5.1.2
Release date: 03-01-2024
Visual NLP 5.1.2 Release Notes 🕶️
We are glad to announce that Visual NLP 5.1.2 has been released!TThis release comes with faster than ever OCR models, improved Table Extraction pipelines, bug fixes, and more! 📢📢📢
Highlights 🔴
- New optimized OCR checkpoints with up to 5x speed ups and GPU support.
- New improved Table Extraction Pipeline with improved Cell Detection stage.
- Other Changes.
- Bug fixes.
New optimized OCR checkpoints with up to 5x speed ups and GPU support 🚀
ImageToTextV2, is our Transformer-based OCR model which delivers SOTA accuracy across different pipelines like Text Extraction(OCR), Table Extraction, and Deidentification. </br> We’ve added new checkpoints together with more options to choose which optimizations to apply.
New checkpoints for ImageToTextV2 📍
All previous checkpoints have been updated to work with the latest optimizations, and in addition these 4 new checkpoints have been added,
- ocr_large_printed_v2_opt
- ocr_large_printed_v2
- ocr_large_handwritten_v2_opt
- ocr_large_handwritten_v2
These 4 checkpoints are more accurate than their ‘base’ counterparts. We are releasing metrics for the ‘base’ checkpoints today, and a full chart including these checkpoints will be presented in a blogpost to be released soon.
New options for ImageToTextV2 ⚡️
ImageToTextV2 now supports the following configurations:
- setUseCaching(Boolean): whether or not to use caching during processing.
- setBatchSize(Integer): the batch size dictates the size of the groups that are processes internally at a single time by the model, typically used when setUseGPU() is set to true.
Choosing the best checkpoint for your problem 💥
We put together this grid reflecting performance and accuracy metrics to help you choose the most appropriate checkpoint for your use case.
- Accuracy
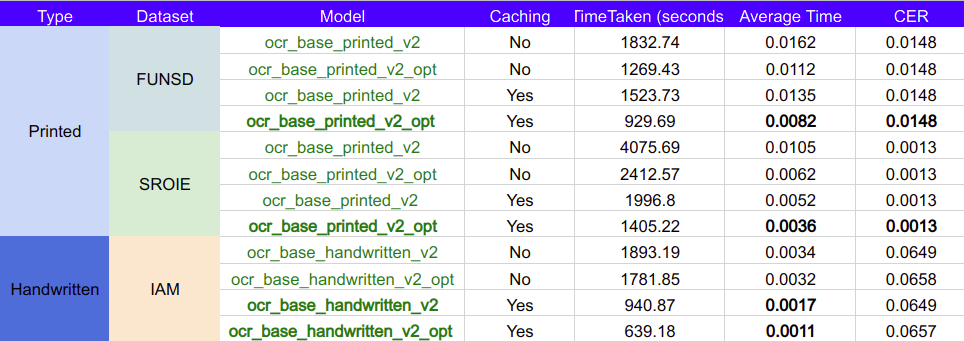
- Performance
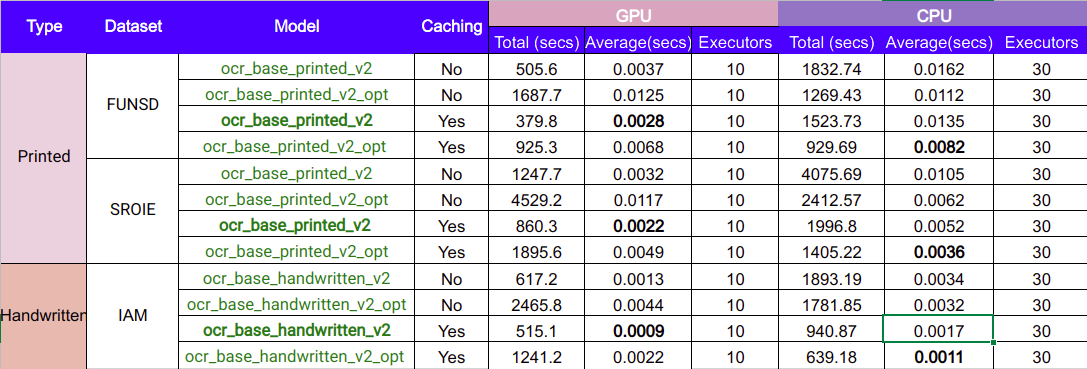
Note:
- CER: character error rate.
