Description
The LiLT model, introduced in the research paper titled “LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding” authored by Jiapeng Wang, Lianwen Jin, and Kai Ding, offers a versatile solution for structured document comprehension across multiple languages. It achieves this by seamlessly integrating any pre-trained RoBERTa text encoder with a lightweight Layout Transformer, thereby enabling LayoutLM-like document comprehension capabilities for a wide range of languages.
To prepare the LiLT model for its tasks, it underwent pretraining using the FUNSD dataset, which focuses on key-value recognition. The Form Understanding in Noisy Scanned Documents (FUNSD) dataset comprises 199 fully annotated scanned forms that reflect real-world challenges. These documents exhibit noise and exhibit significant visual diversity, making form understanding (FoUn) a complex and demanding task. The FUNSD dataset serves as a valuable resource for various tasks, including text detection, optical character recognition, spatial layout analysis, and entity labeling/linking.
In the abstract of the LiLT paper, the authors emphasize the growing importance of structured document understanding in the context of intelligent document processing. They highlight a common limitation in existing models, which are often tailored to specific languages, particularly English, based on their pretraining data. To address this limitation, LiLT is introduced as a straightforward yet effective Language-independent Layout Transformer. This model can be pretrained on structured documents from a single language and subsequently fine-tuned on other languages using readily available monolingual or multilingual pre-trained textual models. The paper reports experimental results across eight languages, demonstrating that LiLT can achieve competitive or even superior performance on various widely-used downstream benchmarks. This capability allows for language-independent benefits stemming from pretraining on document layout structure.
Predicted Entities
other, b-header, i-header, b-question, i-question, b-answer, i-answer.
Live Demo Open in Colab Download
How to use
binary_to_image = BinaryToImage()\
.setOutputCol("image") \
.setImageType(ImageType.TYPE_3BYTE_BGR)
img_to_hocr = ImageToHocr()\
.setInputCol("image")\
.setOutputCol("hocr")\
.setIgnoreResolution(False)\
.setOcrParams(["preserve_interword_spaces=0"])
tokenizer = HocrTokenizer()\
.setInputCol("hocr")\
.setOutputCol("tokens")
doc_ner = VisualDocumentNer()\
.pretrained("lilt_roberta_funsd_v1", "en", "clinical/ocr")\
.setInputCols(["tokens", "image"])\
.setOutputCol("entities")
draw = ImageDrawAnnotations() \
.setInputCol("image") \
