Description
Table structure recognition based on hocr with Tesseract architecture.
Tesseract has been trained on a variety of datasets to improve its recognition capabilities. These datasets include images of text in various languages and scripts, as well as images with different font styles, sizes, and orientations. The training process involves feeding the engine with a large number of images and their corresponding text, allowing the engine to learn the patterns and characteristics of different text styles. One of the most important datasets used in training Tesseract is the UNLV dataset, which contains over 400,000 images of text in different languages, scripts, and font styles. This dataset is widely used in the OCR community and has been instrumental in improving the accuracy of Tesseract. Other datasets that have been used in training Tesseract include the ICDAR dataset, the IIIT-HWS dataset, and the RRC-GV-WS dataset.
In addition to these datasets, Tesseract also uses a technique called adaptive training, where the engine can continuously improve its recognition capabilities by learning from new images and text. This allows Tesseract to adapt to new text styles and languages, and improve its overall accuracy.
Predicted Entities
How to use
binary_to_image = BinaryToImage() \
.setInputCol("content") \
.setOutputCol("image")
table_detector = ImageTableDetector.pretrained("general_model_table_detection_v2", "en", "clinical/ocr") \
.setInputCol("image") \
.setOutputCol("table_regions")
splitter = ImageSplitRegions() \
.setInputCol("image") \
.setInputRegionsCol("table_regions") \
.setOutputCol("table_image") \
.setDropCols("image") \
.setImageType(ImageType.TYPE_BYTE_GRAY) \
.setExplodeCols([])
text_detector = ImageTextDetectorV2.pretrained("image_text_detector_v2", "en", "clinical/ocr") \
.setInputCol("image") \
.setOutputCol("text_regions") \
.setWithRefiner(True)
draw_regions = ImageDrawRegions() \
.setInputCol("image") \
.setInputRegionsCol("text_regions") \
.setOutputCol("image_with_regions") \
.setRectColor(Color.green) \
.setRotated(True)
img_to_hocr = ImageToTextV2().pretrained("ocr_small_printed", "en", "clinical/ocr") \
.setInputCols(["image", "text_regions"]) \
.setUsePandasUdf(False) \
.setOutputFormat(OcrOutputFormat.HOCR) \
.setOutputCol("hocr") \
.setGroupImages(False)
hocr_to_table = HocrToTextTable() \
.setInputCol("hocr") \
.setRegionCol("table_regions") \
.setOutputCol("tables")
pipeline = PipelineModel(stages=[
binary_to_image,
table_detector,
splitter,
text_detector,
draw_regions,
img_to_hocr,
hocr_to_table
])
imagePath = "data/tab_images_hocr_1/table4_1.jpg"
image_df= spark.read.format("binaryFile").load(imagePath)
result = pipeline.transform(image_df).cache()
val binary_to_image = new BinaryToImage()
.setInputCol("content")
.setOutputCol("image")
val table_detector = new ImageTableDetector
