There is overwhelming evidence from both academic research and industry benchmarks that domain-specific, task-optimized large language models consistently outperform general-purpose LLMs in healthcare. At John Snow Labs, we’ve developed a focused pair of Medical LLMs purpose-built for clinical, biomedical, and life sciences applications.
Medical LLM Medium and Medical LLM Small are healthcare models benchmarked head-to-head against the leading closed frontier systems — GPT 5.5, Claude Opus 4.8, and Gemini 3.5 Flash — across the full spectrum of medical evaluation. Both are multimodal (text + image) and carry a locked John Snow Labs identity. Closed frontier models can’t run on your data — ours can: licensed for on-premise or private-cloud deployment, HIPAA-friendly, without giving up frontier-grade medical accuracy.
Our models are designed to deliver best-in-class performance across a wide range of medical tasks—from clinical reasoning and diagnostics to medical research comprehension and genetic analysis.
Medical LLMs Offering
| Model Name | Recommended GPU Memory | Max Sequence Length | Max KV-Cache | Tensor Parallel Sizes |
|---|---|---|---|---|
| Medical LLM Medium | ~132 GB | 256K | 69 GB | 2, 4 |
| Medical LLM Small | ~56 GB | 256K | 34 GB | 1, 2, 4 |
| Vision-OCR-LLM | ~62 GB | 40K | 5 GB | 2, 4, 8 |
| Vision-OCR-Structured-LLM | ~62 GB | 40K | 5 GB | 2, 4, 8 |
Note: All memory calculations are based on half-precision (fp16/bf16) weights. Recommended GPU Memory considers the model size and the maximum key-value cache at the model’s maximum sequence length. These calculations follow the guidelines from DJL’s LMI Deployment Guide.
- Medical LLM Small — Compact. A compact medical LLM that outperforms much larger general models on MedHELM while running on a single commodity GPU.
- Medical LLM Medium — Flagship. Our best model — the #1 MedHELM mean win rate in this comparison, leading frontier closed models on OpenMed.
Introduction
John Snow Labs’ Medical Large Language Models advance Healthcare AI by setting state-of-the-art accuracy on medical LLM benchmarks while remaining small enough to deploy privately. This advances what’s achievable across real-world use cases including clinical assessment, medical question answering, biomedical research synthesis, and diagnostic decision support.
