Usage examples of nlp.load()
The following examples demonstrate how to use nlu’s load api accompanied by the outputs generated by it.
It enables loading any model or pipeline in one line
You need to pass one NLU reference to the load method.
You can also pass multiple whitespace separated references.
You can find all NLU references here
Named Entity Recognition (NER) 18 class
Predicts the following 18 NER classes from the ONTO dataset :
| Type | Description |
|---|---|
| PERSON | People, including fictional like Harry Potter |
| NORP | Nationalities or religious or political groups like the Germans |
| FAC | Buildings, airports, highways, bridges, etc. like New York Airport |
| ORG | Companies, agencies, institutions, etc. like Microsoft |
| GPE | Countries, cities, states. like Germany |
| LOC | Non-GPE locations, mountain ranges, bodies of water. Like the Sahara desert |
| PRODUCT | Objects, vehicles, foods, etc. (Not services.) like playstation |
| EVENT | Named hurricanes, battles, wars, sports events, etc. like hurricane Katrina |
| WORK_OF_ART | Titles of books, songs, etc. Like Mona Lisa |
| LAW | Named documents made into laws. Like : Declaration of Independence |
| LANGUAGE | Any named language. Like Turkish |
| DATE | Absolute or relative dates or periods. Like every second friday |
| TIME | Times smaller than a day. Like every minute |
| PERCENT | Percentage, including ”%“. Like 55% of workers enjoy their work |
| MONEY | Monetary values, including unit. Like 50$ for those pants |
| QUANTITY | Measurements, as of weight or distance. Like this person weights 50kg |
| ORDINAL | “first”, “second”, etc. Like David placed first in the tournament |
| CARDINAL | Numerals that do not fall under another type. Like hundreds of models are avaiable in NLU |
nlp.load('ner').predict('Angela Merkel from Germany and the American Donald Trump dont share many opinions')
| embeddings | ner_tag | entities |
|---|---|---|
| [[-0.563759982585907, 0.26958999037742615, 0.3… | PER | Angela Merkel |
| [[-0.563759982585907, 0.26958999037742615, 0.3… | GPE | Germany |
| [[-0.563759982585907, 0.26958999037742615, 0.3… | NORP | American |
| [[-0.563759982585907, 0.26958999037742615, 0.3… | PER | Donald Trump |
Named Entity Recognition (NER) 5 Class
Predicts the following NER classes from the CONLL dataset :
| Tag | Description |
|---|---|
| B-PER | A person like Jim or Joe |
| B-ORG | An organisation like Microsoft or PETA |
| B-LOC | A location like Germany |
| B-MISC | Anything else like Playstation |
| O | Everything that is not an entity. |
nlp.load('ner.conll').predict('Angela Merkel from Germany and the American Donald Trump dont share many opinions')
| embeddings | ner_tag | entities |
|---|---|---|
| [[-0.563759982585907, 0.26958999037742615, 0.3… | PER | Angela Merkel |
| [[-0.563759982585907, 0.26958999037742615, 0.3… | LOC | Germany |
| [[-0.563759982585907, 0.26958999037742615, 0.3… | MISC | American |
| [[-0.563759982585907, 0.26958999037742615, 0.3… | PER | Donald Trump |
Part of speech (POS)
POS Classifies each token with one of the following tags
| Tag | Description | Example |
|---|---|---|
| CC | Coordinating conjunction | This batch of mushroom stew is savory and delicious |
| CD | Cardinal number | Here are five coins |
| DT | Determiner | The bunny went home |
| EX | Existential there | There is a storm coming |
| FW | Foreign word | I’m having a déjà vu |
| IN | Preposition or subordinating conjunction | He is cleverer than I am |
| JJ | Adjective | She wore a beautiful dress |
| JJR | Adjective, comparative | My house is bigger than yours |
| JJS | Adjective, superlative | I am the shortest person in my family |
| LS | List item marker | A number of things need to be considered before starting a business , such as premises , finance , product demand , staffing and access to customers |
| MD | Modal | You must stop when the traffic lights turn red |
| NN | Noun, singular or mass | The dog likes to run |
| NNS | Noun, plural | The cars are fast |
| NNP | Proper noun, singular | I ordered the chair from Amazon |
| NNPS | Proper noun, plural | We visted the Kennedys |
| PDT | Predeterminer | Both the children had a toy |
| POS | Possessive ending | I built the dog’s house |
| PRP | Personal pronoun | You need to stop |
| PRP$ | Possessive pronoun | Remember not to judge a book by its cover |
| RB | Adverb | The dog barks loudly |
| RBR | Adverb, comparative | Could you sing more quietly please? |
| RBS | Adverb, superlative | Everyone in the race ran fast, but John ran the fastest of all |
| RP | Particle | He ate up all his dinner |
| SYM | Symbol | What are you doing ? |
| TO | to | Please send it back to me |
| UH | Interjection | Wow! You look gorgeous |
| VB | Verb, base form | We play soccer |
| VBD | Verb, past tense | I worked at a restaurant |
| VBG | Verb, gerund or present participle | Smoking kills people |
| VBN | Verb, past participle | She has done her homework |
| VBP | Verb, non-3rd person singular present | You flit from place to place |
| VBZ | Verb, 3rd person singular present | He never calls me |
| WDT | Wh-determiner | The store honored the complaints, which were less than 25 days old |
| WP | Wh-pronoun | Who can help me? |
| WP$ | Possessive wh-pronoun | Whose fault is it? |
| WRB | Wh-adverb | Where are you going? |
nlp.load('pos').predict('Part of speech assigns each token in a sentence a grammatical label')
| token | pos |
|---|---|
| Part | NN |
| of | IN |
| speech | NN |
| assigns | NNS |
| each | DT |
| token | NN |
| in | IN |
| a | DT |
| sentence | NN |
| a | DT |
| grammatical | JJ |
| label | NN |
Emotion Classifier
Emotion Classifier example
Classifies text as one of 4 categories (joy, fear, surprise, sadness)
nlp.load('emotion').predict('I love NLU!')
| sentence_embeddings | emotion_confidence | sentence | emotion |
|---|---|---|---|
| [0.027570432052016258, -0.052647676318883896, …] | 0.976017 | I love NLU! | joy |
Sentiment Classifier
Classifies binary sentiment for every sentence, either positive or negative.
nlp.load('sentiment').predict("I hate this guy Sami")
| sentiment_confidence | sentence | sentiment | checked |
|---|---|---|---|
| 0.5778 | I hate this guy Sami | negative | [I, hate, this, guy, Sami] |
Question Classifier 50 class
50 Class Questions Classifier example
Classifies between 50 different types of questions trained on the Trec50 dataset When setting predict(meta=True) nlu will output the probabilities for all other 49 question classes. The classes are the following :
Abbreviation question classes:
| Class | Definition |
|---|---|
| abb | abbreviation |
| exp | expression abbreviated |
Entities question classes:
| Class | Definition |
|---|---|
| animal | animals |
| body | organs of body |
| color | colors |
| creative | inventions, books and other creative pieces |
| currency | currency names |
| dis | .med. diseases and medicine |
| event | events |
| food | food |
| instrument | musical instrument |
| lang | languages |
| letter | letters like a-z |
| other | other entities |
| plant | plants |
| product | products |
| religion | religions |
| sport | sports |
| substance | elements and substances |
| symbol | symbols and signs |
| technique | techniques and methods |
| term | equivalent terms |
| vehicle | vehicles |
| word | words with a special property |
Description and abstract concepts question classes:
| Class | Definition |
|---|---|
| definition | definition of sth. |
| description | description of sth. |
| manner | manner of an action |
| reason | reasons |
Human being question classes:
| Class | Definition |
|---|---|
| group | a group or organization of persons |
| ind | an individual |
| title | title of a person |
| description | description of a person |
Location question classes:
| Class | Definition |
|---|---|
| city | cities |
| country | countries |
| mountain | mountains |
| other | other locations |
| state | states |
Numeric question classes:
| Class | Definition |
|---|---|
| code | postcodes or other codes |
| count | number of sth. |
| date | dates |
| distance | linear measures |
| money | prices |
| order | ranks |
| other | other numbers |
| period | the lasting time of sth. |
| percent | fractions |
| speed | speed |
| temp | temperature |
| size | size, area and volume |
| weight | weight |
nlp.load('en.classify.trec50').predict('How expensive is the Watch?')
