Description
This pipeline anonymizes DICOM metadata by replacing personal identifiers with pseudonyms instead of removing them. It ensures that PHI is no longer traceable while maintaining data integrity for longitudinal studies and collaborations.
Obfuscation mode: Removes PII from images and replaces sensitive metadata values (e.g., patient names, IDs) with randomized or pseudonymized data, preserving the overall structure and usability of the metadata.
Predicted Entities
Live Demo Open in Colab Download
Available as Private API Endpoint



How to use
dicom_df = spark.read.format("binaryFile").load(dicom_path)
pipeline = PretrainedPipeline("dicom_deid_generic_augmented_pseudonym", "en", "clinical/ocr")
result = pipeline.transform(dicom_df).cache()
val dicom_df = spark.read.format("binaryFile").load(dicom_path)
val pipeline = new PretrainedPipeline("dicom_deid_generic_augmented_pseudonym", "en", "clinical/ocr")
val result = pipeline.transform(dicom_df).cache()
Example
Input:
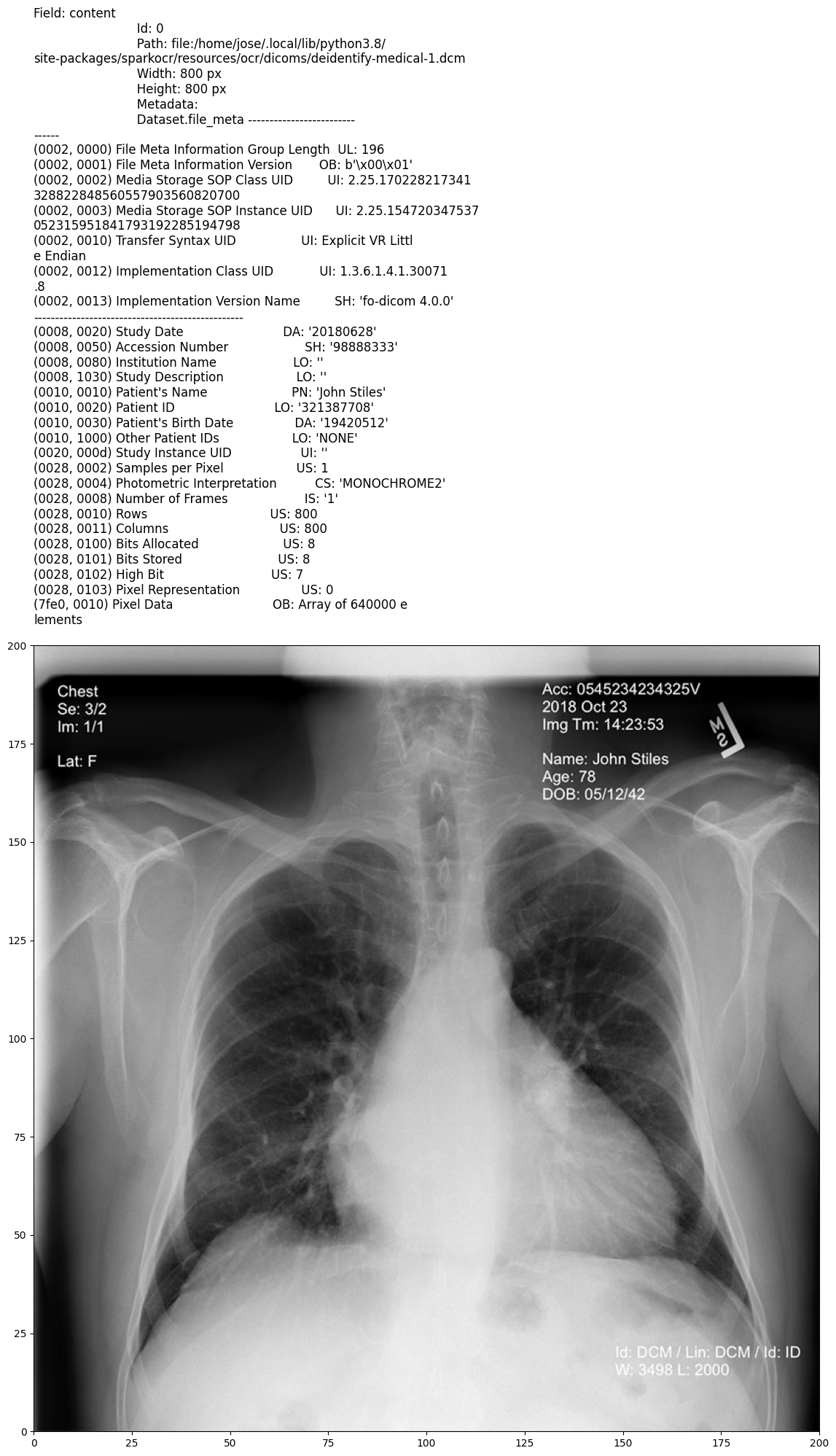
