ImageHandwrittenDetector
ImageHandwrittenDetector is a DL model for detect handwritten text on the image.
It’s based on Cascade Region-based CNN network.
Detector support following labels:
- ‘signature’
- ‘date’
- ‘name’
- ‘title’
- ‘address’
- ‘others’
Input Columns
| Param name | Type | Default | Column Data Description |
|---|---|---|---|
| inputCol | string | image | image struct (Image schema) |
Parameters
| Param name | Type | Default | Description |
|---|---|---|---|
| scoreThreshold | float | 0.5 | Score threshold for output regions. |
| outputLabels | Array[String] | White list for output labels. | |
| labels | Array[String] | List of labels |
Output Columns
| Param name | Type | Default | Column Data Description |
|---|---|---|---|
| outputCol | string | table_regions | array of [Coordinaties]ocr_structures#coordinate-schema) |
Example:
from pyspark.ml import PipelineModel
from sparkocr.transformers import *
imagePath = "path to image"
# Read image file as binary file
df = spark.read
.format("binaryFile")
.load(imagePath)
binary_to_image = BinaryToImage() \
.setInputCol("content") \
.setOutputCol("image")
# Define transformer for detect signature
signature_detector = ImageHandwrittenDetector \
.pretrained("image_signature_detector_gsa0628", "en", "public/ocr/models") \
.setInputCol("image") \
.setOutputCol("signature_regions")
draw_regions = ImageDrawRegions() \
.setInputCol("image") \
.setInputRegionsCol("signature_regions") \
.setOutputCol("image_with_regions")
pipeline = PipelineModel(stages=[
binary_to_image,
signature_detector,
draw_regions
])
data = pipeline.transform(df)
display_images(data, "image_with_regions")
import com.johnsnowlabs.ocr.transformers.*
import com.johnsnowlabs.ocr.OcrContext.implicits._
val imagePath = "path to image"
// Read image file as binary file
val df = spark.read
.format("binaryFile")
.load(imagePath)
.asImage("image")
// Define transformer for detect signature
val signature_detector = ImageHandwrittenDetector
.pretrained("image_signature_detector_gsa0628", "en", "public/ocr/models")
.setInputCol("image")
.setOutputCol("signature_regions")
val draw_regions = new ImageDrawRegions()
.setInputCol("image")
.setInputRegionsCol("signature_regions")
.setOutputCol("image_with_regions")
pipeline = PipelineModel(stages=[
binary_to_image,
signature_detector,
draw_regions
])
val data = pipeline.transform(df)
data.storeImage("image_with_regions")
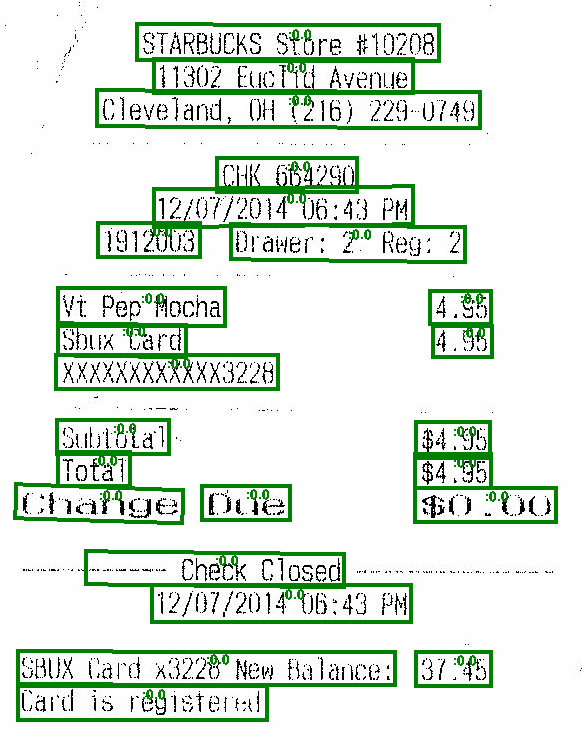
Output:

ImageTextDetector
ImageTextDetector is a DL model for detecting text on the image.
It’s based on CRAFT network architecture.