What makes this release special is how strongly the models perform relative to their compute footprint. Medical LLM Medium posts the highest MedHELM mean win rate of every model tested (77.78) and leads the best closed frontier model on OpenMed (93.99). Medical LLM Small clears an OpenMed average of 90.63, making it practical for everyday use in hospitals and clinics where cost, speed, and privacy matter.
OpenMed Benchmark Performance
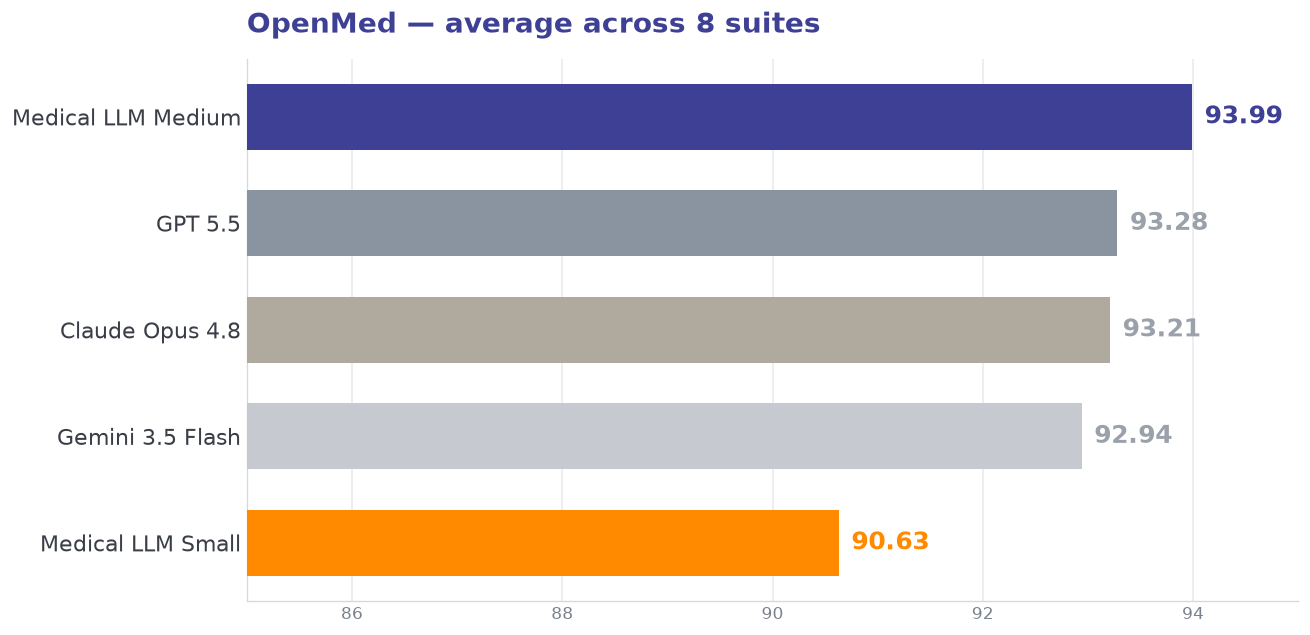
The OpenMed evaluation framework represents one of the most rigorous testing environments for medical AI models, covering a broad spectrum of medical knowledge and clinical reasoning capabilities. It spans eight medical multiple-choice suites — MedQA, PubMedQA, and six MMLU medical subjects. Medical LLM Medium leads the best frontier model, while Medical LLM Small is remarkably strong for its size.
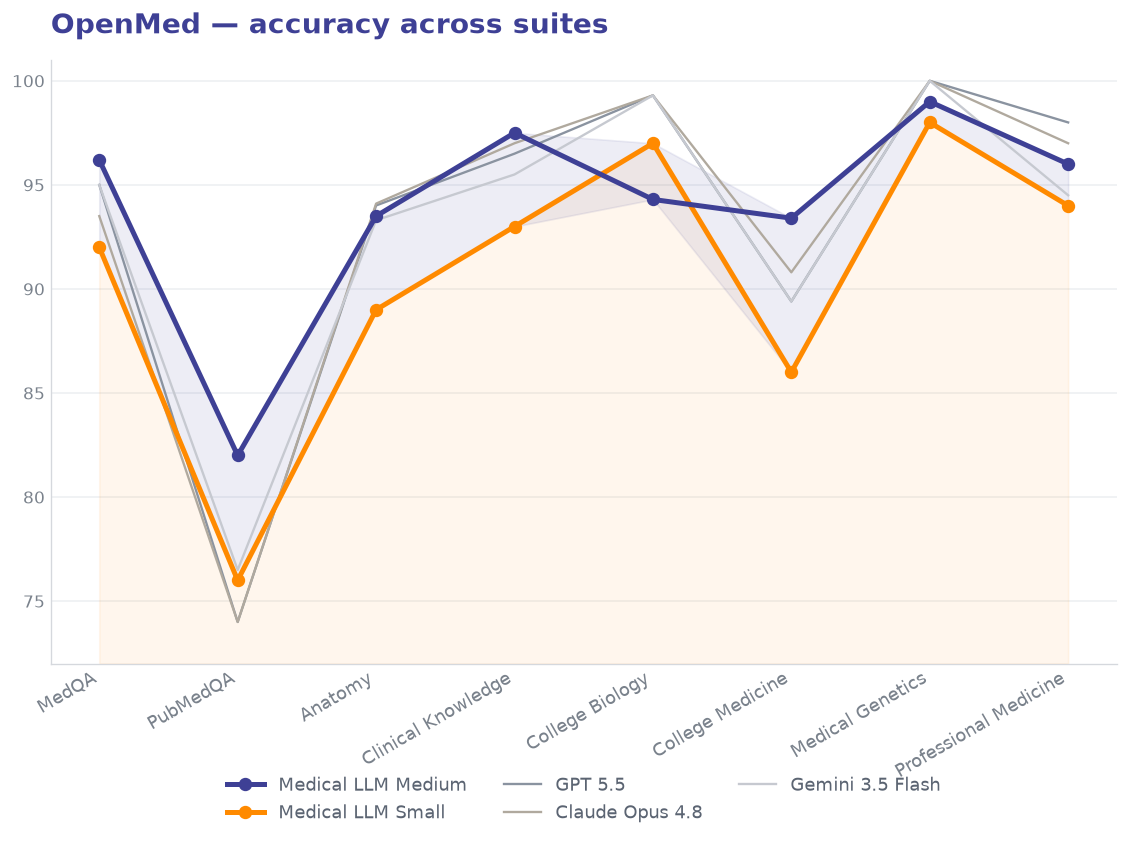