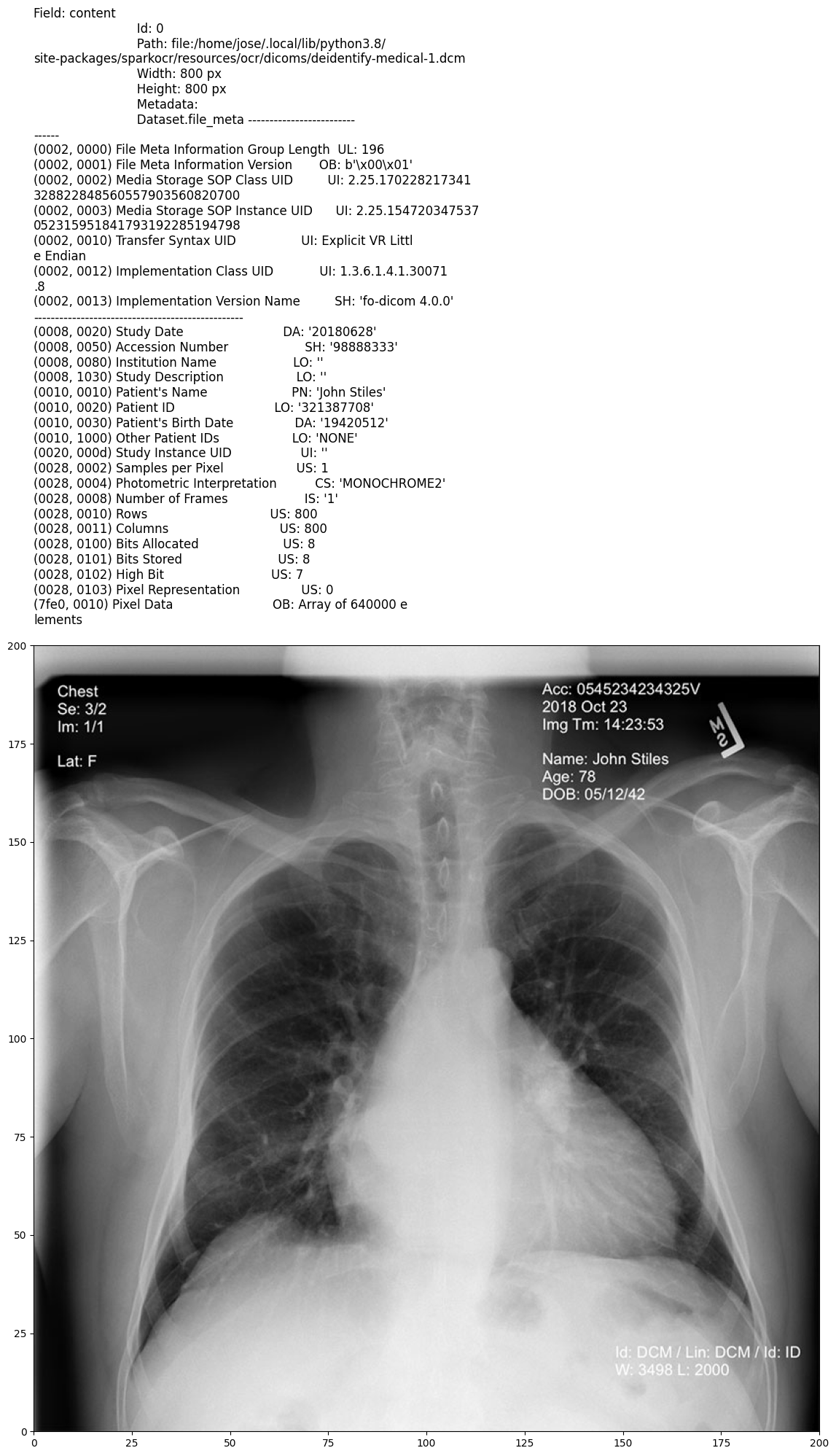
Output:
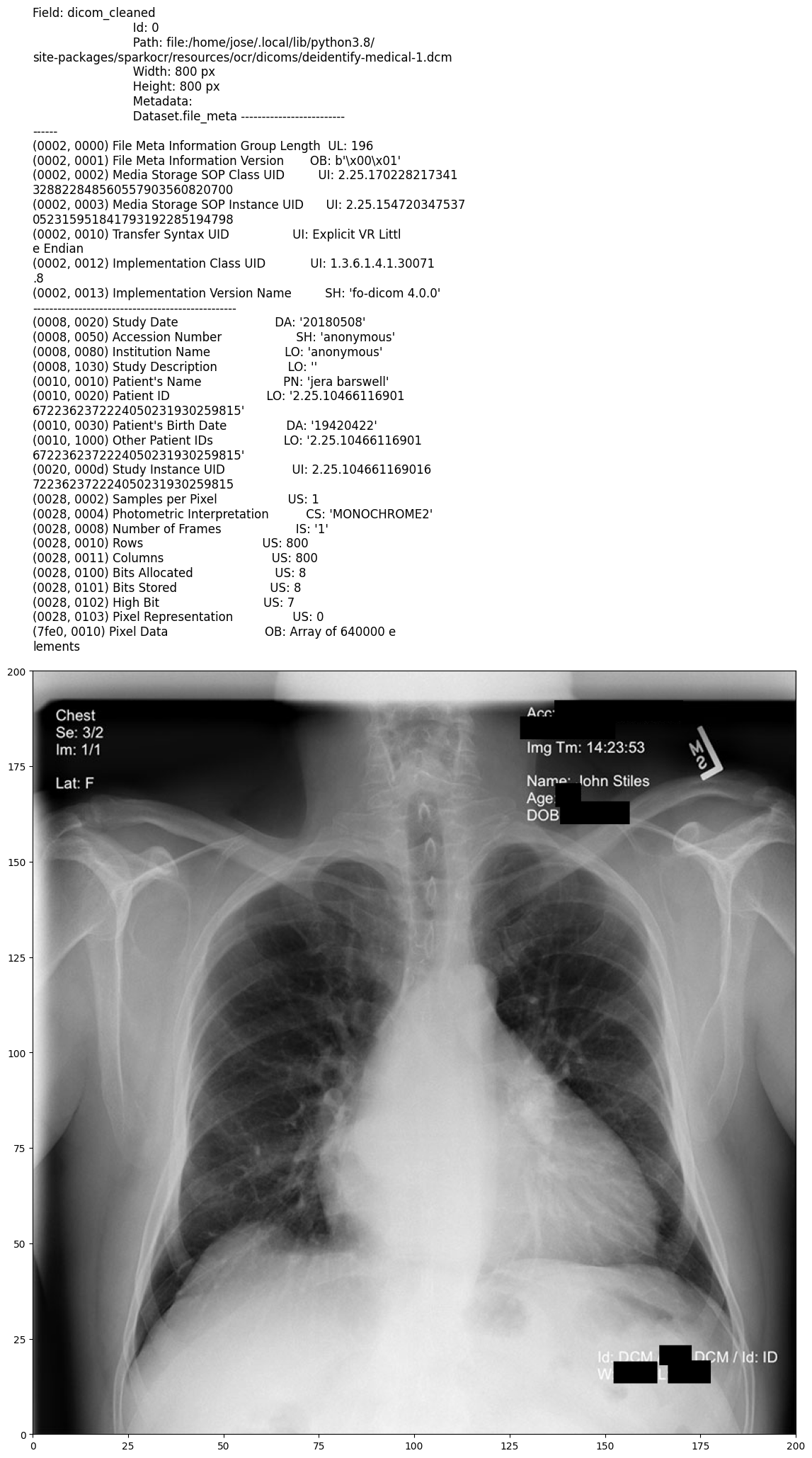
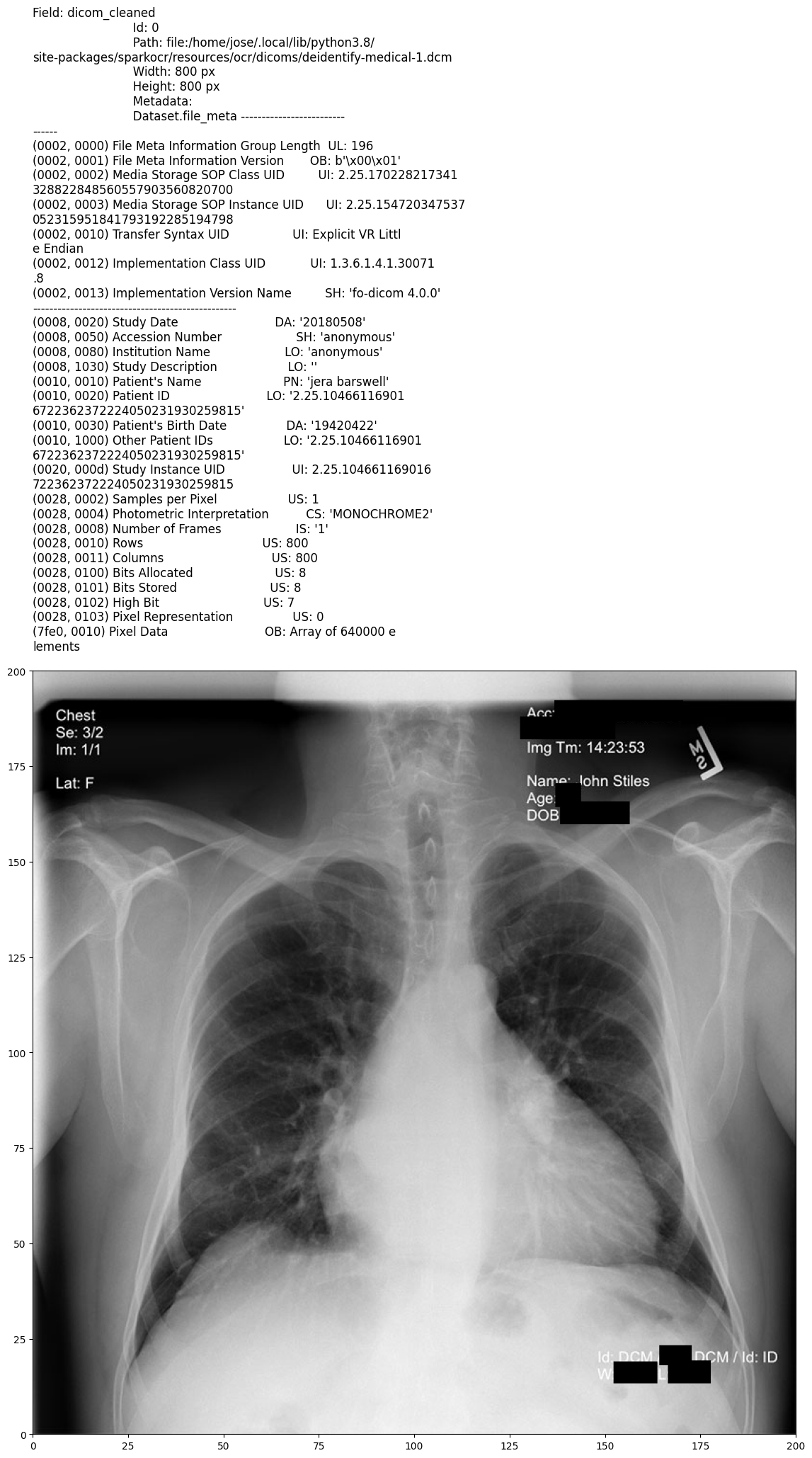
Model Information
| Model Name: | dicom_deid_generic_augmented_pseudonym |
| Type: | pipeline |
| Compatibility: | Visual NLP 5.5.0+ |
| License: | Licensed |
| Edition: | Official |
| Language: | en |