.setInputChunksCol("entities") \
.setOutputCol("image_with_annotations") \
.setFontSize(10) \
.setLineWidth(4)\
.setRectColor(Color.red)
# OCR pipeline
pipeline = PipelineModel(stages=[
binary_to_image,
img_to_hocr,
tokenizer,
doc_ner,
draw
])
test_image_path = pkg_resources.resource_filename('sparkocr', 'resources/ocr/forms/form1.jpg')
bin_df = spark.read.format("binaryFile").load(test_image_path)
results = pipeline.transform(bin_df).cache()
val binary_to_image = new BinaryToImage()
.setOutputCol("image")
.setImageType(ImageType.TYPE_3BYTE_BGR)
val img_to_hocr = new ImageToHocr()
.setInputCol("image")
.setOutputCol("hocr")
.setIgnoreResolution(False)
.setOcrParams(Array("preserve_interword_spaces=0"))
val tokenizer = new HocrTokenizer()
.setInputCol("hocr")
.setOutputCol("tokens")
val doc_ner = VisualDocumentNer()
.pretrained("lilt_roberta_funsd_v1", "en", "clinical/ocr")
.setInputCols(Array("tokens", "image"))
.setOutputCol("entities")
val draw = new ImageDrawAnnotations()
.setInputCol("image")
.setInputChunksCol("entities")
.setOutputCol("image_with_annotations")
.setFontSize(10)
.setLineWidth(4)
.setRectColor(Color.red)
val pipeline = new PipelineModel().setStages(Array(
binary_to_image,
img_to_hocr,
tokenizer,
doc_ner,
draw))
val test_image_path = pkg_resources.resource_filename("sparkocr", "resources/ocr/forms/form1.jpg")
val bin_df = spark.read.format("binaryFile").load(test_image_path)
val results = pipeline.transform(bin_df).cache()
Example

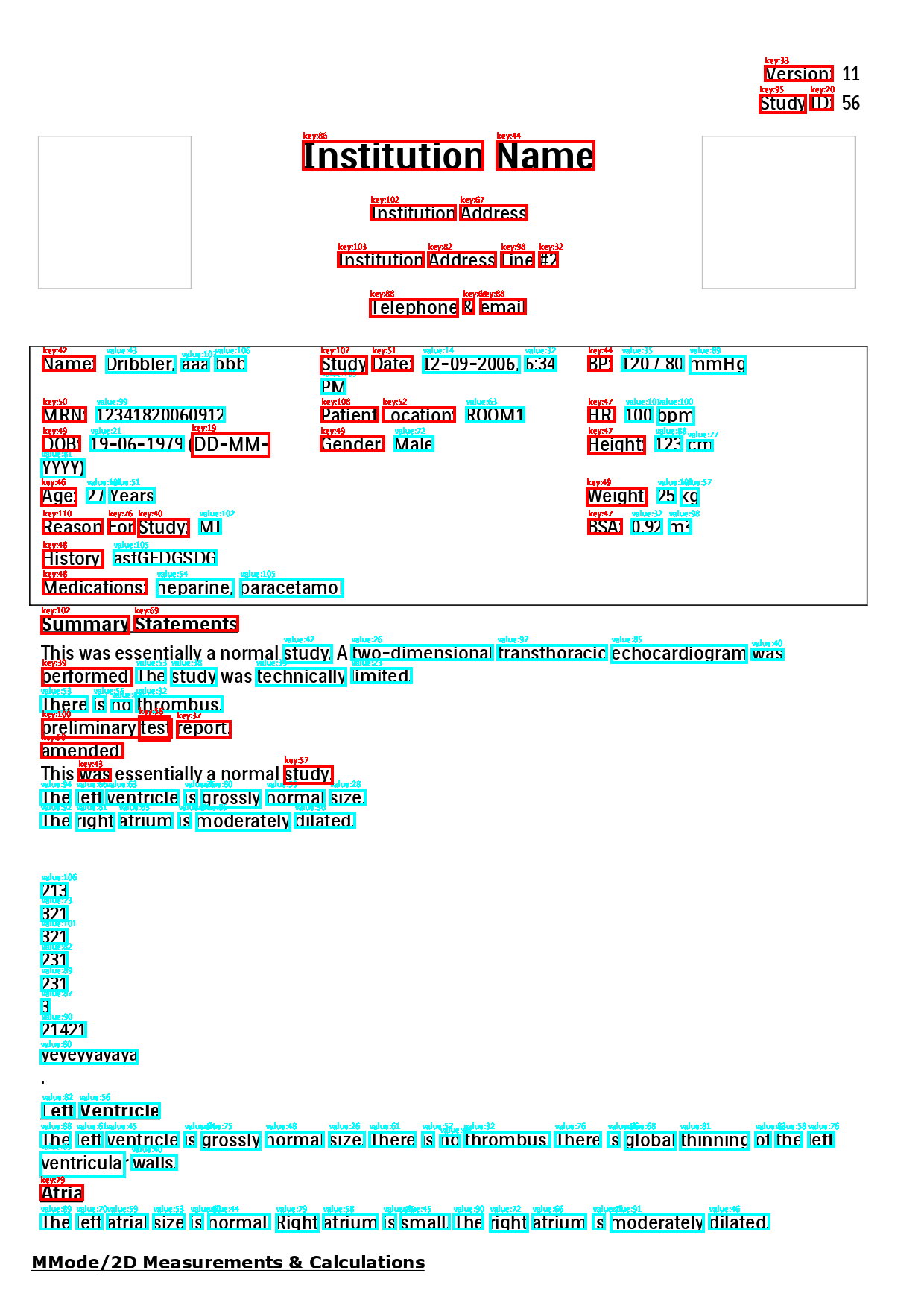
Output text
+---------+-------------------------------------------------------------------------------------------------------------------------------------------------------+
|filename |exploded_entities |
+---------+-------------------------------------------------------------------------------------------------------------------------------------------------------+
|form1.jpg|{named_entity, 0, 7, b-question, {x -> 1027, y -> 89, height -> 19, confidence -> 106, token -> version, ocr_confidence -> 96, width -> 90}, []} |
|form1.jpg|{named_entity, 7, 8, i-question, {x -> 1027, y -> 89, height -> 19, confidence -> 67, token -> :, ocr_confidence -> 96, width -> 90}, []} |
|form1.jpg|{named_entity, 10, 15, b-question, {x -> 1020, y -> 128, height -> 23, confidence -> 95, token -> study, ocr_confidence -> 96, width -> 61}, []} |
|form1.jpg|{named_entity, 15, 17, b-question, {x -> 1088, y -> 128, height -> 19, confidence -> 77, token -> id, ocr_confidence -> 96, width -> 29}, []} |
|form1.jpg|{named_entity, 17, 18, i-question, {x -> 1088, y -> 128, height -> 19, confidence -> 41, token -> :, ocr_confidence -> 96, width -> 29}, []} |