- These runtime performance metrics were collected in Databricks.
- The CPU cluster is a 30 node cluster of 64 DBU/h, and the GPU cluster is a 10 node cluster, of 15 DBU/h.
- Compared to previous releases, the optimizations introduced in this release yield a speed up of almost 5X, and a cost reduction of more than 4 times, if GPU is used.
New improved Table Extraction Pipeline with improved Cell Detection stage. 🔥
Starting in this release, our HocrToTextTable annotator can receive information related to cells regions to improve the quality of results in Table Extraction tasks. This is particularly useful for cases in which cells are multi-line, or for borderless tables. </br> This is what a pipeline would look like,
binary_to_image = BinaryToImage()
img_to_hocr = ImageToHocr() \
.setInputCol("image") \
.setOutputCol("hocr") \
.setIgnoreResolution(False) \
.setOcrParams(["preserve_interword_spaces=0"])
cell_detector = ImageDocumentRegionDetector() \
.pretrained("region_cell_detection", "en", "clinical/ocr") \
.setInputCol("image") \
.setOutputCol("cells") \
.setScoreThreshold(0.8)
hocr_to_table = HocrToTextTable() \
.setInputCol("hocr") \
.setRegionCol("table_regions") \
.setOutputCol("tables") \
.setCellsCol("cells")
PipelineModel(stages=[
binary_to_image,
img_to_hocr,
cell_detector
hocr_to_table])
The following image depicts intermediate cell detection along with the final result.

For a complete, end-to-end example we encourage you to check the sample notebook.
Other changes 🎯
- Dicom private tags in metadata now can be removed in DicomMetadataDeidentifier: calling setRemovePrivateTags(true) will cause the tags marked as private to be removed in the output Dicom document.
- Extended Spark support to 3.4.2.
- Turkish language now supported in ImageToText. To use it, set it by calling ImageToText.setLanguage(“tur”).
- start() function now supports the configuration of GPU through the boolean
use_gpuparameter. - Faster(20%), and smaller footprint,
docvqa_pix2struct_jsl_optVisual Question Answering checkpoint.
Bug Fixes 🪲
- ImageSplitRegions does not work after Table Detector.
- VisualDocumentNerLilt output has been fixed to include entire tokens instead of pieces.
- Null Regions in HocrToTextTable are handled properly.
- display_tables can now handle empty tables better.
- Vulnerabilities in Python dependencies.
- This release is compatible with
Spark NLP 5.2.0and Spark NLP forHealthcare 5.1.1
Previous versions
- 6.4.2
- 6.4.0
- 6.3.0
- 6.0.0
- 5.5.0
- 5.4.2
- 5.4.1
- 5.4.0
- 5.3.2
- 5.3.1
- 5.3.0
- 5.2.0
- 5.1.2
- 5.1.0
- 5.0.2
- 5.0.1
- 5.0.0
- 4.4.4
- 4.4.3
- 4.4.2
- 4.4.1
- 4.4.0
- 4.3.3
- 4.3.0
- 4.2.4
- 4.2.1
- 4.2.0
- 4.1.0
- 4.0.2
- 4.0.0
- 3.14.0
- 3.13.0
- 3.12.0
- 3.11.0
- 3.10.0
- 3.9.1
- 3.9.0
- 3.8.0
- 3.7.0
- 3.6.0
- 3.5.0
- 3.4.0
- 3.3.0
- 3.2.0
- 3.1.0
- 3.0.0
- 1.11.0
- 1.10.0
- 1.9.0
- 1.8.0
- 1.7.0
- 1.6.0
- 1.5.0
- 1.4.0
- 1.3.0
- 1.2.0
- 1.1.2
- 1.1.1
- 1.1.0
- 1.0.0