Description
The Clinical Obfuscation for PDF Pipeline helps turn sensitive PDF documents into safe, shareable files. It finds personal information like names, dates, and IDs, and replaces them with fake but realistic alternatives. The replacements match the look and size of the original text, so the layout stays the same. Each piece of information is replaced the same way every time it appears. The final PDF looks like the original, but without exposing any real personal data.
Predicted Entities
HOSPITAL, NAME, PATIENT, ID, MEDICALRECORD, IDNUM, COUNTRY, LOCATION, STREET, STATE, ZIP, CONTACT, PHONE, DATE.
Live Demo Open in Colab Download
Available as Private API Endpoint



How to use
from sparknlp.pretrained import PretrainedPipeline
deid_pipeline = PretrainedPipeline("pdf_obfuscate_multilingual_name_plus", "en", "clinical/ocr")
Example
Input:
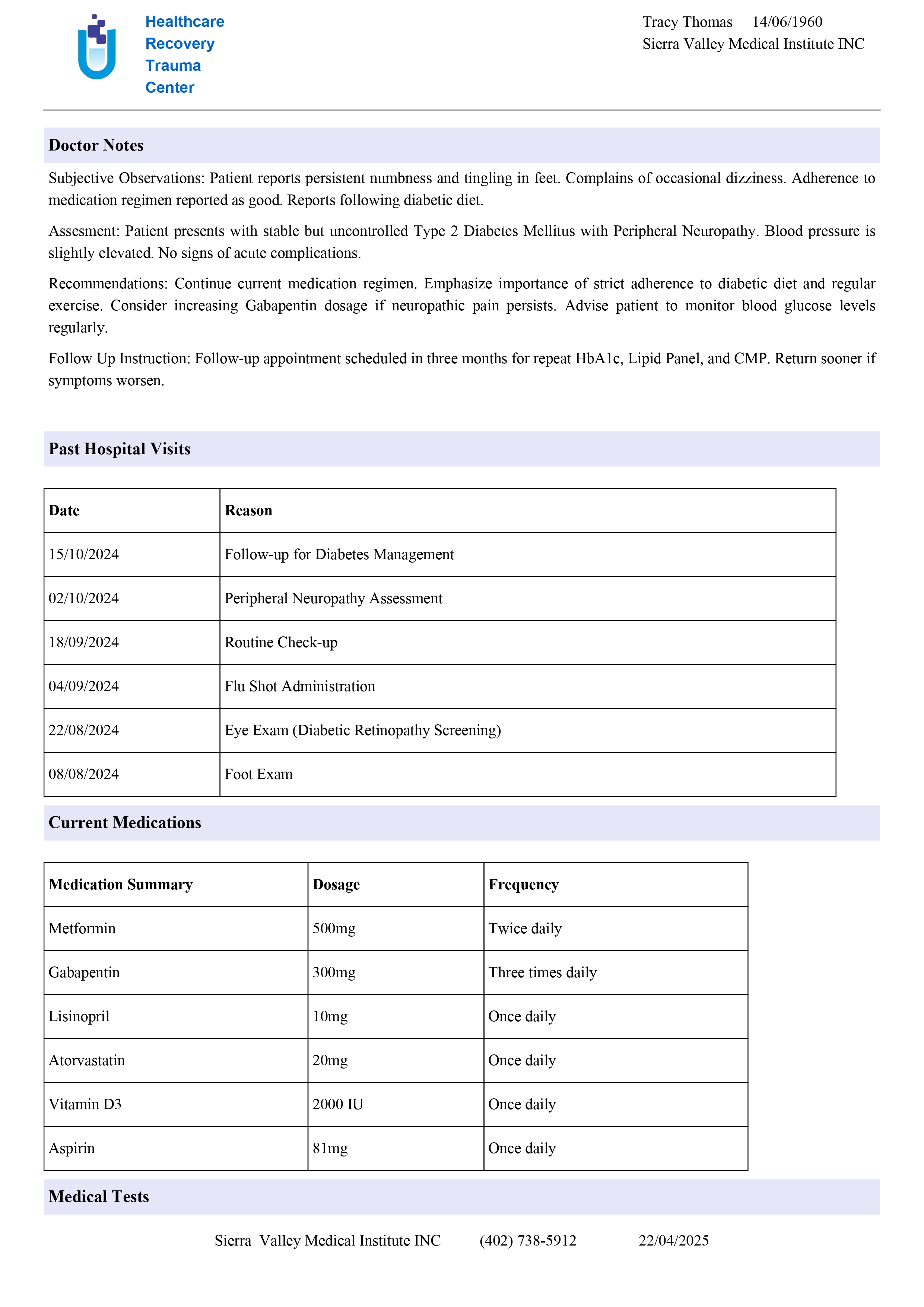
Output:

Model Information
| Model Name: | pdf_obfuscate_multilingual_name_plus |
| Type: | pipeline |
| Compatibility: | Healthcare NLP 6.0.0+ |
| License: | Licensed |
| Edition: | Official |
| Language: | en |
| Size: | 3.8 GB |
Included Models
The following models are included in the pipeline,
- PdfToImage
- ImageToText
- DocumentAssembler
- SentenceDetectorDLModel
- RegexTokenizer
- PretrainedZeroShotNER
- NerConverter
- WordEmbeddingsModel
- MedicalNerModel
- NerConverter
- XLMRobertaEmbeddings
- MedicalNerModel
- NerConverter
- ContextualParser
- ChunkConverter
- Merge
- DeIdentification
- NerOutputCleaner
- PositionFinder
- ImageDrawRegions
- ImageToPdf