Description
DiT, as proposed in the paper “DiT: Self-supervised Pre-training for Document Image Transformer” authored by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei, applies the self-supervised learning objective from BEiT (BERT pre-training of Image Transformers) to a dataset comprising 42 million document images. This approach has demonstrated cutting-edge performance specifically in tasks related to document layout analysis, with a focus on the PubLayNet dataset. PubLayNet consists of over 360,000 document images constructed by automatically parsing PubMed XML files. The utilization of DiT proves highly effective in understanding and interpreting the layout structures within diverse document images.
Predicted Entities
text, title, list, table, figure.
Live Demo Open in Colab Download
How to use
binary_to_image = BinaryToImage()
binary_to_image.setImageType(ImageType.TYPE_3BYTE_BGR)
dit_layout = DocumentLayoutAnalyzerDit \
.pretrained("publaynet_dit_base_mrcnn_jsl", "en", "clinical/ocr") \
.setInputCol("image") \
.setOutputCol("regions") \
.setScoreThreshold(0.5)
draw_regions = ImageDrawRegions() \
.setInputCol("image") \
.setInputRegionsCol("regions") \
.setOutputCol("image_with_regions") \
.setRectColor(Color.green)
# OCR pipeline
pipeline = PipelineModel(stages=[
binary_to_image,
dit_layout,
draw_regions
])
imagePath = "/content/images"
image_df = spark.read.format("binaryFile").load(imagePath)
result = pipeline.transform(image_df).cache()
val binary_to_image = BinaryToImage().setImageType(ImageType.TYPE_3BYTE_BGR)
val dit_layout = ImageLayoutAnalyzerDit
.pretrained("publaynet_dit_base_mrcnn", "en", "clinical/ocr")
.setInputCol("image")
.setOutputCol("regions")
.setScoreThreshold(0.5)
val draw_regions = ImageDrawRegions()
.setInputCol("image")
.setInputRegionsCol("regions")
.setOutputCol("image_with_regions")
.setRectColor(Color.green)
# OCR pipeline
val pipeline = new PipelineModel().setStages(Array(
binary_to_image,
dit_layout,
draw_regions))
val imagePath = "/content/images"
val image_df = spark.read.format("binaryFile").load(imagePath)
val result = pipeline.transform(image_df).cache()
Example
Input:
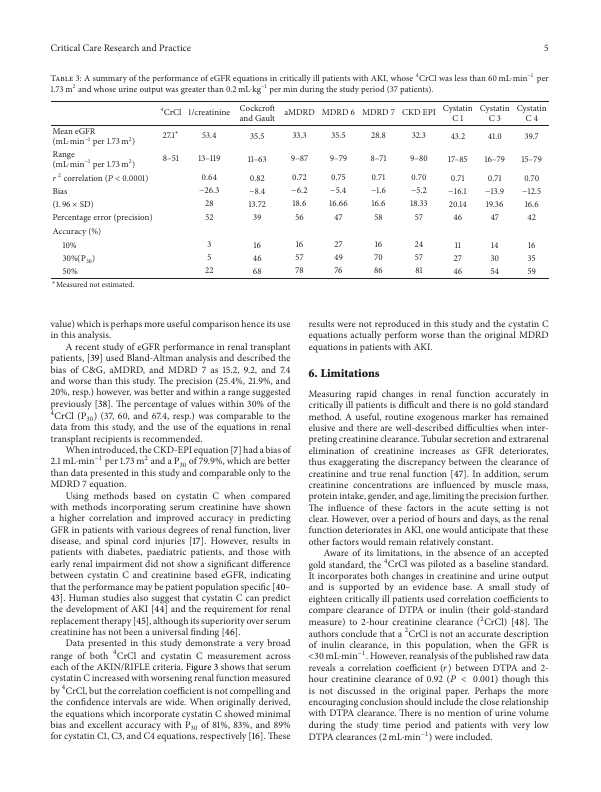
Output:
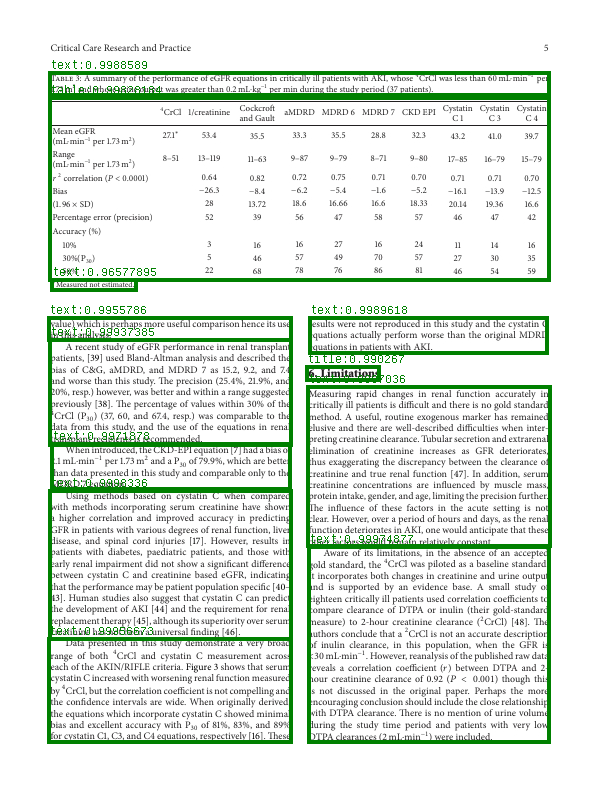
Model Information
| Model Name: | publaynet_dit_base_mrcnn |
| Type: | ocr |
| Compatibility: | Visual NLP 5.1.0+ |
| License: | Licensed |
| Edition: | Official |
| Language: | en |