|form1.jpg|{named_entity, 20, 31, b-question, {x -> 407, y -> 190, height -> 37, confidence -> 86, token -> institution, ocr_confidence -> 95, width -> 241}, []} |
|form1.jpg|{named_entity, 31, 35, i-question, {x -> 667, y -> 190, height -> 37, confidence -> 44, token -> name, ocr_confidence -> 95, width -> 130}, []} |
|form1.jpg|{named_entity, 35, 46, b-question, {x -> 498, y -> 276, height -> 19, confidence -> 102, token -> institution, ocr_confidence -> 96, width -> 113}, []}|
|form1.jpg|{named_entity, 46, 53, b-question, {x -> 618, y -> 276, height -> 19, confidence -> 67, token -> address, ocr_confidence -> 96, width -> 89}, []} |
|form1.jpg|{named_entity, 53, 64, b-question, {x -> 454, y -> 339, height -> 19, confidence -> 103, token -> institution, ocr_confidence -> 96, width -> 114}, []}|
|form1.jpg|{named_entity, 64, 71, b-question, {x -> 575, y -> 339, height -> 19, confidence -> 82, token -> address, ocr_confidence -> 96, width -> 90}, []} |
|form1.jpg|{named_entity, 71, 75, b-question, {x -> 673, y -> 339, height -> 19, confidence -> 98, token -> line, ocr_confidence -> 96, width -> 43}, []} |
|form1.jpg|{named_entity, 75, 76, i-question, {x -> 724, y -> 339, height -> 19, confidence -> 72, token -> #, ocr_confidence -> 96, width -> 24}, []} |
|form1.jpg|{named_entity, 76, 77, i-question, {x -> 724, y -> 339, height -> 19, confidence -> 65, token -> 2, ocr_confidence -> 96, width -> 24}, []} |
|form1.jpg|{named_entity, 77, 86, b-question, {x -> 497, y -> 402, height -> 23, confidence -> 88, token -> telephone, ocr_confidence -> 91, width -> 117}, []} |
|form1.jpg|{named_entity, 86, 87, b-question, {x -> 622, y -> 402, height -> 19, confidence -> 64, token -> &, ocr_confidence -> 91, width -> 14}, []} |
|form1.jpg|{named_entity, 87, 92, b-question, {x -> 645, y -> 402, height -> 19, confidence -> 88, token -> email, ocr_confidence -> 95, width -> 60}, []} |
|form1.jpg|{named_entity, 92, 96, b-question, {x -> 58, y -> 478, height -> 19, confidence -> 108, token -> name, ocr_confidence -> 92, width -> 69}, []} |
|form1.jpg|{named_entity, 96, 97, i-question, {x -> 58, y -> 478, height -> 19, confidence -> 84, token -> :, ocr_confidence -> 92, width -> 69}, []} |
|form1.jpg|{named_entity, 97, 101, b-answer, {x -> 143, y -> 478, height -> 22, confidence -> 108, token -> dribbler, ocr_confidence -> 91, width -> 92}, []} |
+---------+-------------------------------------------------------------------------------------------------------------------------------------------------------+
only showing top 20 rows
Model Information
| Model Name: | lilt_roberta_funsd_v1 |
| Type: | ocr |
| Compatibility: | Visual NLP 4.0.0+ |
| License: | Licensed |
| Edition: | Official |
| Language: | en |
References
FUNSD