| sentence_embeddings | question_confidence | sentence | question |
|---|---|---|---|
| [0.051809534430503845, 0.03128402680158615, -0…] | 0.919436 | How expensive is the watch? | NUM_count |
Fake News Classifier
nlp.load('en.classify.fakenews').predict('Unicorns have been sighted on Mars!')
| sentence_embeddings | fake_confidence | sentence | fake |
|---|---|---|---|
| [-0.01756167598068714, 0.015006818808615208, -…] | 1.000000 | Unicorns have been sighted on Mars! | FAKE |
Cyberbullying Classifier
Cyberbullying Classifier example
Classifies sexism and racism
nlp.load('en.classify.cyberbullying').predict('Women belong in the kitchen.') # sorry we really don't mean it
| sentence_embeddings | cyberbullying_confidence | sentence | cyberbullying |
|---|---|---|---|
| [-0.054944973438978195, -0.022223370149731636,…] | 0.999998 | Women belong in the kitchen. | sexism |
Spam Classifier
nlp.load('en.classify.spam').predict('Please sign up for this FREE membership it costs $$NO MONEY$$ just your mobile number!')
| sentence_embeddings | spam_confidence | sentence | spam |
|---|---|---|---|
| [0.008322705514729023, 0.009957313537597656, 0…] | 1.000000 | Please sign up for this FREE membership it cos… | spam |
Sarcasm Classifier
nlp.load('en.classify.sarcasm').predict('gotta love the teachers who give exams on the day after halloween')
| sentence_embeddings | sarcasm_confidence | sentence | sarcasm |
|---|---|---|---|
| [-0.03146284446120262, 0.04071342945098877, 0….] | 0.999985 | gotta love the teachers who give exams on the… | sarcasm |
IMDB Movie Sentiment Classifier
Movie Review Sentiment Classifier example
nlp.load('en.sentiment.imdb').predict('The Matrix was a pretty good movie')
| document | sentence_embeddings | sentiment_negative | sentiment_negative | sentiment_positive | sentiment |
|---|---|---|---|---|---|
| The Matrix was a pretty good movie | [[0.04629608988761902, -0.020867452025413513, … ] | [2.7235753918830596e-07] | [2.7235753918830596e-07] | [0.9999997615814209] | [positive] |
Twitter Sentiment Classifier
Twitter Sentiment Classifier Example
nlp.load('en.sentiment.twitter').predict('@elonmusk Tesla stock price is too high imo')
| document | sentence_embeddings | sentiment_negative | sentiment_negative | sentiment_positive | sentiment |
|---|---|---|---|---|---|
| @elonmusk Tesla stock price is too high imo | [[0.08604438602924347, 0.04703635722398758, -0…] | [1.0] | [1.0] | [1.692714735043349e-36] | [negative] |
Language Classifier
Languages Classifier example
Classifies the following 20 languages :
Bulgarian, Czech, German, Greek, English, Spanish, Finnish, French, Croatian, Hungarian, Italy, Norwegian, Polish, Portuguese, Romanian, Russian, Slovak, Swedish, Turkish, and Ukrainian
nlp.load('lang').predict(['NLU is an open-source text processing library for advanced natural language processing for the Python.','NLU est une bibliothèque de traitement de texte open source pour le traitement avancé du langage naturel pour les langages de programmation Python.'])
| language_confidence | document | language |
|---|---|---|
| 0.985407 | NLU is an open-source text processing library …] | en |
| 0.999822 | NLU est une bibliothèque de traitement de text…] | fr |
E2E Classifier
This is a multi class classifier trained on the E2E dataset for Natural language generation
nlp.load('e2e').predict('E2E is a dataset for training generative models')
| sentence_embeddings | e2e | e2e_confidence | sentence |
|---|---|---|---|
| [0.021445205435156822, -0.039284929633140564, …,] | customer rating[high] | 0.703248 | E2E is a dataset for training generative models |
| None | name[The Waterman] | 0.703248 | None |
| None | eatType[restaurant] | 0.703248 | None |
| None | priceRange[£20-25] | 0.703248 | None |
| None | familyFriendly[no] | 0.703248 | None |
| None | familyFriendly[yes] | 0.703248 | None |
Toxic Classifier
nlp.load('en.classify.toxic').predict('You are to stupid')
| toxic_confidence | toxic | sentence_embeddings | document |
|---|---|---|---|
| 0.978273 | [toxic,insult] | [[-0.03398505970835686, 0.0007853527786210179,…,] | You are to stupid |
YAKE Unsupervised Keyword Extractor
YAKE Keyword Extraction Example
nlp.load('yake').predict("NLU is a Python Library for beginners and experts in NLP")
| keywords_score_confidence | keywords | sentence |
|---|---|---|
| 0.454232 | [nlu, nlp, python library] | NLU is a Python Library for beginners and expe… |
Word Embeddings Bert
nlp.load('bert').predict('NLU offers the latest embeddings in one line ')
| token | bert_embeddings |
|---|---|
| NLU | [0.3253086805343628, -0.574441134929657, -0.08…] |
| offers | [-0.6660361886024475, -0.1494743824005127, -0…] |
| the | [-0.6587662696838379, 0.3323703110218048, 0.16…] |
| latest | [0.7552685737609863, 0.17207926511764526, 1.35…] |
| embeddings | [-0.09838500618934631, -1.1448147296905518, -1…] |
| in | [-0.4635896384716034, 0.38369956612586975, 0.0…] |
| one | [0.26821616291999817, 0.7025910019874573, 0.15…] |
| line | [-0.31930840015411377, -0.48271292448043823, 0…] |
Word Embeddings Biobert
BIOBERT Word Embeddings example
Bert model pretrained on Bio dataset
nlp.load('biobert').predict('Biobert was pretrained on a medical dataset')
| token | biobert_embeddings |
|---|---|
| NLU | [0.3253086805343628, -0.574441134929657, -0.08…] |
| offers | [-0.6660361886024475, -0.1494743824005127, -0…] |
| the | [-0.6587662696838379, 0.3323703110218048, 0.16…] |
| latest | [0.7552685737609863, 0.17207926511764526, 1.35…] |
| embeddings | [-0.09838500618934631, -1.1448147296905518, -1…] |
