Description
This pipeline can be used to mask PHI information in PDFs. The output is a PDF document, similar to the one at the input, but with black bounding boxes on top of the targeted entities.
Predicted Entities
HOSPITAL, NAME, PATIENT, ID,MEDICALRECORD, IDNUM, COUNTRY, LOCATION, STREET, STATE, ZIP, CONTACT, PHONE, DATE.
Live Demo Open in Colab Download
How to use
from sparknlp.pretrained import PretrainedPipeline
deid_pipeline = PretrainedPipeline("pdf_deid_multilingual_name_plus", "en", "clinical/ocr")
Example
Input:
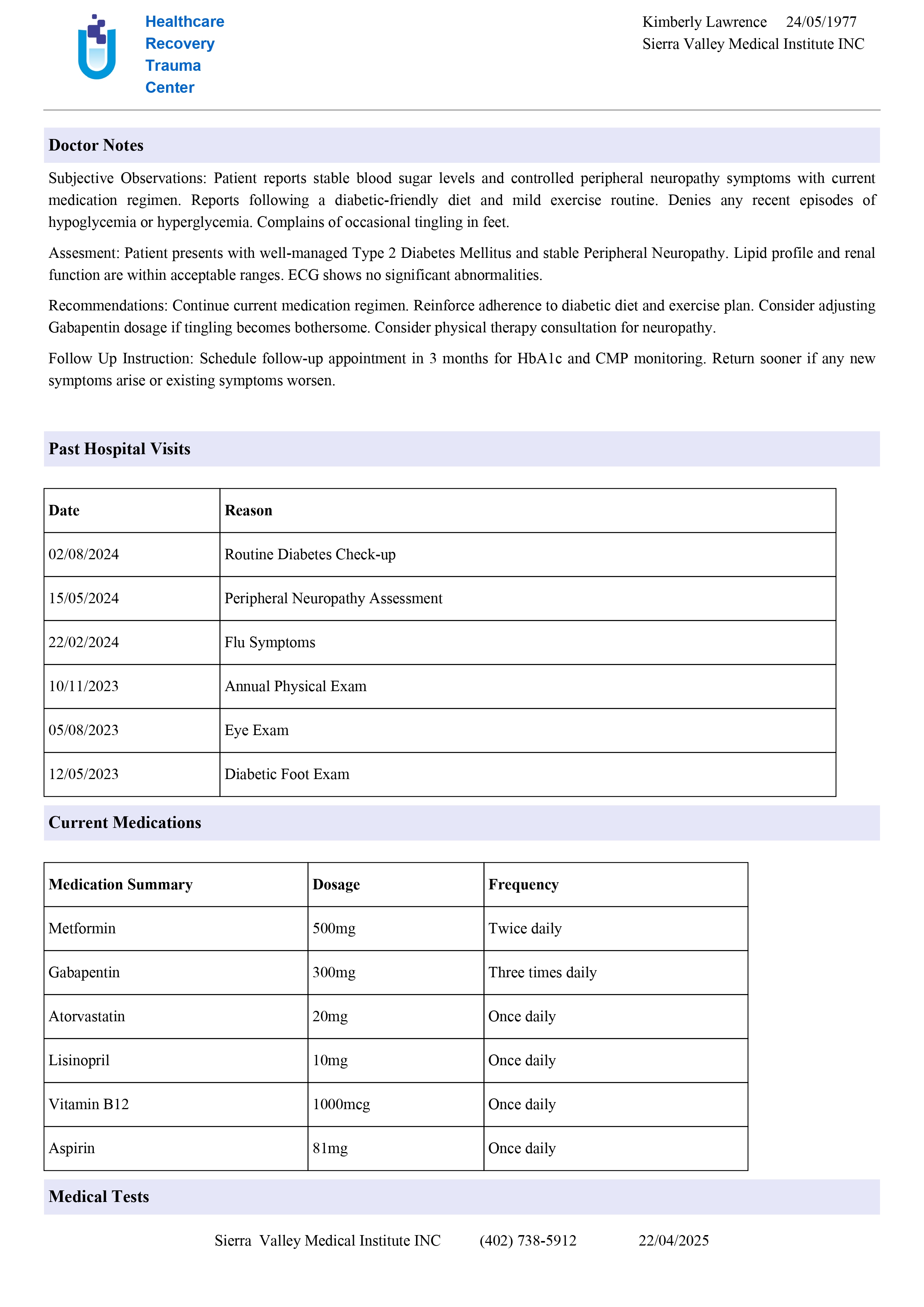
Output:

Model Information
| Model Name: | pdf_deid_multilingual_name_plus |
| Type: | pipeline |
| Compatibility: | Healthcare NLP 6.0.0+ |
| License: | Licensed |
| Edition: | Official |
| Language: | en |
| Size: | 3.8 GB |
Included Models
- PdfToImage
- ImageToText
- DocumentAssembler
- SentenceDetectorDLModel
- RegexTokenizer
- PretrainedZeroShotNER
- NerConverter
- WordEmbeddingsModel
- MedicalNerModel
- NerConverter
- XLMRobertaEmbeddings
- MedicalNerModel
- NerConverter
- ContextualParser
- ChunkConverter
- Merge
- DeIdentification
- NerOutputCleaner
- PositionFinder
- ImageDrawRegions
- ImageToPdf