This is a ready to use NLP Server for analyzing text documents using NLU library. Over 4500+ industry grade NLP Models in 300+ Languages are available to use via a simple and intuitive UI, without writing a line of code. For more expert users and more complex tasks, NLP Server also provides a REST API that can be used to process high amounts of data.
The models, refered to as spells, are provided by the NLU library and
powered by the most widely used NLP library in the industry, Spark NLP.
NLP Server is free for everyone to download and use. There is no limitation in the amount of text to analyze.
You can setup NLP-Server as a Docker Machine in any enviroment or get it via the AWS Marketplace in just 1 click.
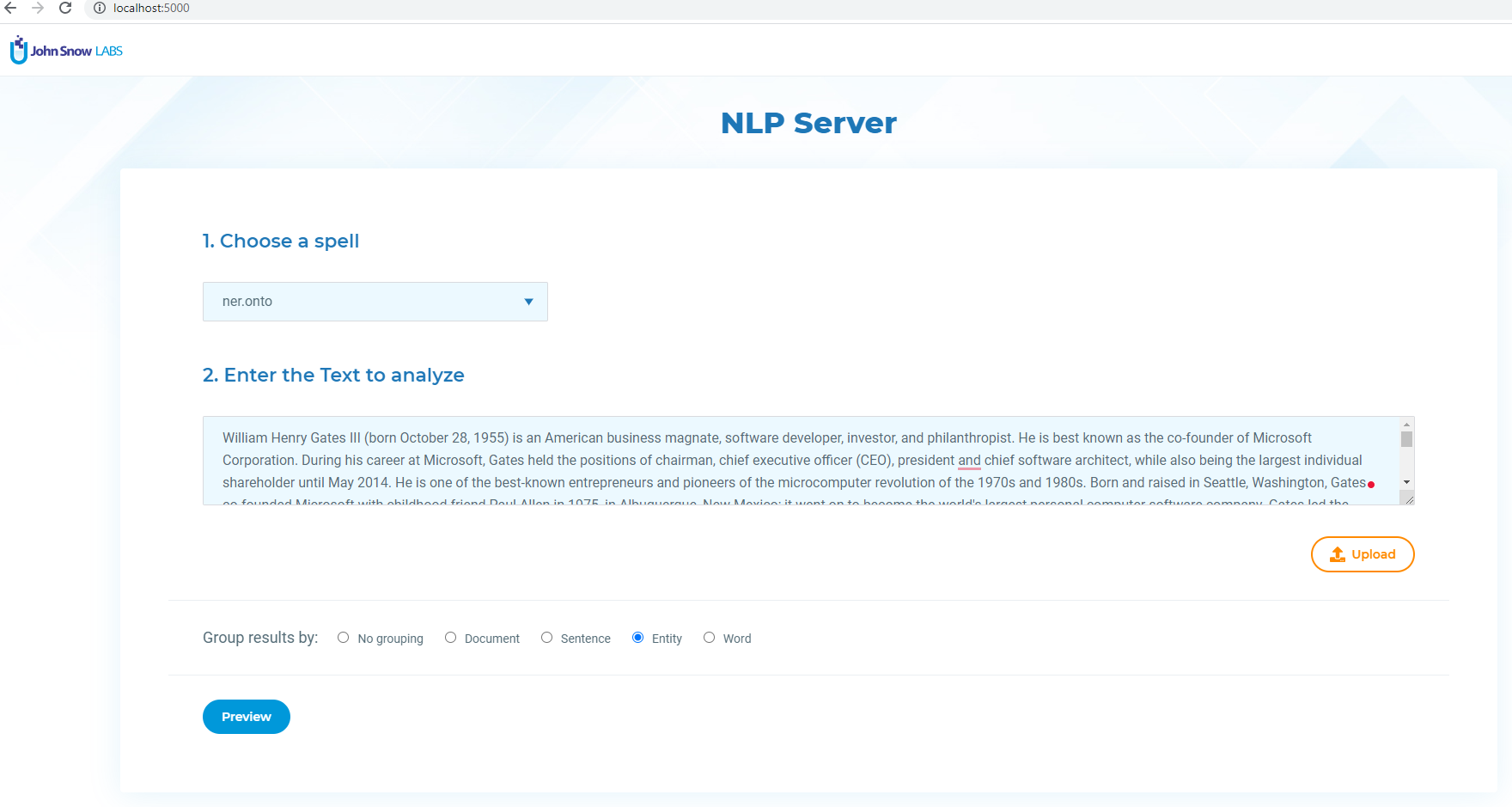
Web UI
The Web UI is accessible at the following URL: http://localhost:5000/
It allows a very simple and intuitive interaction with the NLP Server.
As a first step the user chooses the spell from the first dropdown. All NLU spells are available.
Then the user has to provide a text document for analysis. This can be done by either copy/pasting text on the text box, or by uploading a csv/json file.