| Model | MedQA | PubMedQA | Anatomy | Clinical Knowledge | College Biology | College Medicine | Medical Genetics | Professional Medicine | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Medical LLM Medium | 96.2 | 82 | 93.5 | 97.5 | 94.3 | 93.4 | 99 | 96 | 93.99 |
| Medical LLM Small | 92 | 76 | 89 | 93 | 97 | 86 | 98 | 94 | 90.63 |
| GPT 5.5 | 95 | 74 | 94.01 | 96.5 | 99.3 | 89.4 | 100 | 98 | 93.28 |
| Claude Opus 4.8 | 93.5 | 74 | 94.1 | 97 | 99.3 | 90.8 | 100 | 97 | 93.21 |
| Gemini 3.5 Flash | 95 | 76.5 | 93.3 | 95.5 | 99.3 | 89.4 | 100 | 94.5 | 92.94 |
Frontier-leading accuracy — private by design. Medical LLM Medium scores 93.99 on OpenMed — ahead of GPT 5.5 (93.28) and Claude Opus 4.8 (93.21) — while being licensed for deployment inside your firewall. Medical LLM Small clears 90 while staying compact enough to run on a single commodity GPU.
JSL-LLM MedHELM Benchmark Analysis
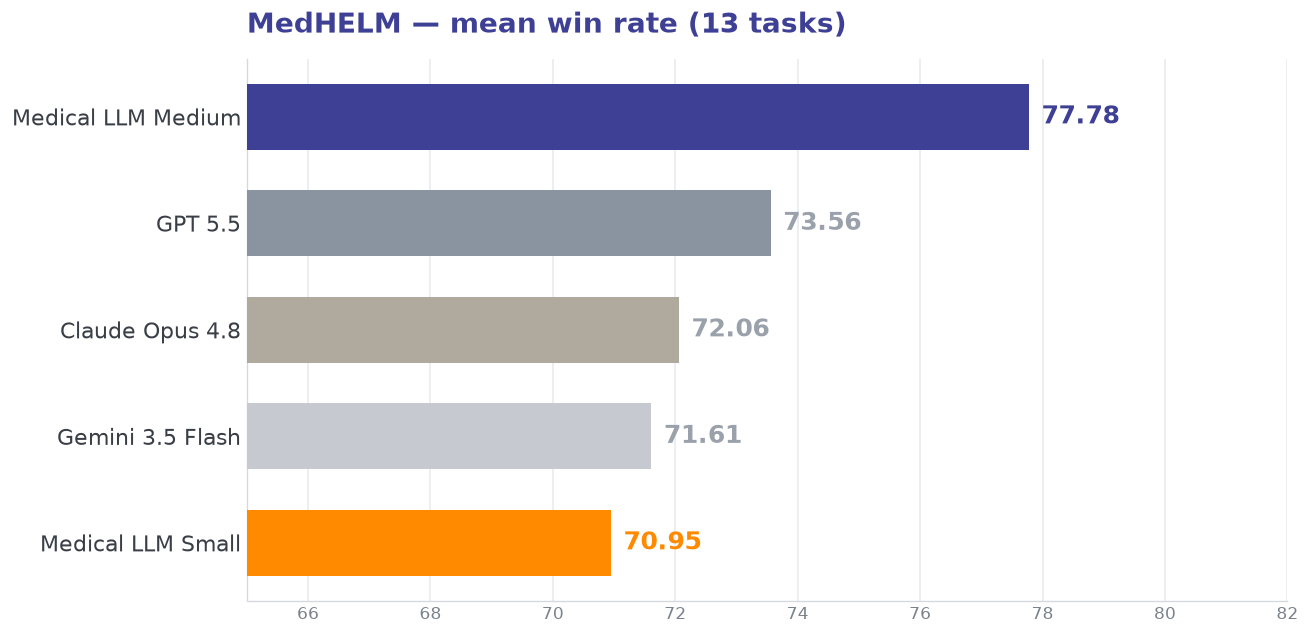
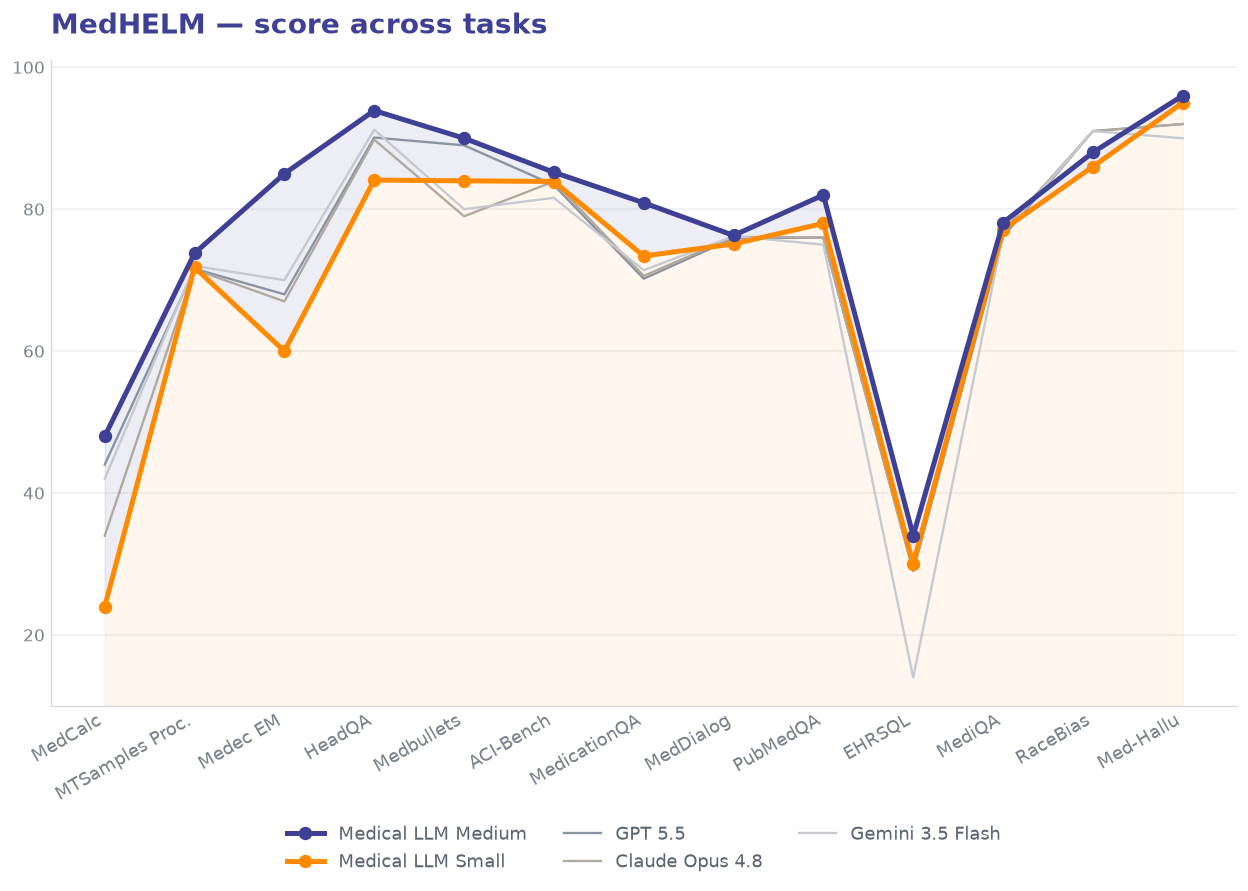
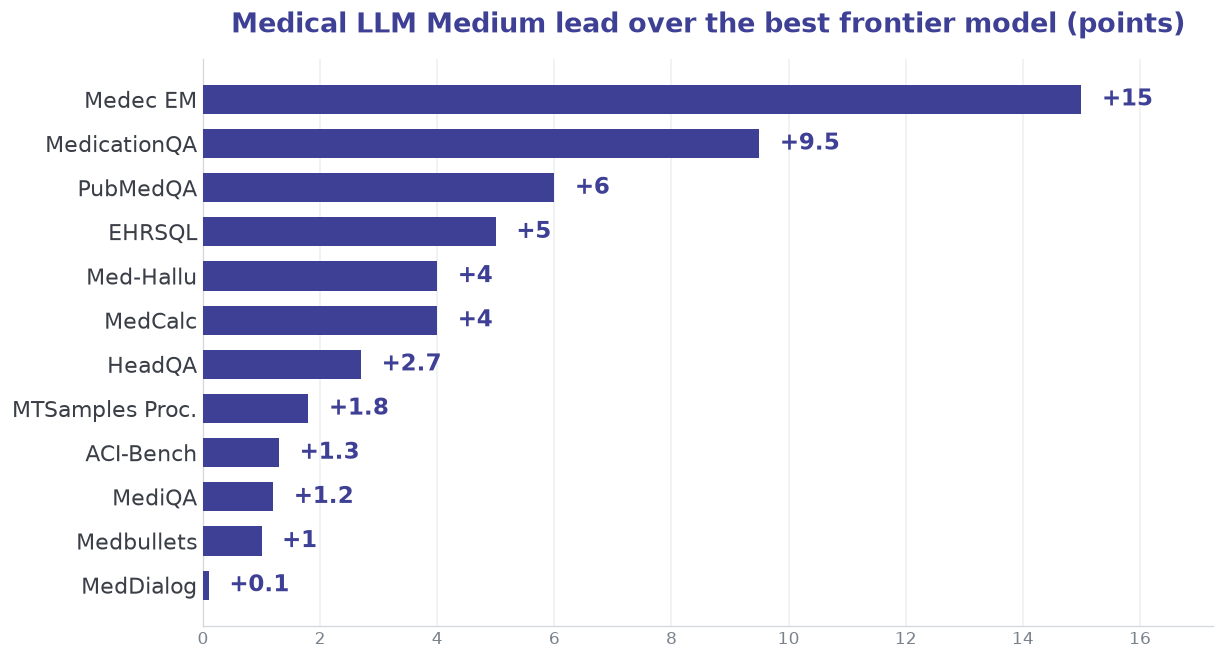
MedHELM spans thirteen clinical tasks across documentation, coding, safety, dialogue, and reasoning. Medical LLM Medium posts the highest mean win rate of every model tested, and records the best score on 12 of the 13 tasks.