| in | [-0.4635896384716034, 0.38369956612586975, 0.0…] |
| one | [0.26821616291999817, 0.7025910019874573, 0.15…] |
| line | [-0.31930840015411377, -0.48271292448043823, 0…] |
Word Embeddings Covidbert
COVIDBERT Word Embeddings
Bert model pretrained on COVID dataset
nlp.load('covidbert').predict('Albert uses a collection of many berts to generate embeddings')
| token | covid_embeddings |
|---|---|
| He | [-1.0551927089691162, -1.534174919128418, 1.29…,] |
| was | [-0.14796507358551025, -1.3928604125976562, 0….,] |
| suprised | [1.0647121667861938, -0.3664901852607727, 0.54…,] |
| by | [-0.15271103382110596, -0.6812090277671814, -0…,] |
| the | [-0.45744237303733826, -1.4266574382781982, -0…,] |
| diversity | [-0.05339818447828293, -0.5118572115898132, 0….,] |
| of | [-0.2971905767917633, -1.0936176776885986, -0….,] |
| NLU | [-0.9573594331741333, -0.18001675605773926, -1…,] |
Word Embeddings Albert
nlp.load('albert').predict('Albert uses a collection of many berts to generate embeddings')
| token | albert_embeddings |
|---|---|
| Albert | [-0.08257609605789185, -0.8017427325248718, 1…] |
| uses | [0.8256351947784424, -1.5144840478897095, 0.90…] |
| a | [-0.22089454531669617, -0.24295514822006226, 3…] |
| collection | [-0.2136894017457962, -0.8225528597831726, -0…] |
| of | [1.7623294591903687, -1.113651156425476, 0.800…] |
| many | [0.6415284872055054, -0.04533941298723221, 1.9…] |
| berts | [-0.5591965317726135, -1.1773797273635864, -0…] |
| to | [1.0956681966781616, -1.4180747270584106, -0.2…] |
| generate | [-0.6759272813796997, -1.3546931743621826, 1.6…] |
| embeddings | [-0.0035803020000457764, -0.35928264260292053,…] |
Electra Embeddings
ELECTRA Word Embeddings example
nlp.load('electra').predict('He was suprised by the diversity of NLU')
| token | electra_embeddings |
|---|---|
| He | [0.29674115777015686, -0.21371933817863464, -0…,] |
| was | [-0.4278327524662018, -0.5352768898010254, -0….,] |
| suprised | [-0.3090559244155884, 0.8737565279006958, -1.0…,] |
| by | [-0.07821277529001236, 0.13081523776054382, 0….,] |
| the | [0.5462881922721863, 0.0683358758687973, -0.41…,] |
| diversity | [0.1381239891052246, 0.2956242859363556, 0.250…,] |
| of | [-0.5667567253112793, -0.3955455720424652, -0….,] |
| NLU | [0.5597224831581116, -0.703249454498291, -1.08…,] |
Word Embeddings Elmo
nlp.load('elmo').predict('Elmo was trained on Left to right masked to learn its embeddings')
| token | elmo_embeddings |
|---|---|
| Elmo | [0.6083735227584839, 0.20089012384414673, 0.42…] |
| was | [0.2980785369873047, -0.07382500916719437, -0…] |
| trained | [-0.39923471212387085, 0.17155063152313232, 0…] |
| on | [0.04337821900844574, 0.1392083466053009, -0.4…] |
| Left | [0.4468783736228943, -0.623046875, 0.771505534…] |
| to | [-0.18209676444530487, 0.03812692314386368, 0…] |
| right | [0.23305709660053253, -0.6459438800811768, 0.5…] |
| masked | [-0.7243442535400391, 0.10247116535902023, 0.1…] |
| to | [-0.18209676444530487, 0.03812692314386368, 0…] |
| learn | [1.2942464351654053, 0.7376189231872559, -0.58…] |
| its | [0.055951207876205444, 0.19218483567237854, -0…] |
| embeddings | [-1.31377112865448, 0.7727609872817993, 0.6748…] |
Word Embeddings Xlnet
nlp.load('xlnet').predict('XLNET computes contextualized word representations using combination of Autoregressive Language Model and Permutation Language Model')
| token | xlnet_embeddings |
|---|---|
| XLNET | [-0.02719488926231861, -1.7693557739257812, -0…] |
| computes | [-1.8262947797775269, 0.8455266356468201, 0.57…] |
| contextualized | [2.8446314334869385, -0.3564329445362091, -2.1…] |
| word | [-0.6143839359283447, -1.7368144989013672, -0…] |
| representations | [-0.30445945262908936, -1.2129613161087036, 0…] |
| using | [0.07423821836709976, -0.02561005763709545, -0…] |
| combination | [-0.5387097597122192, -1.1827564239501953, 0.5…] |
| of | [-1.403516411781311, 0.3108177185058594, -0.32…] |
| Autoregressive | [-1.0869172811508179, 0.7135171890258789, -0.2…] |
| Language | [-0.33215752243995667, -1.4108021259307861, -0…] |
| Model | [-1.6097160577774048, -0.2548254430294037, 0.0…] |
| and | [0.7884324789047241, -1.507911205291748, 0.677…] |
| Permutation | [0.6049966812133789, -0.157279372215271, -0.06…] |
| Language | [-0.33215752243995667, -1.4108021259307861, -0…] |
| Model | [-1.6097160577774048, -0.2548254430294037, 0.0…] |
Word Embeddings Glove
nlp.load('glove').predict('Glove embeddings are generated by aggregating global word-word co-occurrence matrix from a corpus')
| token | glove_embeddings |
|---|---|
| Glove | [0.3677999973297119, 0.37073999643325806, 0.32…] |
| embeddings | [0.732479989528656, 0.3734700083732605, 0.0188…] |
| are | [-0.5153300166130066, 0.8318600058555603, 0.22…] |
| generated | [-0.35510000586509705, 0.6115900278091431, 0.4…] |
| by | [-0.20874999463558197, -0.11739999800920486, 0…] |
| aggregating | [-0.5133699774742126, 0.04489300027489662, 0.1…] |
| global | [0.24281999468803406, 0.6170300245285034, 0.66…] |
| word-word | [0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, …] |
| co-occurrence | [0.16384999454021454, -0.3178800046443939, 0.1…] |
| matrix | [-0.2663800120353699, 0.4449099898338318, 0.32…] |
| from | [0.30730998516082764, 0.24737000465393066, 0.6…] |
| a | [-0.2708599865436554, 0.04400600120425224, -0…] |
| corpus | [0.39937999844551086, 0.15894000232219696, -0…] |
Multiple Token Embeddings at once
Compare 6 Embeddings at once with NLU and T-SNE example
#This takes around 10GB RAM, watch out!
nlp.load('bert albert electra elmo xlnet use glove').predict('Get all of them at once! Watch your RAM tough!')
