Description
This pipeline provides the highest level of anonymization by completely removing all text from both the image and metadata. It is ideal for preparing DICOM files for public sharing, research, or regulatory compliance, ensuring that no traceable information remains.
Comprehensive removal: Eliminates all visible text within images and removes or anonymizes most metadata fields, including patient identifiers, physician details, and hospital information.
Predicted Entities
Live Demo Open in Colab Download
Available as Private API Endpoint



How to use
dicom_df = spark.read.format("binaryFile").load(dicom_path)
pipeline = PretrainedPipeline("dicom_deid_full_anonymization", "en", "clinical/ocr")
result = pipeline.transform(dicom_df).cache()
val dicom_df = spark.read.format("binaryFile").load(dicom_path)
val pipeline = new PretrainedPipeline("dicom_deid_full_anonymization", "en", "clinical/ocr")
val result = pipeline.transform(dicom_df).cache()
Example
Input:
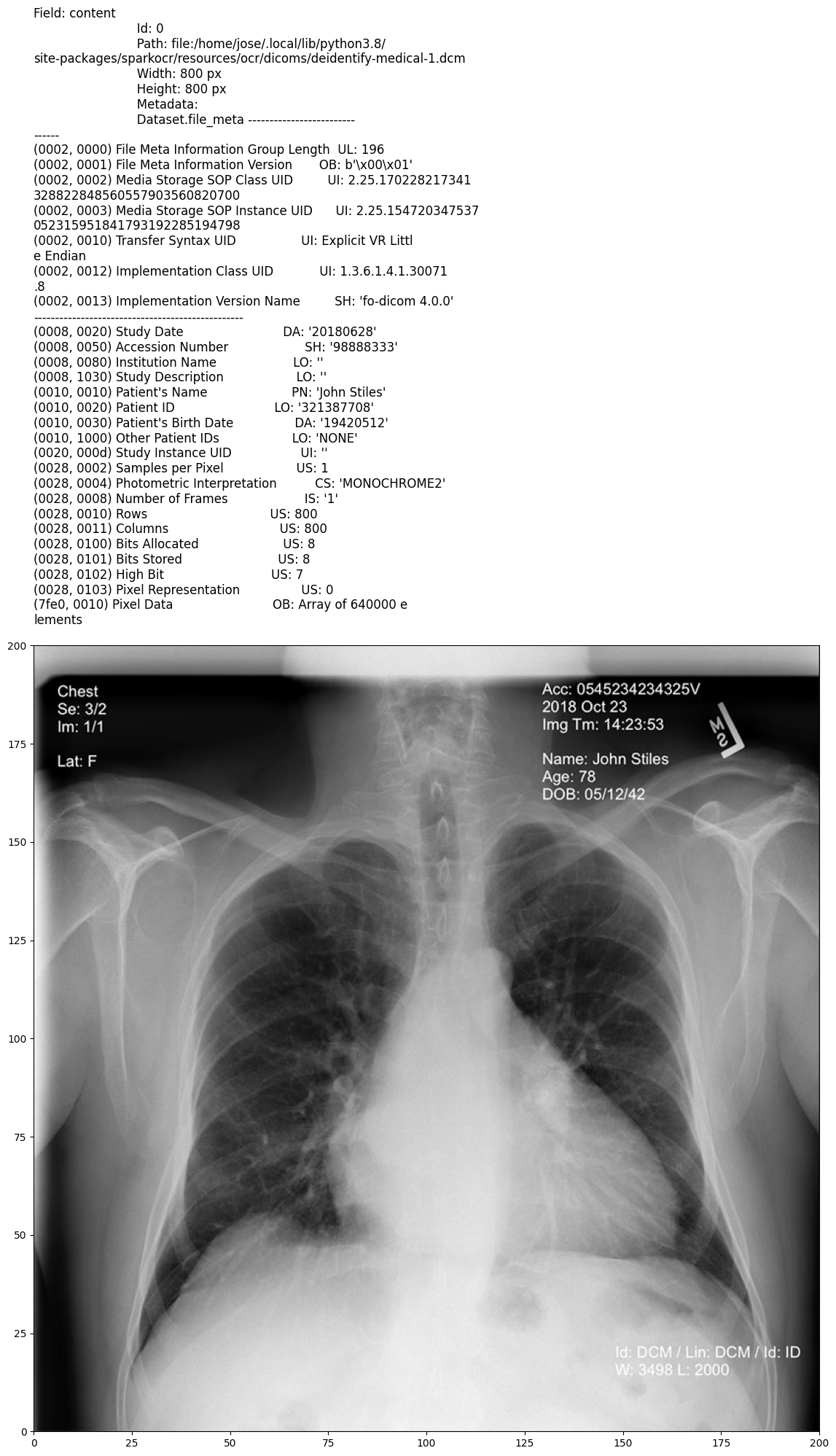