| Benchmark | Medical LLM Medium | Medical LLM Small | GPT 5.5 | Claude Opus 4.8 | Gemini 3.5 Flash |
|---|---|---|---|---|---|
| Mean win rate | 77.78 | 70.95 | 73.56 | 72.06 | 71.61 |
| MedCalc | 48 | 24 | 44 | 34 | 42 |
| MTSamples Proc. | 73.8 | 71.8 | 71.6 | 71.5 | 72 |
| Medec EM | 85 | 60 | 68 | 67 | 70 |
| HeadQA | 93.9 | 84.1 | 90.1 | 89.8 | 91.2 |
| Medbullets | 90 | 84 | 89 | 79 | 80 |
| ACI-Bench | 85.2 | 83.9 | 83.4 | 83.9 | 81.6 |
| MedicationQA | 80.9 | 73.4 | 70.2 | 70.6 | 71.4 |
| MedDialog | 76.3 | 75.1 | 75.9 | 76.1 | 76.2 |
| PubMedQA | 82 | 78 | 76 | 76 | 75 |
| EHRSQL | 34 | 30 | 29 | 29 | 14 |
| MediQA | 78.1 | 77.1 | 76.1 | 76.9 | 76.5 |
| RaceBias | 88 | 86 | 91 | 91 | 91 |
| Med-Hallu | 96 | 95 | 92 | 92 | 90 |
Strongest where clinical work is hardest. Medical LLM Medium records the best score on 12 of the 13 MedHELM tasks, with its largest margins on clinical error detection (Medec +15), medication QA (+9.5), biomedical research comprehension (PubMedQA +6), and hallucination control.
