Description
Ocr small model for recognise printed text based on TrOcr architecture. The TrOCR model was proposed in TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei. TrOCR consists of an image Transformer encoder and an autoregressive text Transformer decoder to perform optical character recognition (OCR). The abstract from the paper is the following: Text recognition is a long-standing research problem for document digitalization. Existing approaches for text recognition are usually built based on CNN for image understanding and RNN for char-level text generation. In addition, another language model is usually needed to improve the overall accuracy as a post-processing step. In this paper, we propose an end-to-end text recognition approach with pre-trained image Transformer and text Transformer models, namely TrOCR, which leverages the Transformer architecture for both image understanding and wordpiece-level text generation. The TrOCR model is simple but effective, and can be pre-trained with large-scale synthetic data and fine-tuned with human-labeled datasets. Experiments show that the TrOCR model outperforms the current state-of-the-art models on both printed and handwritten text recognition tasks.
Predicted Entities
Live Demo Open in Colab Copy S3 URI
How to use
binary_to_image = BinaryToImage() \
.setInputCol("content") \
.setOutputCol("image") \
.setImageType(ImageType.TYPE_3BYTE_BGR)
text_detector = ImageTextDetectorV2 \
.pretrained("image_text_detector_v2", "en", "clinical/ocr") \
.setInputCol("image") \
.setOutputCol("text_regions") \
.setWithRefiner(False) \
.setSizeThreshold(15) \
.setLinkThreshold(0.3)
draw_regions = ImageDrawRegions() \
.setInputCol("image") \
.setInputRegionsCol("text_regions") \
.setOutputCol("image_with_regions") \
.setRectColor(Color.green) \
.setRotated(True)
ocr = ImageToTextV2.pretrained("ocr_small_printed", "en", "clinical/ocr") \
.setInputCols(["image", "text_regions"]) \
.setOutputCol("hocr") \
.setOutputFormat(OcrOutputFormat.HOCR) \
.setGroupImages(False)
pipeline = PipelineModel(stages=[
binary_to_image,
text_detector,
draw_regions,
ocr
])
image_path = pkg_resources.resource_filename('sparkocr', 'resources/ocr/images/check.jpg')
image_example_df = spark.read.format("binaryFile").load(image_path)
result = pipeline.transform(image_example_df).cache()
val binary_to_image = new BinaryToImage()
.setInputCol("content")
.setOutputCol("image")
.setImageType(ImageType.TYPE_3BYTE_BGR)
val text_detector = ImageTextDetectorV2.pretrained("image_text_detector_v2", "en", "clinical/ocr")
.setInputCol("image")
.setOutputCol("text_regions")
.setWithRefiner(False)
.setSizeThreshold(15)
.setLinkThreshold(0.3)
val draw_regions = ImageDrawRegions()
.setInputCol("image")
.setInputRegionsCol("text_regions")
.setOutputCol("image_with_regions")
.setRectColor(Color.green)
.setRotated(True)
val ocr = ImageToTextV2.pretrained("ocr_small_printed", "en", "clinical/ocr")
.setInputCols("image", "text_regions")
.setOutputCol("hocr")
.setOutputFormat(OcrOutputFormat.HOCR)
.setGroupImages(False)
val pipeline = new PipelineModel().setStages(Array(
binary_to_image,
text_detector,
draw_regions,
ocr))
val image_path = pkg_resources.resource_filename("sparkocr", "resources/ocr/images/check.jpg"")
val image_example_df = spark.read.format("binaryFile").load(image_path)
val result = pipeline.transform(image_example_df).cache()
Example

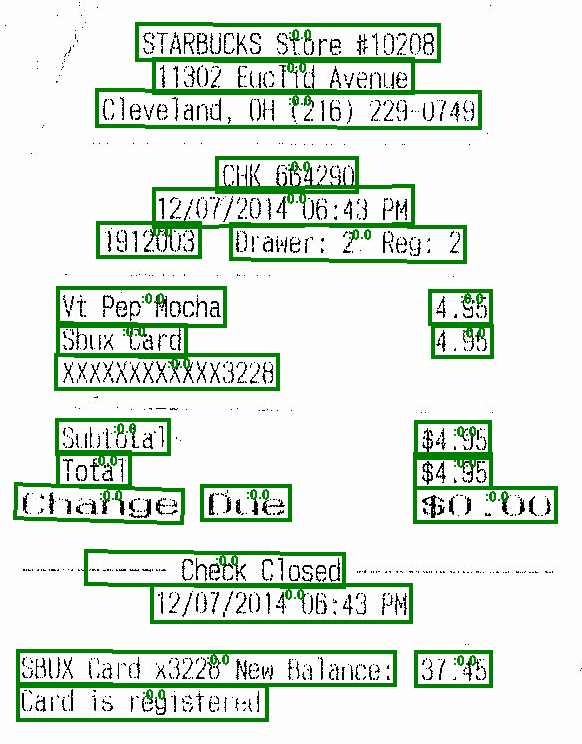
Output text
STARBUCKS STORE #10208
11302 EUCLID AVENUE
CLEVELAND OH (216) 229-0749
CHK 664290
12/07/2014 06:43 PM
1912003 DRAMER: 2 REG: 2
VT PEP MOCHA 4.95
SBUX CARD 4.95
XXXXXXXXXXXX3228
SUBTOTAL $4.95
TOTAL $4.95
CHANGE DUE $0.00
CHECK CLOSED
12/07/2014 06:43 PM
SBUX CARD X3228 NEW BALANCE: 37.45
CARD IS REGISTERED
Model Information
| Model Name: | ocr_small_printed |
| Type: | ocr |
| Compatibility: | Visual NLP 3.3.3+ |
| License: | Licensed |
| Edition: | Official |
| Language: | en |