After selecting the grouping option, the user clicks on the Preview button to get the results for the first 10 rows of text.
REST API
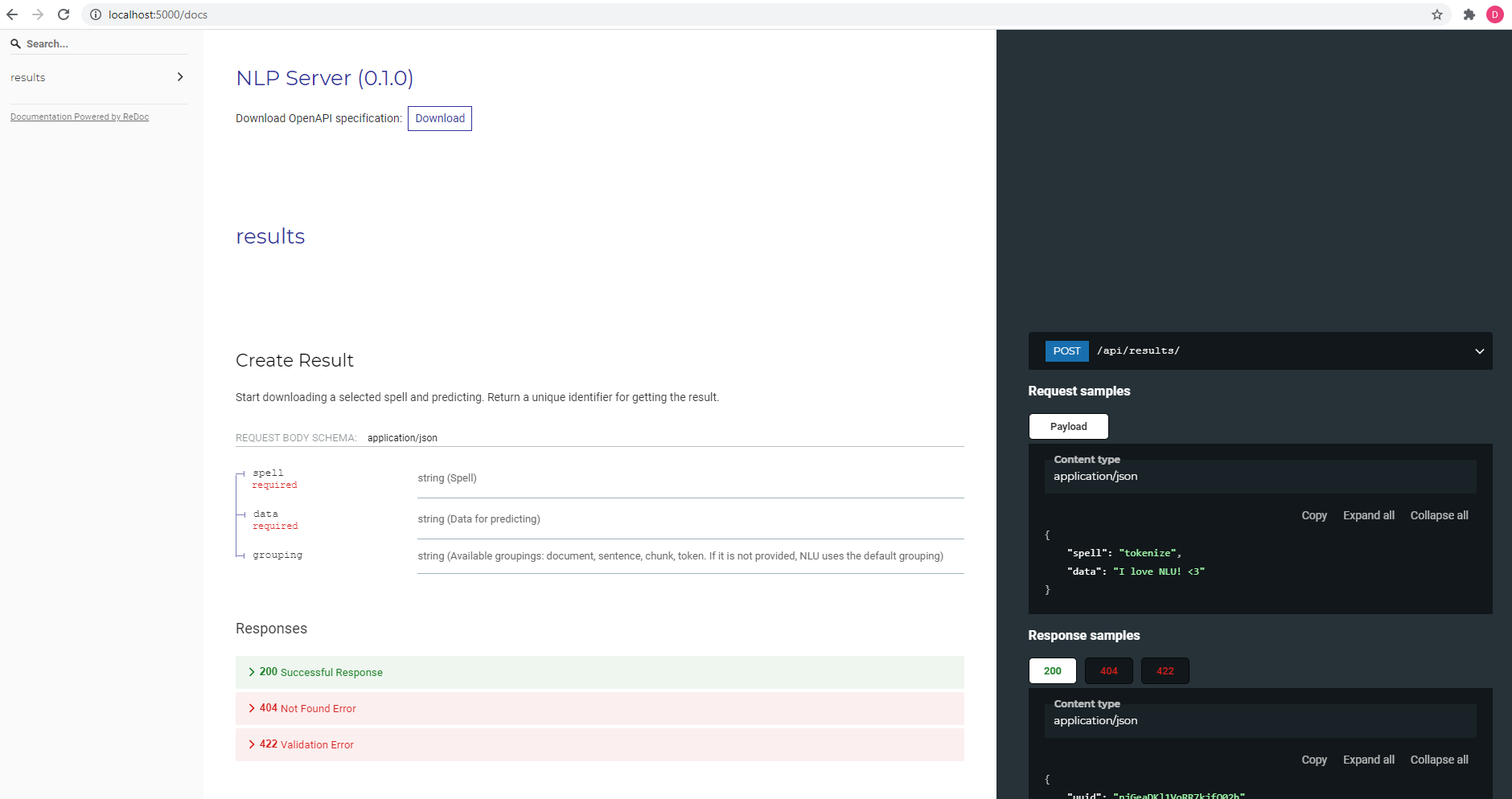
NLP Server includes a REST API which can be used to process any amount of data using NLU. Once you deploy the NLP Server, you can access the API documentation at the following URL http://localhost:5000/docs.
Integrate via the Rest API
Rest APIs are a popular way to integrate different services into one common platform. NLP Server offers its own API to offer a quick programmatic integration with customers’ services and applications. Bellow is a quick overview of the provided endpoints. More details are provided in the API documentation available http://localhost:5000/docs.
- Start to analyze
- Endpoint : /results
- Method : POST
- Content-Type (Format) : multipart/form-data
- Parameters:
- Spell – the spell that you want to use for this analyze (if you want to run multiple spells you should join them with space character)
- Data – The data to analyse that can be a single text or an array of strings or files.