How the Models Compare
Three signals matter for a clinical deployment: how often the model ranks first, whether a John Snow Labs model can match closed frontier systems, and how well it resists hallucination.
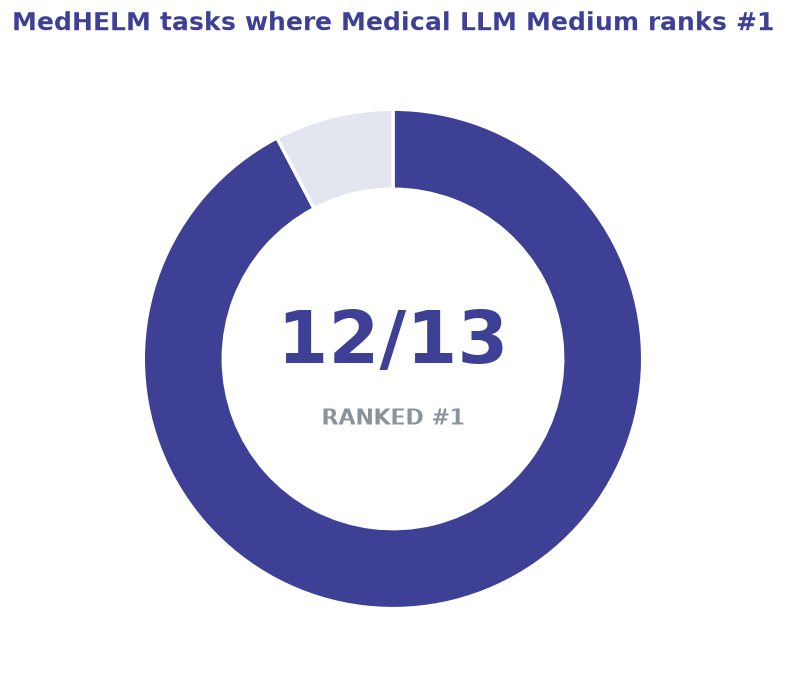
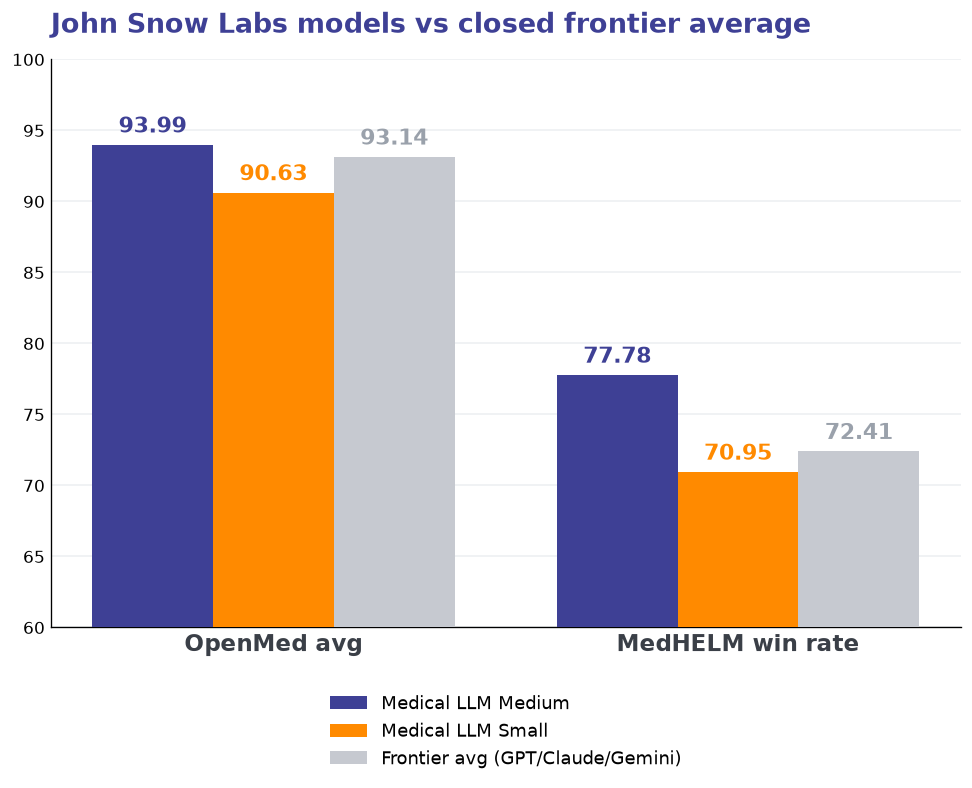
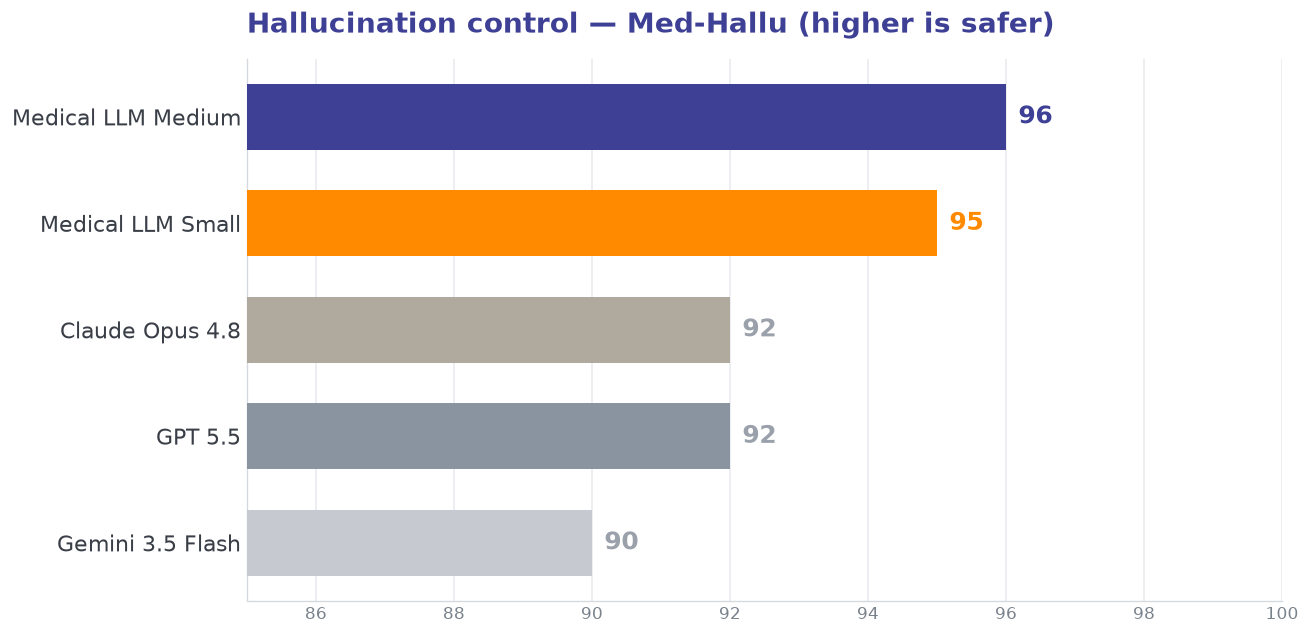
A John Snow Labs model leads the closed frontier on OpenMed (93.99 vs 93.14 average) while beating it outright on MedHELM (77.78 vs 72.41 average). On hallucination — the metric that decides whether a model is safe in front of clinicians — both John Snow Labs models rank first.
Red-Teaming Evaluation Results
Out of 1000 red-teaming questions across 148 medical categories, Medical LLM Medium passed about 940 (94%), compared to 850 for GPT-5.5 (85%), 830 for Claude Opus 4.8 (83%), and only 790 for Gemini 3.5 Flash (79%) — making Medical LLM Medium the most robust model in this evaluation and outperforming larger private models despite its smaller size.
Partner With Us
We’re committed to helping you stay at the cutting edge of medical AI. Whether you’re building decision support tools, clinical chatbots, or research platforms — our team is here to help.
Book a call with our experts to:
- Discuss your specific use case
- Get a live demo of the Medical LLMs
- Explore tailored deployment options.