| xlnet_embeddings | use_embeddings | elmo_embeddings | electra_embeddings | glove_embeddings | sentence | albert_embeddings | biobert_embeddings | bert_embeddings |
|---|---|---|---|---|---|---|---|---|
| [[-0.003953204490244389, -1.5821468830108643, …,] | [-0.019299551844596863, -0.04762779921293259, …,] | [[0.04002974182367325, -0.43536433577537537, -…,] | [[0.19559216499328613, -0.46693214774131775, -…,] | [[0.1443299949169159, 0.4395099878311157, 0.58…,] | Get all of them at once, watch your RAM tough! | [[-0.4743960201740265, -0.581386387348175, 0.7…,] | [[-0.00012563914060592651, -1.372296929359436,…,] | [[-0.7687976360321045, 0.8489367961883545, -0….,] |
Bert Sentence Embeddings
BERT Sentence Embeddings example
| sentence | bert_sentence_embeddings |
|---|---|
| He was suprised by the diversity of NLU | [-1.0726687908172607, 0.4481312036514282, -0.0…,] |
Electra Sentence Embeddings
ELECTRA Sentence Embeddings example
nlp.load('embed_sentence.electra').predict('He was suprised by the diversity of NLU')
| sentence | electra_sentence_embeddings |
|---|---|
| He was suprised by the diversity of NLU | [0.005376118700951338, 0.18036000430583954, -0…,] |
Sentence Embeddings Use
USE Sentence Embeddings example
nlp.load('use').predict('USE is designed to encode whole sentences and documents into vectors that can be used for text classification, semantic similarity, clustering or oder NLP tasks')
| sentence | use_embeddings |
|---|---|
| USE is designed to encode whole sentences and …] | [0.03302069380879402, -0.004255455918610096, -…] |
Spell Checking
nlp.load('spell').predict('I liek pentut buttr ant jely')
| token | checked |
|---|---|
| I | I |
| liek | like |
| peantut | pentut |
| buttr | buttr |
| and | and |
| jelli | jely |
Dependency Parsing Unlabeled
Untyped Dependency Parsing example
nlp.load('dep.untyped').predict('Untyped Dependencies represent a grammatical tree structure.md')
| token | pos | dependency |
|---|---|---|
| Untyped | NNP | ROOT |
| Dependencies | NNP | represent |
| represent | VBD | Untyped |
| a | DT | structure |
| grammatical | JJ | structure |
| tree | NN | structure |
| structure | NN | represent |
Dependency Parsing Labeled
Typed Dependency Parsing example
nlp.load('dep').predict('Typed Dependencies represent a grammatical tree structure.md where every edge has a label')
| token | pos | dependency | labled_dependency |
|---|---|---|---|
| Typed | NNP | ROOT | root |
| Dependencies | NNP | represent | nsubj |
| represent | VBD | Typed | parataxis |
| a | DT | structure | nsubj |
| grammatical | JJ | structure | amod |
| tree | NN | structure | flat |
| structure | NN | represent | nsubj |
| where | WRB | structure | mark |
| every | DT | edge | nsubj |
| edge | NN | where | nsubj |
| has | VBZ | ROOT | root |
| a | DT | label | nsubj |
| label | NN | has | nsubj |
Tokenization
nlp.load('tokenize').predict('Each word and symbol in a sentence will generate token.')
| token |
|---|
| Each |
| word |
| and |
| symbol |
| will |
| generate |
| a |
| token |
| . |
Stemmer
nlp.load('stem').predict('NLU can get you the stem of a word')
| token | stem |
|---|---|
| NLU | nlu |
| can | can |
| get | get |
| you | you |
| the | the |
| stem | stem |
| of | of |
| a | a |
| word | word |
Stopwords Removal
nlp.load('stopwords').predict('I want you to remove stopwords from this sentence please')
| token | cleanTokens |
|---|---|
| I | remove |
| want | stopwords |
| you | sentence |
| to | None |
| remove | None |
| stopwords | None |
| from | None |
| this | None |
| sentence | None |
| please | None |
Lemmatization
nlp.load('lemma').predict('Lemmatizing generates a less noisy version of the inputted tokens')
| token | lemma |
|---|---|
| Lemmatizing | Lemmatizing |
| generates | generate |
| a | a |
| less | less |
| noisy | noisy |
| version | version |
| of | of |
| the | the |
| inputted | input |
| tokens | token |
Normalizers
nlp.load('norm').predict('@CKL_IT says that #normalizers are pretty useful to clean #structured_strings in #NLU like tweets')
| normalized | token |
|---|---|
| CKLIT | @CKL_IT |
| says | says |
| that | that |
| normalizers | #normalizers |
| are | are |
| pretty | pretty |
| useful | useful |
| to | to |
| clean | clean |
| structuredstrings | #structured_strings |
| in | in |
| NLU | #NLU |
| like | like |
| tweets | tweets |
NGrams
nlp.load('ngram').predict('Wht a wondful day!')
| document | ngrams | pos |
|---|---|---|
| To be or not to be | [To, be, or, not, to, be, To be, be or, or not…] | [TO, VB, CC, RB, TO, VB] |
Date Matching
nlp.load('match.datetime').predict('In the years 2000/01/01 to 2010/01/01 a lot of things happened')
| document | date |
|---|---|
| In the years 2000/01/01 to 2010/01/01 a lot of things happened | [2000/01/01, 2001/01/01] |
Entity Chunking
Checkout see here for all possible POS labels or
Splits text into rows based on matched grammatical entities.
# First we load the pipeline
pipe = nlp.load('match.chunks')
# Now we print the info to see at which index which com,ponent is and what parameters we can configure on them
pipe.generate_class_metadata_table()
# Lets set our Chunker to only match NN
pipe['default_chunker'].setRegexParsers(['<NN>+', '<JJ>+'])
# Now we can predict with the configured pipeline
pipe.predict("Jim and Joe went to the big blue market next to the town hall")
# the outputs of component_list.print_info()
The following parameters are configurable for this NLU pipeline (You can copy paste the examples) :
>>> component_list['document_assembler'] has settable params:
component_list['document_assembler'].setCleanupMode('disabled') | Info: possible values: disabled, inplace, inplace_full, shrink, shrink_full, each, each_full, delete_full | Currently set to : disabled
>>> component_list['sentence_detector'] has settable params:
component_list['sentence_detector'].setCustomBounds([]) | Info: characters used to explicitly mark sentence bounds | Currently set to : []
component_list['sentence_detector'].setDetectLists(True) | Info: whether detect lists during sentence detection | Currently set to : True
component_list['sentence_detector'].setExplodeSentences(False) | Info: whether to explode each sentence into a different row, for better parallelization. Defaults to false. | Currently set to : False
component_list['sentence_detector'].setMaxLength(99999) | Info: Set the maximum allowed length for each sentence | Currently set to : 99999
component_list['sentence_detector'].setMinLength(0) | Info: Set the minimum allowed length for each sentence. | Currently set to : 0
component_list['sentence_detector'].setUseAbbreviations(True) | Info: whether to apply abbreviations at sentence detection | Currently set to : True
component_list['sentence_detector'].setUseCustomBoundsOnly(False) | Info: Only utilize custom bounds in sentence detection | Currently set to : False
>>> component_list['regex_matcher'] has settable params:
component_list['regex_matcher'].setCaseSensitiveExceptions(True) | Info: Whether to care for case sensitiveness in exceptions | Currently set to : True
component_list['regex_matcher'].setTargetPattern('\S+') | Info: pattern to grab from text as token candidates. Defaults \S+ | Currently set to : \S+
component_list['regex_matcher'].setMaxLength(99999) | Info: Set the maximum allowed length for each token | Currently set to : 99999
component_list['regex_matcher'].setMinLength(0) | Info: Set the minimum allowed length for each token | Currently set to : 0
>>> component_list['sentiment_dl'] has settable params:
>>> component_list['default_chunker'] has settable params:
component_list['default_chunker'].setRegexParsers(['<DT>?<JJ>*<NN>+']) | Info: an array of grammar based chunk parsers | Currently set to : ['<DT>?<JJ>*<NN>+']```
| chunk | pos |
|---|---|
| market | [NNP, CC, NNP, VBD, TO, DT, JJ, JJ, NN, JJ, TO… |
| town hall | [NNP, CC, NNP, VBD, TO, DT, JJ, JJ, NN, JJ, TO… |
| big blue | [NNP, CC, NNP, VBD, TO, DT, JJ, JJ, NN, JJ, TO… |
| next | [NNP, CC, NNP, VBD, TO, DT, JJ, JJ, NN, JJ, TO… |
Sentence Detection
nlp.load('sentence_detector').predict('NLU can detect things. Like beginning and endings of sentences. It can also do much more!', output_level ='sentence')
| sentence | word_embeddings | pos | ner |
|---|---|---|---|
| NLU can detect things. | [[0.4970400035381317, -0.013454999774694443, 0…] | [NNP, MD, VB, NNS, ., IN, VBG, CC, NNS, IN, NN… ] | [O, O, O, O, O, B-sent, O, O, O, O, O, O, B-se…] |
| Like beginning and endings of sentences. | [[0.4970400035381317, -0.013454999774694443, 0…] | [NNP, MD, VB, NNS, ., IN, VBG, CC, NNS, IN, NN…] | [O, O, O, O, O, B-sent, O, O, O, O, O, O, B-se…] |
| It can also do much more! | [[0.4970400035381317, -0.013454999774694443, 0…] | [NNP, MD, VB, NNS, ., IN, VBG, CC, NNS, IN, NN…] | [O, O, O, O, O, B-sent, O, O, O, O, O, O, B-se…] |
Document Normalization
Document Normalizer example
The DocumentNormalizer extracts content from HTML or XML documents, applying either data cleansing using an arbitrary number of custom regular expressions either data extraction following the different parameters
pipe = nlp.load('norm_document')
data = '<!DOCTYPE html> <html> <head> <title>Example</title> </head> <body> <p>This is an example of a simple HTML page with one paragraph.</p> </body> </html>'
df = pipe.predict(data,output_level='document')
df
| text | normalized_text |
|---|---|
<!DOCTYPE html> <html> <head> <title>Example</title> </head> <body> <p>This is an example of a simple HTML page with one paragraph.</p> </body> </html> |
Example This is an example of a simple HTML page with one paragraph. |
Word Segmenter
Word Segmenter Example
The WordSegmenter segments languages without any rule-based tokenization such as Chinese, Japanese, or Korean
pipe = nlp.load('ja.segment_words')
# japanese for 'Donald Trump and Angela Merkel dont share many opinions'
ja_data = ['ドナルド・トランプとアンゲラ・メルケルは多くの意見を共有していません']
df = pipe.predict(ja_data, output_level='token')
df
| token |
|---|
| ドナルド |
| ・ |
| トランプ |
| と |
| アンゲラ |
| ・ |
| メルケル |
| は |
| 多く |
| の |
| 意見 |
| を |
| 共有 |
| し |
| て |
| い |
| ませ |
| ん |
Translation
Translation example
You can translate between more than 192 Languages pairs with the Marian Models
You need to specify the language your data is in as start_language and the language you want to translate to as target_language.
