Description
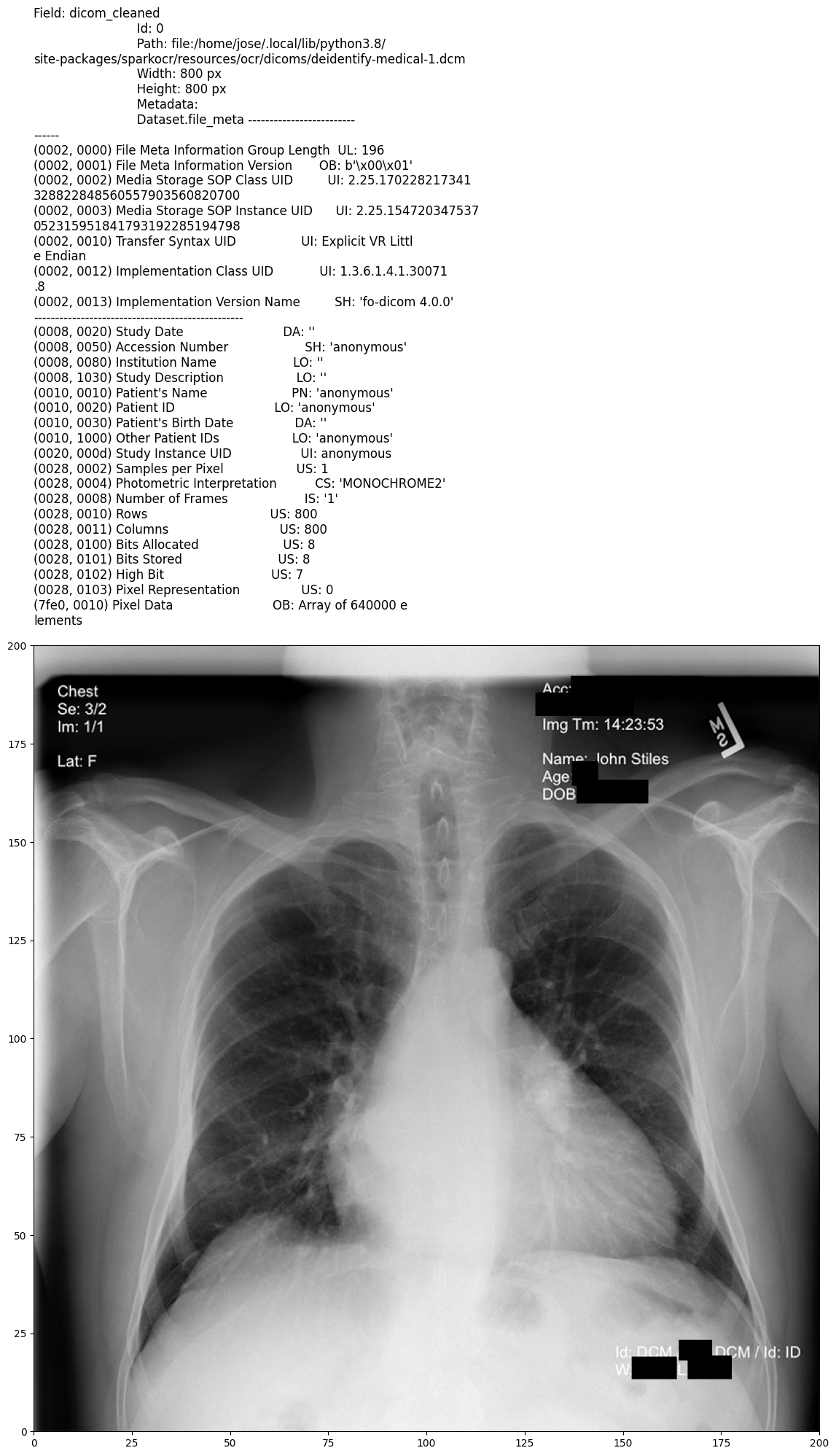
This pipeline performs the least intrusive form of DICOM de-identification, removing only the most critical personal identifiers while preserving as much metadata as possible. It ensures that Protected Health Information (PHI) is stripped from both the image and metadata, but all non-sensitive details remain intact for research and analysis.