- Grouping – can be choosen from [“document”, “sentence”, “entity”, “word”]. The default value is “” for automatic selection based on spell.
- Format – The format of the provided input. The default value is “text”.
- Response:
- uuid – the unique identifier for the analysis process.
- Check the status of an analysis process
- Endpoint : /results/{uuid}/status
- Method : GET
- Content-Type (Format) : application/json
- Response:
- code – the status code that can be one of “progress”, “success”, “failure”, “broken spell”, “invalid license”, “licensed spell with no license”
- message – the status message
- Get the results
After ensuring the status of an analysis is “success” you can get the results:
- Endpoint : /results/{uuid}
- Method : GET
- Content-Type (Format) : application/json
- Parameters:
- target – if the specified target is “preview” you only get a small part of results.
- Response:
- A JSON object that contains the results generated by the spell (each spell has their own specific keys)
How to use in Python
import requests
# Invoke Processing with tokenization spell
r = requests.post(f'http://localhost:5000/api/results',json={"spell": "tokenize","data": "I love NLU! <3"})
# Use the uuid to get your processed data
uuid = r.json()['uuid']
# Get status of processing
r = requests.get(f'http://localhost:5000/api/results/{uuid}/status').json
>>> {'status': {'code': 'success', 'message': None}}
# Get results
r = requests.get(f'http://localhost:5000/api/results/{uuid}').json()
>>> {'sentence': {'0': ['I love NLU! <3']}, 'document': {'0': 'I love NLU! <3'}, 'token': {'0': ['I', 'love', 'NLU', '!', '<3']}}
Import a license key
Thanks to the close integration between NLP Server and https://my.JohnSnowLabs.com website, users can easily select and import one of the available licenses to be used on NLP Server. The steps to execute for this are:
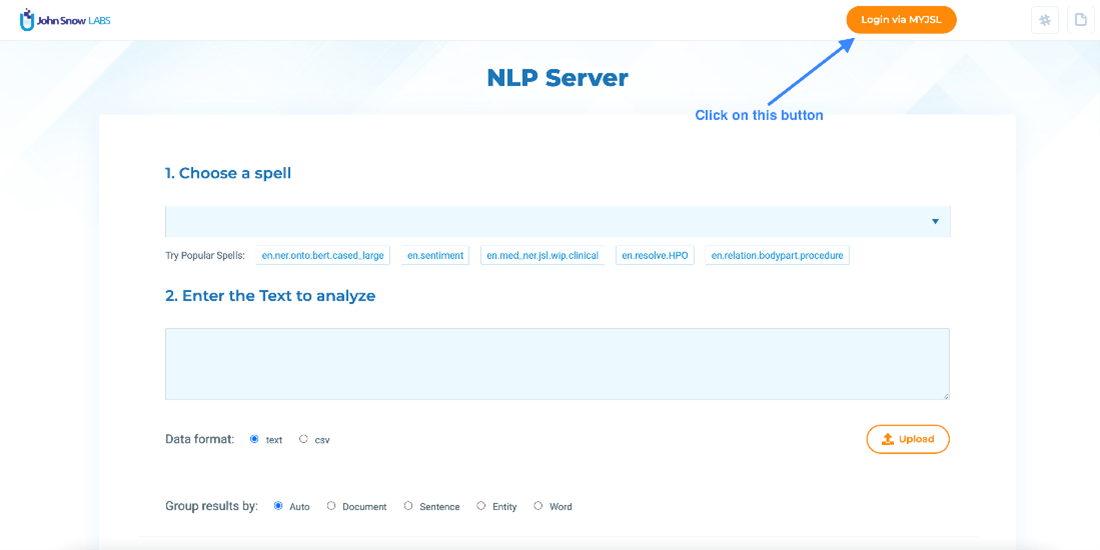
1.Click on Login via MYJSL button on the menu bar.
2.In the pop-up window click on the Authorize button.

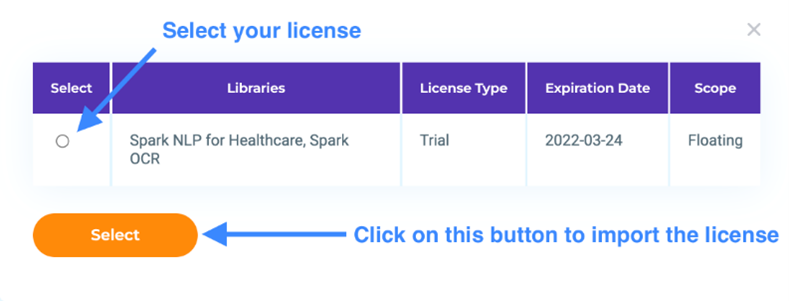
3.After redirecting back to NLP Server click on the Choose License button.

4.In the modal choose the license that you want to use and then click on the Select button.
5.After the above steps you will see this success alert on the top right of the page. That confirms the import of license completed successfully.