The language references must be ISO language codes
nlp.load('xx.<start_language>.translate_to.<target_language>')
Translate Turkish to English:
nlp.load('xx.tr.translate_to.fr')
Translate English to French:
nlp.load('xx.en.translate_to.fr')
Translate French to Hebrew:
nlp.load('xx.en.translate_to.fr')
translate_pipe = nlp.load('xx.en.translate_to.de')
df = translate_pipe.predict('Billy likes to go to the mall every sunday')
df
| sentence | translation |
|---|---|
| Billy likes to go to the mall every sunday | Billy geht gerne jeden Sonntag ins Einkaufszentrum |
Automatic Speech Recognition (ASR) with HuBERT
ASR Demo Notebook
Recognize speech in Audio files with HuBERT
# Let's download an audio file
!wget https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/audio/samples/wavs/ngm_12484_01067234848.wav
FILE_PATH = "ngm_12484_01067234848.wav"
asr_df = nlp.load('en.speech2text.hubert').predict('ngm_12484_01067234848.wav')
asr_df
| text |
|---|
| PEOPLE WHO DIED WHILE LIVING IN OTHER PLACES |
Automatic Speech Recognition (ASR) with Wav2Vec2
ASR Tutorial Notebook
Recognize speech in Audio files with HuBERT
# Let's download an audio file
!wget https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/audio/samples/wavs/ngm_12484_01067234848.wav
FILE_PATH = "ngm_12484_01067234848.wav"
asr_df = nlp.load('en.speech2text.wav2vec2.v2_base_960h').predict('ngm_12484_01067234848.wav')
asr_df
| text |
|---|
| PEOPLE WHO DIED WHILE LIVING IN OTHER PLACES |
Table Question Answering (TAPAS)
Table Question Answering on Pandas DataFrames powered by TAPAS: Weakly Supervised Table Parsing via Pre-training
First we need a pandas dataframe on for which we want to ask questions. The so called “context”
import pandas as pd
context_df = pd.DataFrame({
'name':['Donald Trump','Elon Musk'],
'money': ['$100,000,000','$20,000,000,000,000'],
'married': ['yes','no'],
'age' : ['75','55'] })
context_df
Then we create an array of questions
questions = [
"Who earns less than 200,000,000?",
"Who earns more than 200,000,000?",
"Who earns 100,000,000?",
"How much money has Donald Trump?",
"Who is the youngest?",
]
questions
Now Combine the data, pass it to NLU and get answers for your questions
import nlu
# Now we combine both to a tuple and we are done! We can now pass this to the .predict() method
tapas_data = (context_df, questions)
# Lets load a TAPAS QA model and predict on (context,question).
# It will give us an aswer for every question in the questions array, based on the context in context_df
answers = nlu.load('en.answer_question.tapas.wtq.large_finetuned').predict(tapas_data)
answers
| sentence | tapas_qa_UNIQUE_aggregation | tapas_qa_UNIQUE_answer | tapas_qa_UNIQUE_cell_positions | tapas_qa_UNIQUE_cell_scores | tapas_qa_UNIQUE_origin_question |
|---|---|---|---|---|---|
| Who earns less than 200,000,000? | NONE | Donald Trump | [0, 0] | 1 | Who earns less than 200,000,000? |
| Who earns more than 200,000,000? | NONE | Elon Musk | [0, 1] | 1 | Who earns more than 200,000,000? |
| Who earns 100,000,000? | NONE | Donald Trump | [0, 0] | 1 | Who earns 100,000,000? |
| How much money has Donald Trump? | SUM | SUM($100,000,000) | [1, 0] | 1 | How much money has Donald Trump? |
| Who is the youngest? | NONE | Elon Musk | [0, 1] | 1 | Who is the youngest? |
Image Classification (VIT)
Image Classification Tutorial Notebook
Image Classifier Based on VIT
Lets download a folder of images and predict on it
!wget -q https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/images/images.zip
import shutil
shutil.unpack_archive("images.zip", "images", "zip")