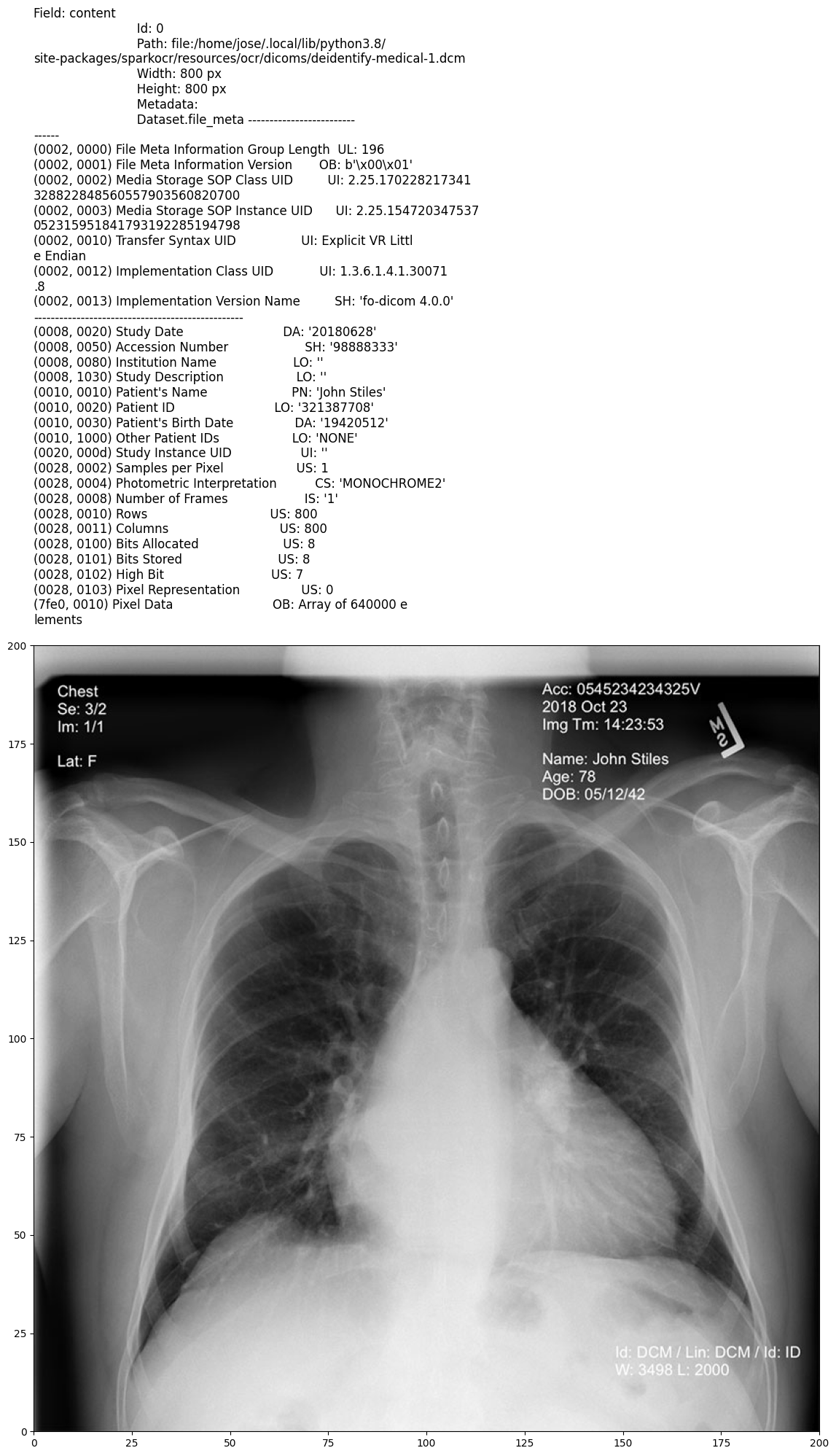
Output:
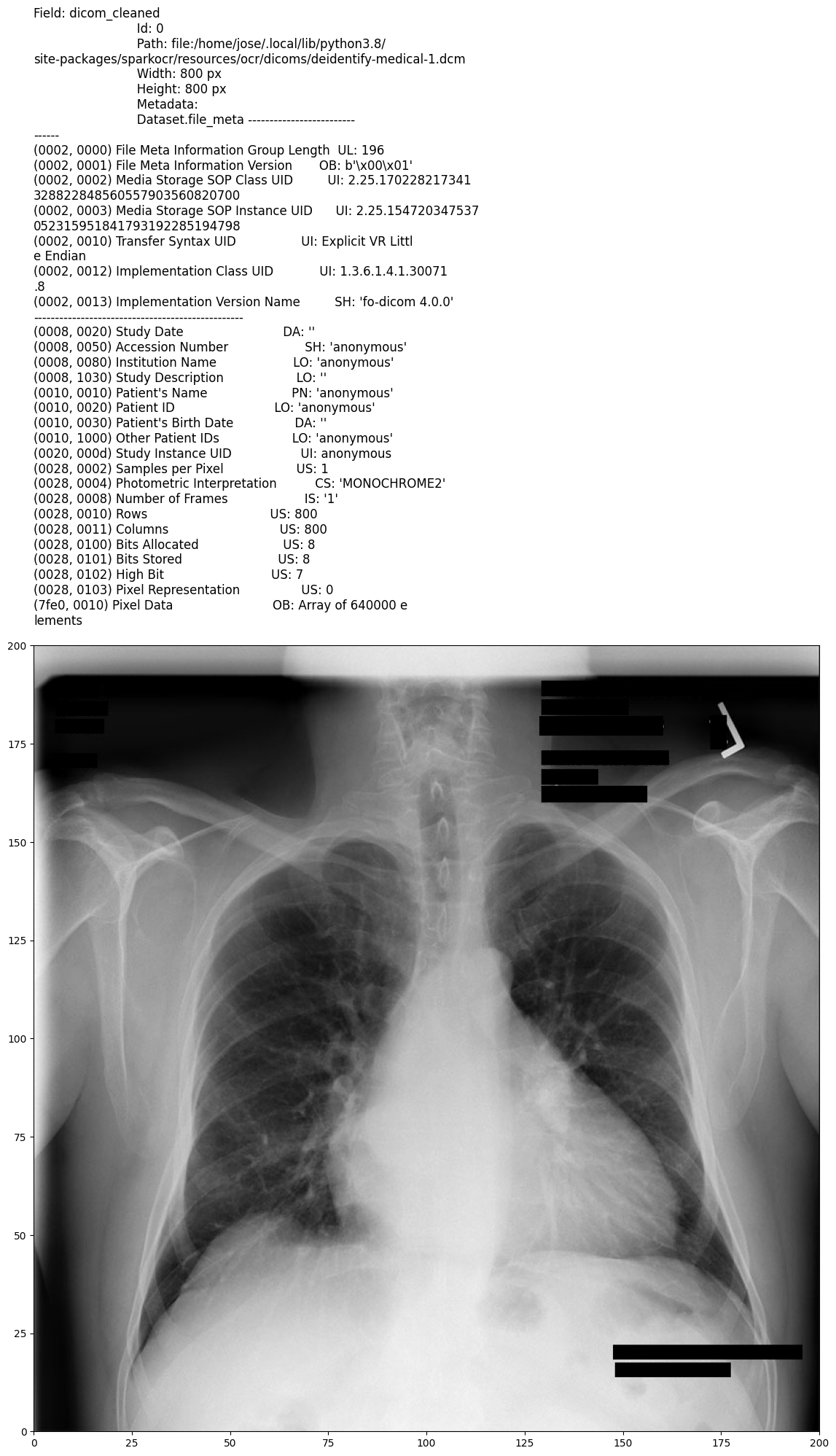
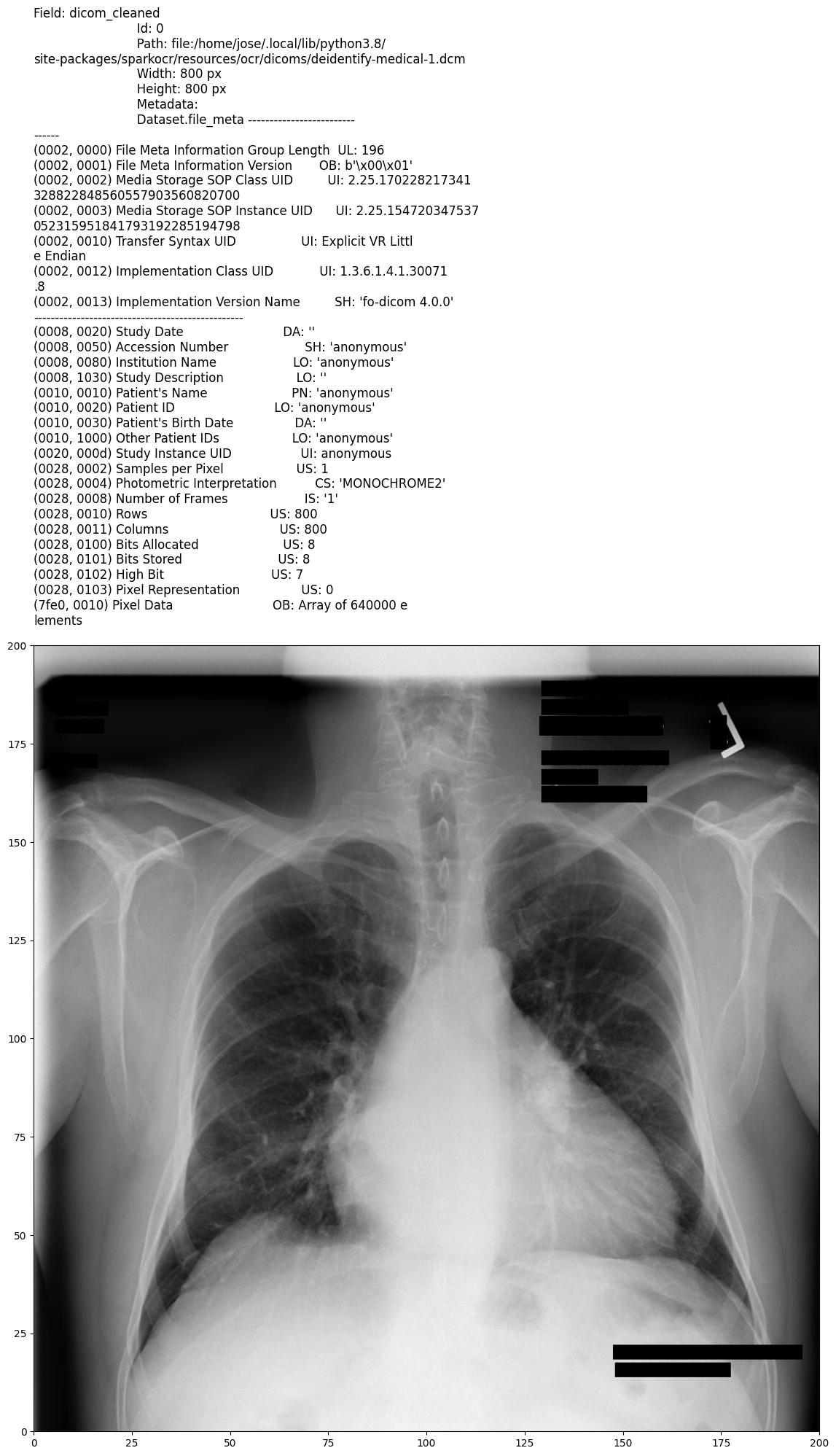
Model Information
| Model Name: | dicom_deid_full_anonymization |
| Type: | pipeline |
| Compatibility: | Visual NLP 5.5.0+ |
| License: | Licensed |
| Edition: | Official |
| Language: | en |