Minimal removal: Eliminates only Personally Identifiable Information (PII) from images and the most essential metadata fields while keeping the majority of the DICOM tags untouched.
Predicted Entities
Live Demo Open in Colab Download
Available as Private API Endpoint



How to use
dicom_df = spark.read.format("binaryFile").load(dicom_path)
pipeline = PretrainedPipeline("dicom_deid_generic_augmented_minimal", "en", "clinical/ocr")
result = pipeline.transform(dicom_df).cache()
val dicom_df = spark.read.format("binaryFile").load(dicom_path)
val pipeline = new PretrainedPipeline("dicom_deid_generic_augmented_minimal", "en", "clinical/ocr")
val result = pipeline.transform(dicom_df).cache()
Example
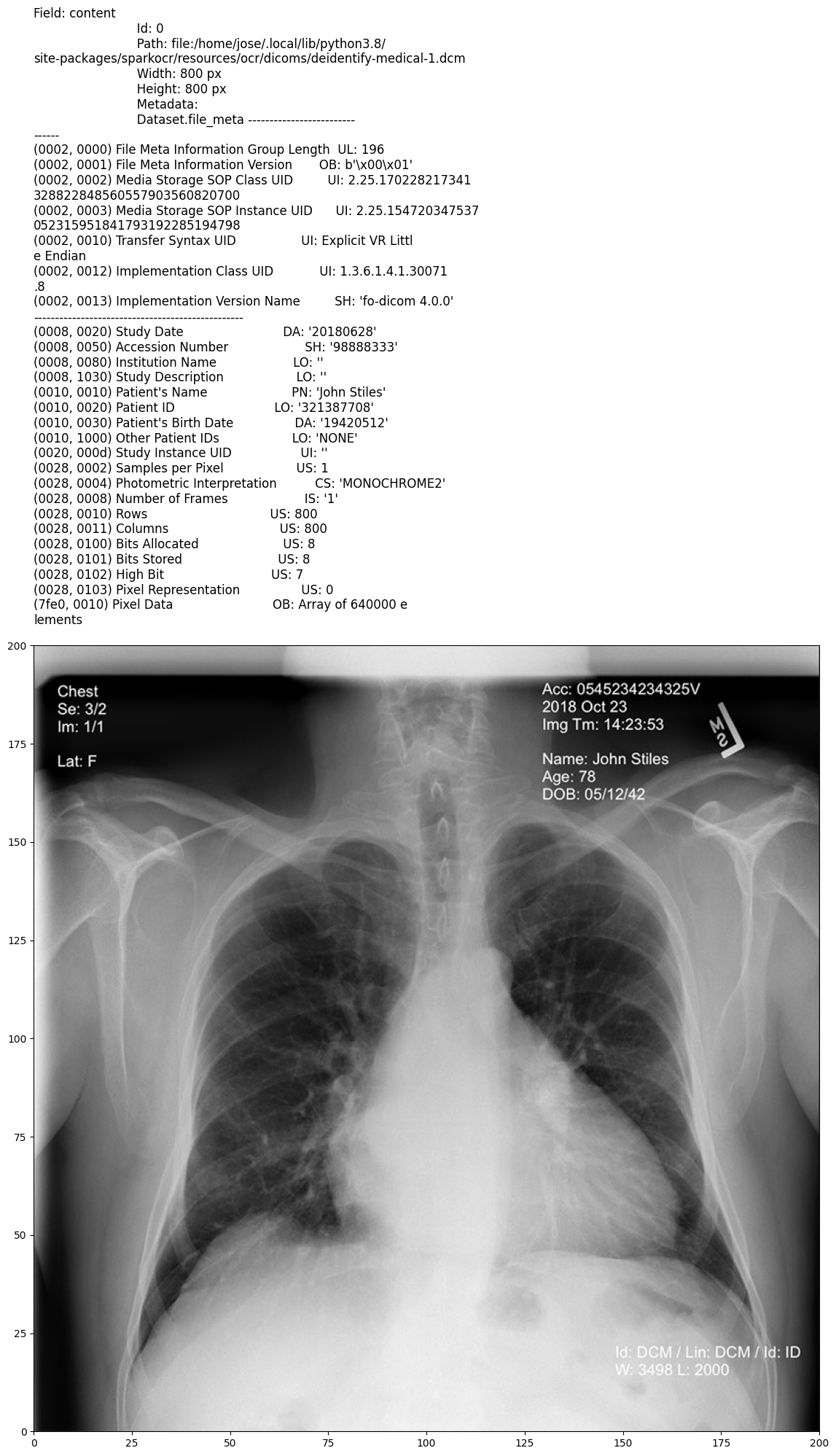
Input:
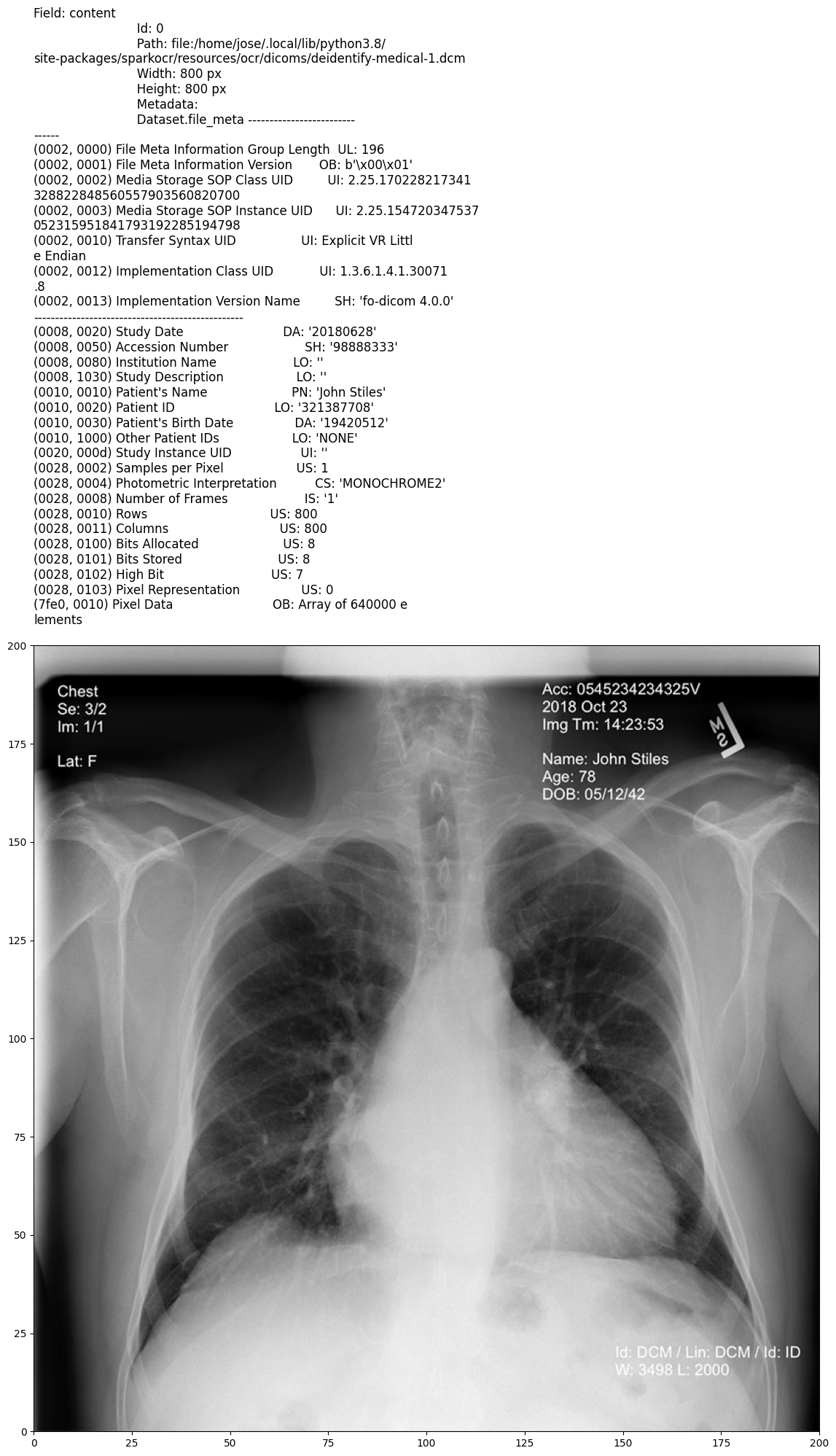
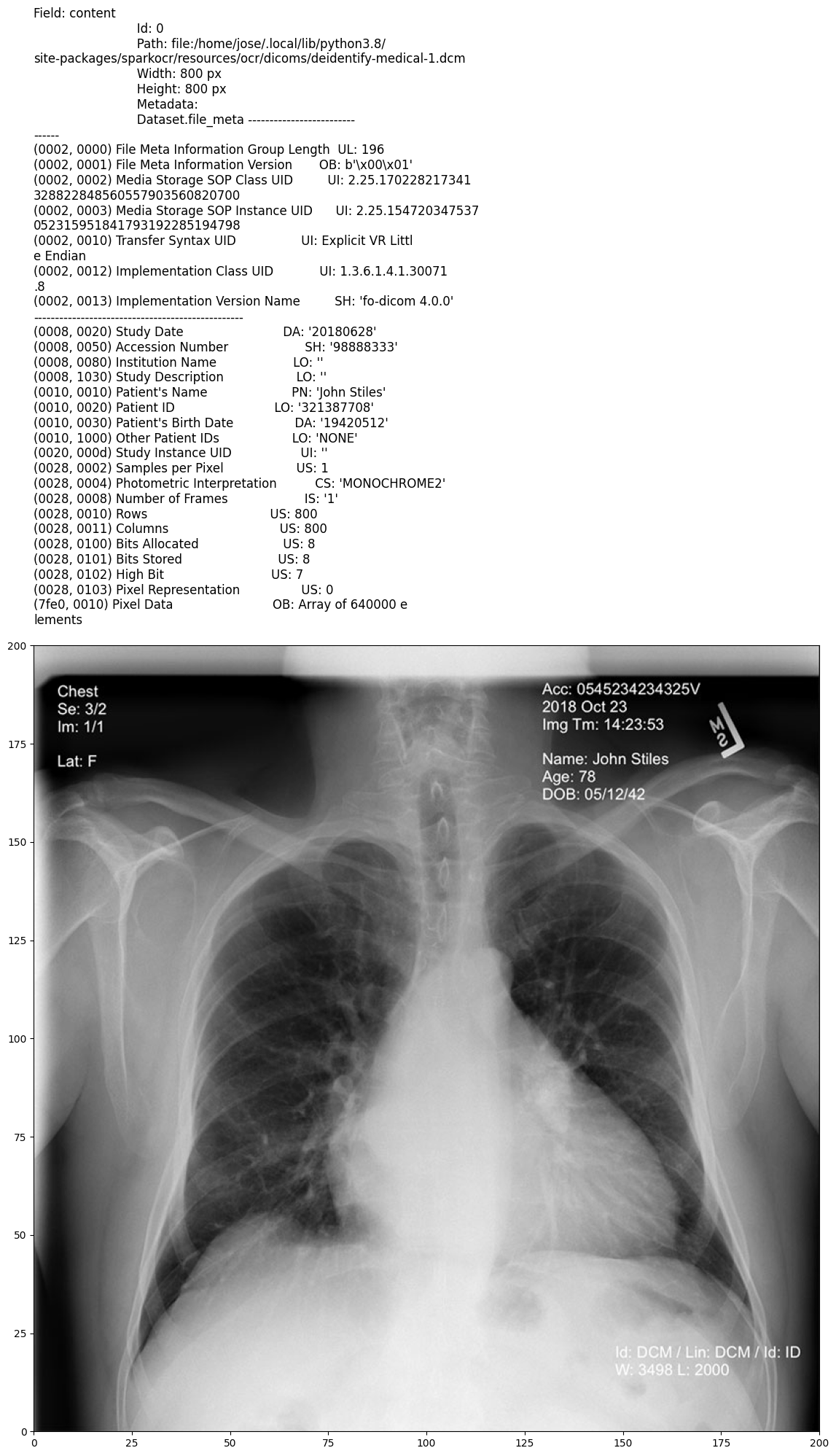
Output:
Model Information
| Model Name: | dicom_deid_generic_augmented_minimal |
| Type: | pipeline |
| Compatibility: | Visual NLP 5.5.0+ |
| License: | Licensed |
| Edition: | Official |
| Language: | en |