! ls /content/images/images/
Once we have image data its easy to label it, we just pass the folder with images to nlu.predict() and NLU will return a pandas DF with one row per image detected
nlu.load('en.classify_image.base_patch16_224').predict('/content/images/images')
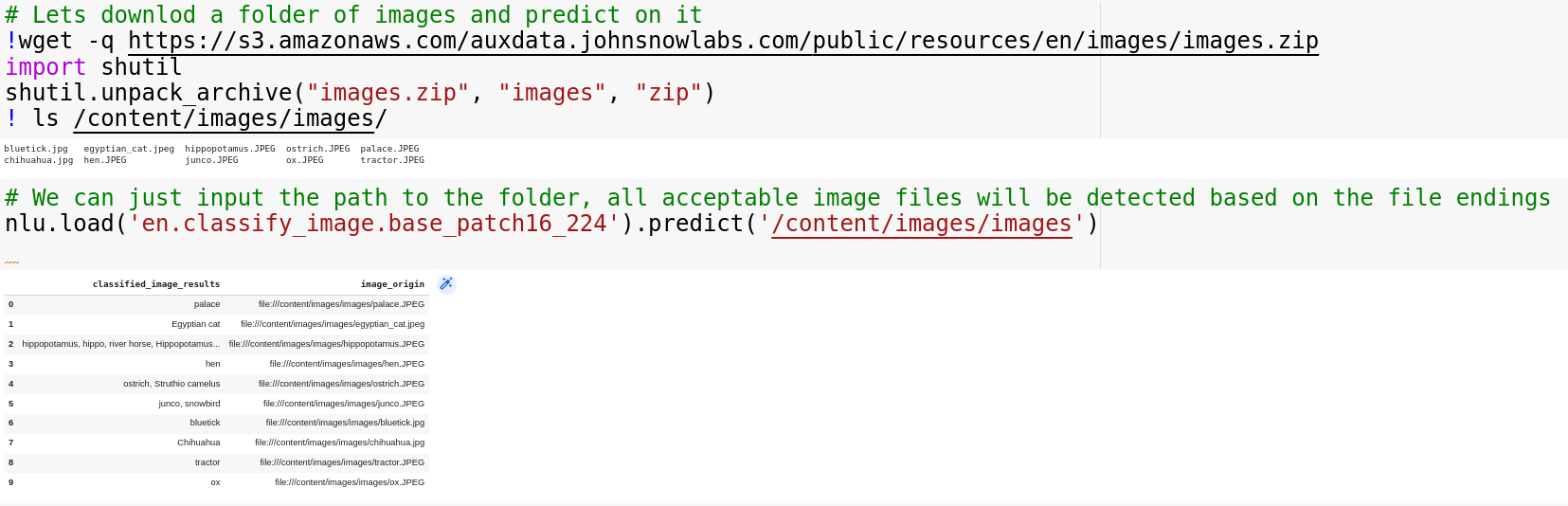
Image Classification (ConvNext)
Image Classification Tutorial Notebook
Image Classifier Based on ConvNext
Lets download a folder of images and predict on it
!wget -q https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/images/images.zip
import shutil
shutil.unpack_archive("images.zip", "images", "zip")
! ls /content/images/images/
Once we have image data its easy to label it, we just pass the folder with images to nlu.predict() and NLU will return a pandas DF with one row per image detected
nlu.load('en.classify_image.convnext.tiny').predict('/content/images/images')
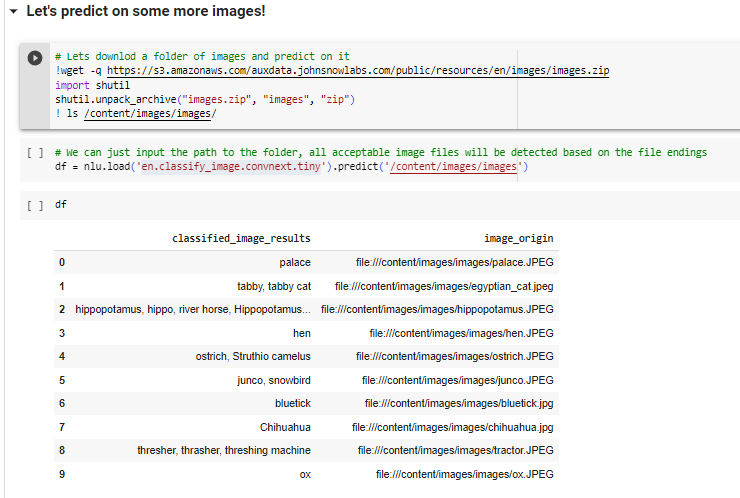
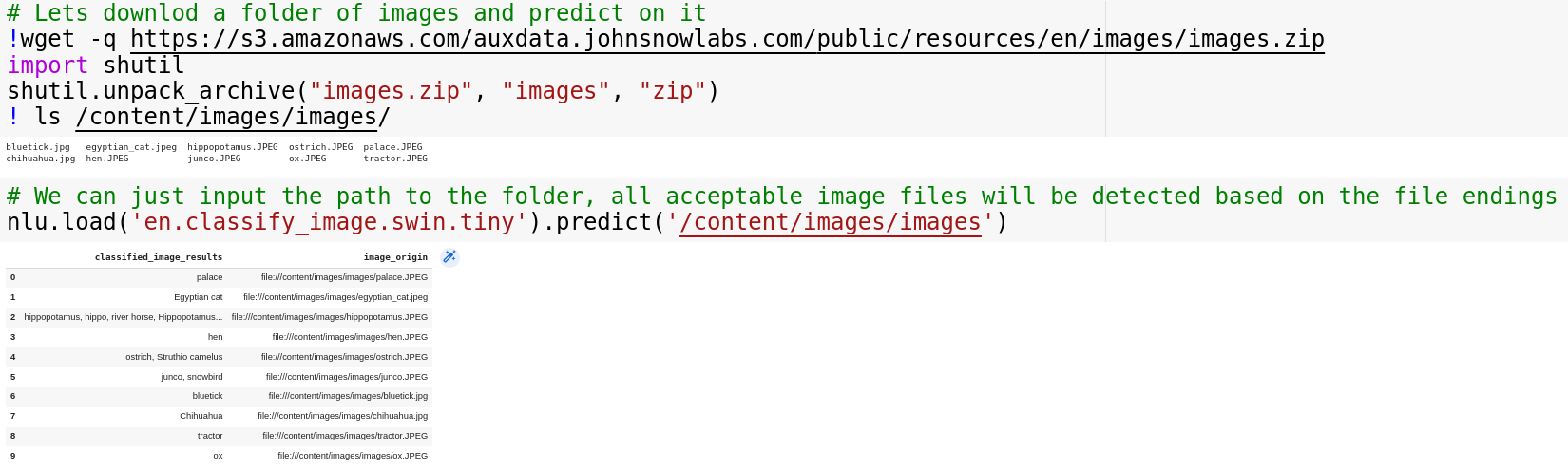
Image Classification (SWIN)
Image Classification Tutorial Notebook
Image Classifier Based on SWIN
Lets download a folder of images and predict on it
!wget -q https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/images/images.zip
import shutil
shutil.unpack_archive("images.zip", "images", "zip")
! ls /content/images/images/
Once we have image data its easy to label it, we just pass the folder with images to nlu.predict() and NLU will return a pandas DF with one row per image detected
nlu.load('en.classify_image.swin.tiny').predict('/content/images/images')
T5
Overview of every task available with T5
The T5 model is trained on various datasets for 17 different tasks which fall into 8 categories.
- Text summarization
- Question answering
- Translation
- Sentiment analysis
- Natural Language inference
- Coreference resolution
- Sentence Completion
- Word sense disambiguation
Every T5 Task with explanation:
| Task Name | Explanation |
|---|---|
| 1.CoLA | Classify if a sentence is gramaticaly correct |
| 2.RTE | Classify whether if a statement can be deducted from a sentence |
| 3.MNLI | Classify for a hypothesis and premise whether they contradict or contradict each other or neither of both (3 class). |
| 4.MRPC | Classify whether a pair of sentences is a re-phrasing of each other (semantically equivalent) |
| 5.QNLI | Classify whether the answer to a question can be deducted from an answer candidate. |
| 6.QQP | Classify whether a pair of questions is a re-phrasing of each other (semantically equivalent) |
| 7.SST2 | Classify the sentiment of a sentence as positive or negative |
| 8.STSB | Classify the sentiment of a sentence on a scale from 1 to 5 (21 Sentiment classes) |
| 9.CB | Classify for a premise and a hypothesis whether they contradict each other or not (binary). |
| 10.COPA | Classify for a question, premise, and 2 choices which choice the correct choice is (binary). |
| 11.MultiRc | Classify for a question, a paragraph of text, and an answer candidate, if the answer is correct (binary), |
| 12.WiC | Classify for a pair of sentences and a disambigous word if the word has the same meaning in both sentences. |
| 13.WSC/DPR | Predict for an ambiguous pronoun in a sentence what it is referring to. |
| 14.Summarization | Summarize text into a shorter representation. |
| 15.SQuAD | Answer a question for a given context. |
| 16.WMT1. | Translate English to German |
| 17.WMT2. | Translate English to French |
| 18.WMT3. | Translate English to Romanian |
- Every T5 Task example notebook to see how to use every T5 Task.
