Check this updated notebook for an end-to-end example.
New HocrMerger annotator
HocrMerger is a new annotator whose purpose is to allow merging two streams of HOCRs texts into a single unified HOCR representation. This allows mixing object detection models with text to create a unified document representation that can be fed to other downstream models like Visual NER. The new Checkbox detection pipeline uses this approach.
Checkbox detection in Visual NER.
A new Checkbox detection model has been added to Visual NLP 5.3.1!. With this model you can detect checkboxes in documents and obtain an HOCR representation of them. This representation, along with the other elements in page can be fed to other models like Visual NER.
binary_to_image = BinaryToImage()
binary_to_image.setImageType(ImageType.TYPE_3BYTE_BGR)
check_box_detector = ImageCheckBoxDetector \
.pretrained("checkbox_detector_v1", "en", "clinical/ocr") \
.setInputCol("image") \
.setLabels(["No", "Yes"])
In this case we are receiving an image as input, and returning a HOCR representation with labels ‘Yes’, and ‘No’ to represent whether the checkbox is marked or not. You can see this idea directly in the following picture.

New Document Clustering Pipeline using Vit Embeddings.
Now we can use Vit Embeddings to create document representations for clustering.
binary_to_image = BinaryToImage() \
.setInputCol("content") \
.setOutputCol("image")
embeddings = VitImageEmbeddings \
.pretrained("vit_image_embeddings", "en", "clinical/ocr") \
.setInputCol("image") \
.setOutputCol("embeddings")
For an end-to-end example, please check this notebook.
Enhancements to color options in ImageDrawRegions.
ImageDrawRegions is the annotator used for rendering regions into images so we can visualize results from different models, like, for example, Text Detection. The setColorMap method, is used to set the colors of bounding boxes drawn at top of images, the new behavior is as follows,
- setColorMap: when called with a ‘*’ as argument, it will apply a single color to the bounding boxes of all labels.
- setColorMap: when called with a dictionary in the form: {label -> color}, it will apply a different color to each label. If a key is missing, it will pick a random value.
- setColorMap is not called: random colors will be picked for each label, each time you call transform() a new set of colors will be selected.
New notebooks & updates
Bug Fixes
- PdfToImage resetting page information when used in the same pipeline as PdfToText: When the sequence {PdfToText, PdfToImage} was used the original pages computed at PdfToText where resetted to zero by PdfToImage.
Previous versions
- 6.4.2
- 6.4.0
- 6.3.0
- 6.0.0
- 5.5.0
- 5.4.2
- 5.4.1
- 5.4.0
- 5.3.2
- 5.3.1
- 5.3.0
- 5.2.0
- 5.1.2
- 5.1.0
- 5.0.2
- 5.0.1
- 5.0.0
- 4.4.4
- 4.4.3
- 4.4.2
- 4.4.1
- 4.4.0
- 4.3.3
- 4.3.0
- 4.2.4
- 4.2.1
- 4.2.0
- 4.1.0
- 4.0.2
- 4.0.0
- 3.14.0
- 3.13.0
- 3.12.0
- 3.11.0
- 3.10.0
- 3.9.1
- 3.9.0
- 3.8.0
- 3.7.0
- 3.6.0
- 3.5.0
- 3.4.0
- 3.3.0
- 3.2.0
- 3.1.0
- 3.0.0
- 1.11.0
- 1.10.0
- 1.9.0
- 1.8.0
- 1.7.0
- 1.6.0
- 1.5.0
- 1.4.0
- 1.3.0
- 1.2.0
- 1.1.2
- 1.1.1
- 1.1.0
- 1.0.0