.pretrained("general_model_table_detection_v2", "en", "clinical/ocr")
.setInputCol("image")
.setOutputCol("table_regions")
val splitter = new ImageSplitRegions()
.setInputCol("image")
.setInputRegionsCol("table_regions")
.setOutputCol("table_image")
.setDropCols("image")
.setImageType(ImageType.TYPE_BYTE_GRAY)
.setExplodeCols(Array())
val text_detector = new ImageTextDetectorV2
.pretrained("image_text_detector_v2", "en", "clinical/ocr")
.setInputCol("image")
.setOutputCol("text_regions")
.setWithRefiner(True)
val draw_regions = new ImageDrawRegions()
.setInputCol("image")
.setInputRegionsCol("text_regions")
.setOutputCol("image_with_regions")
.setRectColor(Color.green)
.setRotated(True)
img_to_hocr = ImageToTextV2()
.pretrained("ocr_small_printed", "en", "clinical/ocr")
.setInputCols(Array("image", "text_regions"))
.setUsePandasUdf(False)
.setOutputFormat(OcrOutputFormat.HOCR)
.setOutputCol("hocr")
.setGroupImages(False)
val hocr_to_table = new HocrToTextTable()
.setInputCol("hocr")
.setRegionCol("table_regions")
.setOutputCol("tables")
val pipeline = new PipelineModel().setStages(Array(
binary_to_image,
table_detector,
splitter,
text_detector,
draw_regions,
img_to_hocr,
hocr_to_table))
val imagePath = "data/tab_images_hocr_1/table4_1.jpg"
val image_df= spark.read.format("binaryFile").load(imagePath)
val result = pipeline.transform(image_df).cache()
Example
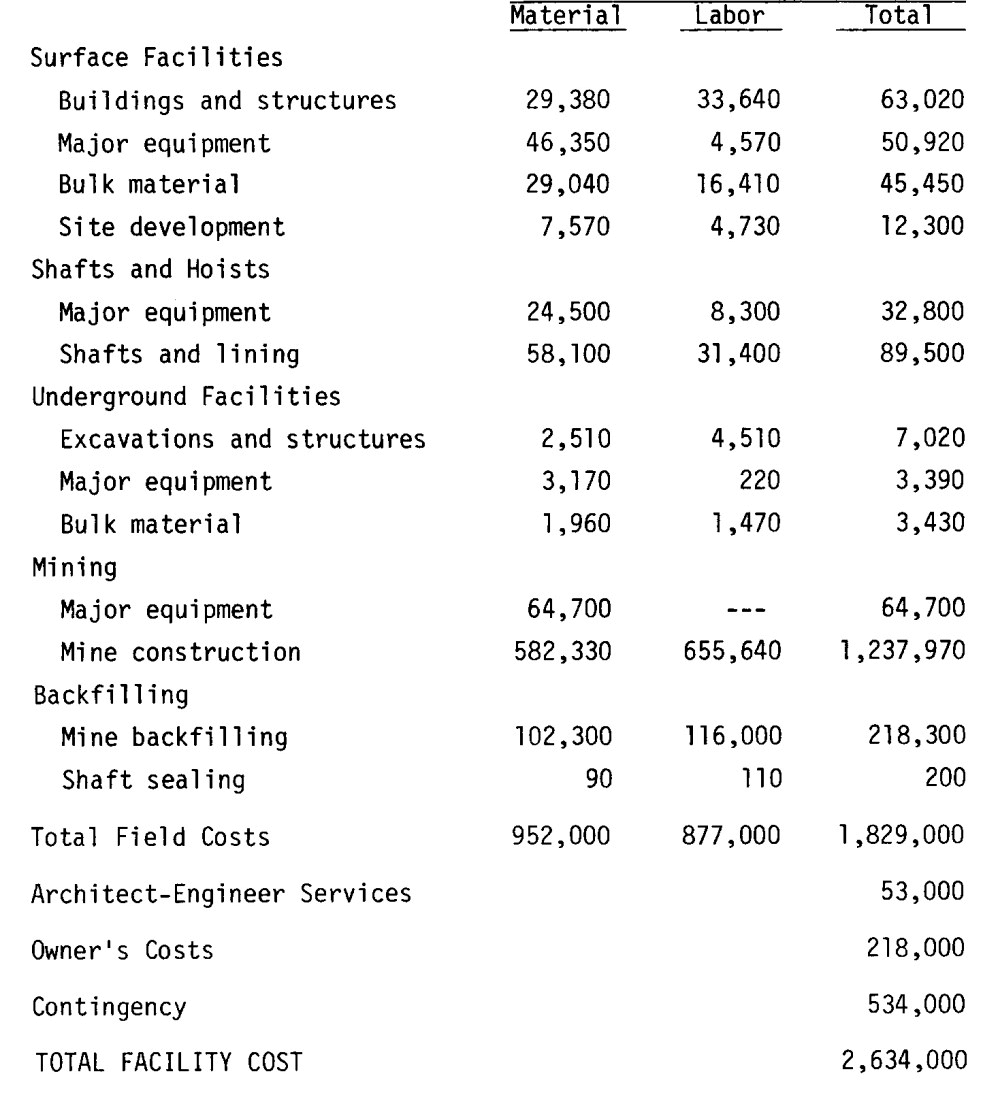

Output text
text_regions table_image pagenum modificationTime path table_regions length image image_with_regions hocr tables exception table_index
[{0, 0, 566.32025... {file:/content/ta... 0 2023-01-23 08:21:... file:/content/tab... {0, 0, 40.0, 0.0,... 172124 {file:/content/ta... {file:/content/ta... <?xml version="1.... {0, 0, 0.0, 0.0,... null 0
Filename: table4_1.jpg
Page: 0
Table: 0
4
col0 col1 col2 col3
0 MATERIAL LABOR TOTAL
1 SURFACE FACILITIES None None None
2 BUILDINGS AND STRUCTURES 29,380 33,640 63,020
3 MAJOR EQUIPMENT 46,350 4,570 50,920
4 BULK MATERIAL 29,040 16,410 45,450
5 SITE DEVELOPMENT 7,570 4,730 12,300
6 SHAFTS AND HOISTS None None None
7 MAJOR EQUIPMENT 24,500 8,300 32,800
8 SHAFTS AND LINING 58,100 31,400 89,500
9 UNDERGROUND FACILITIES None None None
10 EXCAVATIONS AND STRUCTURES 2,510 4,510 7,020
11 MAJOR EQUIPMENT 3,170 220 3,390
12 BULK MATERIAL 1,960 1,470 3,430
13 MINING None None None
14 MAJOR EQUIPMENT 64,700 64,700
15 MINE CONSTRUCTION 582,330 655,640 1,237,970
16 BACKFULLING None None None
17 MINE BACKFILLING 102,300 116,000 218,300
18 SHAFT SEALING 90 710 200
19 TOTAL FIELD COSTS 952.000 877.000 1,829,000
20 ARCHITECT-ENGINEER SERVICES 53,000
21 OWNER'S COSTS 218,000
22 CONTINGENCY 534.0001
Model Information
| Model Name: | hocr_table_recognition |
| Type: | ocr |
| Compatibility: | Visual NLP 4.2.4+ |
| License: | Licensed |
| Edition: | Official |
| Language: | en |