- T5 Open and Closed Book question answering notebook
Text Summarization
Summarizes a paragraph into a shorter version with the same semantic meaning, based on Text summarization
# Set the task on T5
pipe = nlp.load('summarize')
# define Data, add additional tags between sentences
data = [
'''
The belgian duo took to the dance floor on monday night with some friends . manchester united face newcastle in the premier league on wednesday . red devils will be looking for just their second league away win in seven . louis van gaal’s side currently sit two points clear of liverpool in fourth .
''',
''' Calculus, originally called infinitesimal calculus or "the calculus of infinitesimals", is the mathematical study of continuous change, in the same way that geometry is the study of shape and algebra is the study of generalizations of arithmetic operations. It has two major branches, differential calculus and integral calculus; the former concerns instantaneous rates of change, and the slopes of curves, while integral calculus concerns accumulation of quantities, and areas under or between curves. These two branches are related to each other by the fundamental theorem of calculus, and they make use of the fundamental notions of convergence of infinite sequences and infinite series to a well-defined limit.[1] Infinitesimal calculus was developed independently in the late 17th century by Isaac Newton and Gottfried Wilhelm Leibniz.[2][3] Today, calculus has widespread uses in science, engineering, and economics.[4] In mathematics education, calculus denotes courses of elementary mathematical analysis, which are mainly devoted to the study of functions and limits. The word calculus (plural calculi) is a Latin word, meaning originally "small pebble" (this meaning is kept in medicine – see Calculus (medicine)). Because such pebbles were used for calculation, the meaning of the word has evolved and today usually means a method of computation. It is therefore used for naming specific methods of calculation and related theories, such as propositional calculus, Ricci calculus, calculus of variations, lambda calculus, and process calculus.'''
]
#Predict on text data with T5
pipe.predict(data)
| Predicted summary | Text |
|---|---|
| manchester united face newcastle in the premier league on wednesday . louis van gaal’s side currently sit two points clear of liverpool in fourth . the belgian duo took to the dance floor on monday night with some friends . | the belgian duo took to the dance floor on monday night with some friends . manchester united face newcastle in the premier league on wednesday . red devils will be looking for just their second league away win in seven . louis van gaal’s side currently sit two points clear of liverpool in fourth . |
Binary Sentence similarity/ Paraphrasing
Binary sentence similarity example
Classify whether one sentence is a re-phrasing or similar to another sentence
This is a sub-task of GLUE and based on MRPC - Binary Paraphrasing/ sentence similarity classification
t5 = nlp.load('en.t5.base')
# Set the task on T5
t5['t5'].setTask('mrpc ')
# define Data, add additional tags between sentences
data = [
''' sentence1: We acted because we saw the existing evidence in a new light , through the prism of our experience on 11 September , " Rumsfeld said .
sentence2: Rather , the US acted because the administration saw " existing evidence in a new light , through the prism of our experience on September 11 "
'''
,
'''
sentence1: I like to eat peanutbutter for breakfast
sentence2: I like to play football.
'''
]
#Predict on text data with T5
t5.predict(data)
| Sentence1 | Sentence2 | prediction |
|---|---|---|
| We acted because we saw the existing evidence in a new light , through the prism of our experience on 11 September , “ Rumsfeld said . | Rather , the US acted because the administration saw “ existing evidence in a new light , through the prism of our experience on September 11 “ . | equivalent |
| I like to eat peanutbutter for breakfast | I like to play football | not_equivalent |
How to configure T5 task for MRPC and pre-process text
.setTask('mrpc sentence1:) and prefix second sentence with sentence2:
Example pre-processed input for T5 MRPC - Binary Paraphrasing/ sentence similarity
mrpc
sentence1: We acted because we saw the existing evidence in a new light , through the prism of our experience on 11 September , " Rumsfeld said .
sentence2: Rather , the US acted because the administration saw " existing evidence in a new light , through the prism of our experience on September 11",
Regressive Sentence similarity/ Paraphrasing
Measures how similar two sentences are on a scale from 0 to 5 with 21 classes representing a regressive label.
This is a sub-task of GLUE and based on STSB - Regressive semantic sentence similarity.
t5 = nlp.load('en.t5.base')
# Set the task on T5
t5['t5'].setTask('stsb ')
# define Data, add additional tags between sentences
data = [
''' sentence1: What attributes would have made you highly desirable in ancient Rome?
sentence2: How I GET OPPERTINUTY TO JOIN IT COMPANY AS A FRESHER?'
'''
,
'''
sentence1: What was it like in Ancient rome?
sentence2: What was Ancient rome like?
''',
'''
sentence1: What was live like as a King in Ancient Rome??
sentence2: What was Ancient rome like?
'''
]
#Predict on text data with T5
t5.predict(data)
| Sentence1 | Sentence2 | prediction |
|---|---|---|
| What attributes would have made you highly desirable in ancient Rome? | How I GET OPPERTINUTY TO JOIN IT COMPANY AS A FRESHER? | 0 |
| What was it like in Ancient rome? | What was Ancient rome like? | 5.0 |
| What was live like as a King in Ancient Rome?? | What is it like to live in Rome? | 3.2 |
How to configure T5 task for stsb and pre-process text
.setTask('stsb sentence1:) and prefix second sentence with sentence2:
Example pre-processed input for T5 STSB - Regressive semantic sentence similarity
stsb
sentence1: What attributes would have made you highly desirable in ancient Rome?
sentence2: How I GET OPPERTINUTY TO JOIN IT COMPANY AS A FRESHER?',
Grammar Checking
Grammar checking with T5 example)
Judges if a sentence is grammatically acceptable.
Based on CoLA - Binary Grammatical Sentence acceptability classification
pipe = nlp.load('grammar_correctness')
# Set the task on T5
pipe['t5'].setTask('cola sentence: ')
# define Data
data = ['Anna and Mike is going skiing and they is liked is','Anna and Mike like to dance']
#Predict on text data with T5
pipe.predict(data)
| sentence | prediction |
|---|---|
| Anna and Mike is going skiing and they is liked is | unacceptable |
| Anna and Mike like to dance | acceptable |
Bart Transformer
Bart is based on transformer architecture and is designed to handle a wide range of natural language processing tasks such as text generation, summarization, and machine translation. Based on BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension Transformer
model = nlu.load('en.seq2seq.distilbart_cnn_12_6')
# Set the task on T5
model['bart_transformer'].setTask("summarize: ")
model['bart_transformer'].setMaxOutputLength(200)
# define Data
data = '''LONDON, England (Reuters) -- Harry Potter star Daniel Radcliffe gains access to a reported £20 million ($41.1 million) fortune as he turns 18 on Monday, but he insists the money won't cast a spell on him. Daniel Radcliffe as Harry Potter in "Harry Potter and the Order of the Phoenix" To the disappointment of gossip columnists around the world, the young actor says he has no plans to fritter his cash away on fast cars, drink and celebrity parties. "I don't plan to be one of those people who, as soon as they turn 18, suddenly buy themselves a massive sports car collection or something similar," he told an Australian interviewer earlier this month. "I don't think I'll be particularly extravagant. "The things I like buying are things that cost about 10 pounds -- books and CDs and DVDs." At 18, Radcliffe will be able to gamble in a casino, buy a drink in a pub or see the horror film "Hostel: Part II," currently six places below his number one movie on the UK box office chart. Details of how he'll mark his landmark birthday are under wraps. His agent and publicist had no comment on his plans. "I'll definitely have some sort of party," he said in an interview. "Hopefully none of you will be reading about it." Radcliffe's earnings from the first five Potter films have been held in a trust fund which he has not been able to touch. Despite his growing fame and riches, the actor says he is keeping his feet firmly on the ground. "People are always looking to say 'kid star goes off the rails,'" he told reporters last month. "But I try very hard not to go that way because it would be too easy for them." His latest outing as the boy wizard in "Harry Potter and the Order of the Phoenix" is breaking records on both sides of the Atlantic and he will reprise the role in the last two films. Watch I-Reporter give her review of Potter's latest » . There is life beyond Potter, however. The Londoner has filmed a TV movie called "My Boy Jack," about author Rudyard Kipling and his son, due for release later this year. He will also appear in "December Boys," an Australian film about four boys who escape an orphanage. Earlier this year, he made his stage debut playing a tortured teenager in Peter Shaffer's "Equus." Meanwhile, he is braced for even closer media scrutiny now that he's legally an adult: "I just think I'm going to be more sort of fair game," he told Reuters. E-mail to a friend . Copyright 2007 Reuters. All rights reserved.This material may not be published, broadcast, rewritten, or redistributed.'''
#Predict on text data with T5
df = model.predict(data)
| text | generated |
|---|---|
| LONDON, England (Reuters) – Harry Potter star Daniel Radcliffe gains access to a reported £20 million ($41.1 million) fortune as he turns 18 on Monday, but he insists the money won’t cast a spell on him. Daniel Radcliffe as Harry Potter in “Harry Potter and the Order of the Phoenix” To the disappointment of gossip columnists around the world, the young actor says he has no plans to fritter his cash away on fast cars, drink and celebrity parties. “I don’t plan to be one of those people who, as soon as they turn 18, suddenly buy themselves a massive sports car collection or something similar,” he told an Australian interviewer earlier this month. “I don’t think I’ll be particularly extravagant. “The things I like buying are things that cost about 10 pounds – books and CDs and DVDs.” At 18, Radcliffe will be able to gamble in a casino, buy a drink in a pub or see the horror film “Hostel: Part II,” currently six places below his number one movie on the UK box office chart. Details of how he’ll mark his landmark birthday are under wraps. His agent and publicist had no comment on his plans. “I’ll definitely have some sort of party,” he said in an interview. “Hopefully none of you will be reading about it.” Radcliffe’s earnings from the first five Potter films have been held in a trust fund which he has not been able to touch. Despite his growing fame and riches, the actor says he is keeping his feet firmly on the ground. “People are always looking to say ‘kid star goes off the rails,’” he told reporters last month. “But I try very hard not to go that way because it would be too easy for them.” His latest outing as the boy wizard in “Harry Potter and the Order of the Phoenix” is breaking records on both sides of the Atlantic and he will reprise the role in the last two films. Watch I-Reporter give her review of Potter’s latest » . There is life beyond Potter, however. The Londoner has filmed a TV movie called “My Boy Jack,” about author Rudyard Kipling and his son, due for release later this year. He will also appear in “December Boys,” an Australian film about four boys who escape an orphanage. Earlier this year, he made his stage debut playing a tortured teenager in Peter Shaffer’s “Equus.” Meanwhile, he is braced for even closer media scrutiny now that he’s legally an adult: “I just think I’m going to be more sort of fair game,” he told Reuters. E-mail to a friend . Copyright 2007 Reuters. All rights reserved.This material may not be published, broadcast, rewritten, or redistributed. | Daniel Radcliffe gains access to a reported � 20 million $ 41 . 1 million fortune . Harry Potter star Daniel Radcliffe turns 18 on Monday . Radcliffe insists the money won’t cast a spell on him . |
Open book question answering
T5 Open and Closed Book question answering tutorial
You can imagine an open book question similar to an examen where you are allowed to bring in text documents or cheat sheets that help you answer questions in an examen. Kinda like bringing a history book to an history examen.
In T5's terms, this means the model is given a question and an additional piece of textual information or so called context.
This enables the T5 model to answer questions on textual datasets like medical records,newsarticles , wiki-databases , stories and movie scripts , product descriptions, ‘legal documents’ and many more.
You can answer open book question in 1 line of code, leveraging the latest NLU release and Google’s T5.
All it takes is :
nlp.load('answer_question').predict("""
Where did Jebe die?
context: Ghenkis Khan recalled Subtai back to Mongolia soon afterwards,
and Jebe died on the road back to Samarkand""")
>>> Output: Samarkand
Example for answering medical questions based on medical context
question ='''
What does increased oxygen concentrations in the patient’s lungs displace?
context: Hyperbaric (high-pressure) medicine uses special oxygen chambers to increase the partial pressure of O 2 around the patient and, when needed, the medical staff.
Carbon monoxide poisoning, gas gangrene, and decompression sickness (the ’bends’) are sometimes treated using these devices. Increased O 2 concentration in the lungs helps to displace carbon monoxide from the heme group of hemoglobin.
Oxygen gas is poisonous to the anaerobic bacteria that cause gas gangrene, so increasing its partial pressure helps kill them. Decompression sickness occurs in divers who decompress too quickly after a dive, resulting in bubbles of inert gas, mostly nitrogen and helium, forming in their blood. Increasing the pressure of O 2 as soon as possible is part of the treatment.
'''
#Predict on text data with T5
nlp.load('answer_question').predict(question)
>>> Output: carbon monoxide
Take a look at this example on a recent news article snippet :
question1 = 'Who is Jack ma?'
question2 = 'Who is founder of Alibaba Group?'
question3 = 'When did Jack Ma re-appear?'
question4 = 'How did Alibaba stocks react?'
question5 = 'Whom did Jack Ma meet?'
question6 = 'Who did Jack Ma hide from?'
# from https://www.bbc.com/news/business-55728338
news_article_snippet = """ context:
Alibaba Group founder Jack Ma has made his first appearance since Chinese regulators cracked down on his business empire.
His absence had fuelled speculation over his whereabouts amid increasing official scrutiny of his businesses.
The billionaire met 100 rural teachers in China via a video meeting on Wednesday, according to local government media.
Alibaba shares surged 5% on Hong Kong's stock exchange on the news.
"""
# join question with context, works with Pandas DF aswell!
questions = [
question1+ news_article_snippet,
question2+ news_article_snippet,
question3+ news_article_snippet,
question4+ news_article_snippet,
question5+ news_article_snippet,
question6+ news_article_snippet,]
nlp.load('answer_question').predict(questions)
This will output a Pandas Dataframe similar to this :
| Answer | Question |
|---|---|
| Alibaba Group founder | Who is Jack ma? |
| Jack Ma | Who is founder of Alibaba Group? |
| Wednesday | When did Jack Ma re-appear? |
| surged 5% | How did Alibaba stocks react? |
| 100 rural teachers | Whom did Jack Ma meet? |
| Chinese regulators | Who did Jack Ma hide from? |
Closed book question answering
T5 Open and Closed Book question answering tutorial
A closed book question is the exact opposite of a open book question. In an examen scenario, you are only allowed to use what you have memorized in your brain and nothing else.
In T5's terms this means that T5 can only use it’s stored weights to answer a question and is given no aditional context.
T5 was pre-trained on the C4 dataset which contains petabytes of web crawling data collected over the last 8 years, including Wikipedia in every language.
This gives T5 the broad knowledge of the internet stored in it’s weights to answer various closed book questions
You can answer closed book question in 1 line of code, leveraging the latest NLU release and Google’s T5.
You need to pass one string to NLU, which starts which a question and is followed by a context: tag and then the actual context contents.
All it takes is :
nlp.load('en.t5').predict('Who is president of Nigeria?')
>>> Muhammadu Buhari
nlp.load('en.t5').predict('What is the most spoken language in India?')
>>> Hindi
nlp.load('en.t5').predict('What is the capital of Germany?')
>>> Berlin