Input Columns
| Param name | Type | Default | Column Data Description |
|---|---|---|---|
| inputCol | string | image | image struct (Image schema) |
Parameters
| Param name | Type | Default | Description |
|---|---|---|---|
| scoreThreshold | float | 0.9 | Score threshold for output regions. Regions with an area below the threshold won’t be returned. |
| sizeThreshold | int | 5 | Threshold for the area of the detected regions. |
| textThreshold | float | 0.4f | Threshold for the score of a region potentially containing text. The region score represents the probability that a given pixel is the center of the character. Higher values for this threshold will result in that only regions for which the confidence of containing text is high will be returned. |
| linkThreshold | float | 0.4f | Threshold for the the link(affinity) score. The link score represents the space allowed between adjacent characters to be considered as a single word. |
| width | integer | 0 | Scale width to this value, if 0 use original width |
| height | integer | 0 | Scale height to this value, if 0 use original height |
Output Columns
| Param name | Type | Default | Column Data Description |
|---|---|---|---|
| outputCol | string | table_regions | array of [Coordinaties]ocr_structures#coordinate-schema) |
Example:
from pyspark.ml import PipelineModel
from sparkocr.transformers import *
imagePath = "path to image"
# Read image file as binary file
df = spark.read
.format("binaryFile")
.load(imagePath)
binary_to_image = BinaryToImage() \
.setInputCol("content") \
.setOutputCol("image")
# Define transformer for detect text
text_detector = ImageTextDetector \
.pretrained("text_detection_v1", "en", "clinical/ocr") \
.setInputCol("image") \
.setOutputCol("text_regions") \
.setSizeThreshold(10) \
.setScoreThreshold(0.9) \
.setLinkThreshold(0.4) \
.setTextThreshold(0.2) \
.setWidth(1512) \
.setHeight(2016)
draw_regions = ImageDrawRegions() \
.setInputCol("image") \
.setInputRegionsCol("text_regions") \
.setOutputCol("image_with_regions")
pipeline = PipelineModel(stages=[
binary_to_image,
text_detector,
draw_regions
])
data = pipeline.transform(df)
display_images(data, "image_with_regions")
import com.johnsnowlabs.ocr.transformers.*
import com.johnsnowlabs.ocr.OcrContext.implicits._
val imagePath = "path to image"
// Read image file as binary file
val df = spark.read
.format("binaryFile")
.load(imagePath)
.asImage("image")
// Define transformer for detect text
val text_detector = ImageTextDetector
.pretrained("text_detection_v1", "en", "clinical/ocr")
.setInputCol("image")
.setOutputCol("text_regions")
val draw_regions = new ImageTextDetector()
.setInputCol("image")
.setInputRegionsCol("text_regions")
.setOutputCol("image_with_regions")
.setSizeThreshold(10)
.setScoreThreshold(0.9)
.setLinkThreshold(0.4)
.setTextThreshold(0.2)
.setWidth(1512)
.setHeight(2016)
pipeline = PipelineModel(stages=[
binary_to_image,
text_detector,
draw_regions
])
val data = pipeline.transform(df)
data.storeImage("image_with_regions")
Output:

ImageTextDetectorV2
ImageTextDetectorV2 is a DL model for detecting text on images.
It is based on the CRAFT network architecture with refiner net. Refiner net
runs as postprocessing, and is able to merge single words regions into lines.
Currently, it’s available only on Python side.
Input Columns
| Param name | Type | Default | Column Data Description |
|---|---|---|---|
| inputCol | string | image | image struct (Image schema) |
Parameters
| Param name | Type | Default | Description |
|---|---|---|---|
| scoreThreshold | float | 0.7 | Score threshold for output regions. |
| sizeThreshold | int | 10 | Threshold for height of the detected regions. Regions with a height below the threshold won’t be returned. |
| textThreshold | float | 0.4f | Threshold for the score of a region potentially containing text. The region score represents the probability that a given pixel is the center of the character. Higher values for this threshold will result in that only regions for which the confidence of containing text is high will be returned. |
| linkThreshold | float | 0.4f | Threshold for the the link(affinity) score. The link score represents the space allowed between adjacent characters to be considered as a single word. |
| width | integer | 1280 | Width of the desired input image. Image will be resized to this width. |
| withRefiner | boolean | false | Enable to run refiner net as postprocessing step. |
Output Columns
| Param name | Type | Default | Column Data Description |
|---|---|---|---|
| outputCol | string | table_regions | array of [Coordinaties]ocr_structures#coordinate-schema) |
Example:
from pyspark.ml import PipelineModel
from sparkocr.transformers import *
imagePath = "path to image"
# Read image file as binary file
df = spark.read
.format("binaryFile")
.load(imagePath)
binary_to_image = BinaryToImage() \
.setInputCol("content") \
.setOutputCol("image")
# Define transformer for detect text
text_detector = ImageTextDetectorV2 \
.pretrained("image_text_detector_v2", "en", "clinical/ocr") \
.setInputCol("image") \
.setOutputCol("text_regions") \
.setScoreThreshold(0.5) \
.setTextThreshold(0.2) \
.setSizeThreshold(10) \
.setWithRefiner(True)
draw_regions = ImageDrawRegions() \
.setInputCol("image") \
.setInputRegionsCol("text_regions") \
.setOutputCol("image_with_regions")
pipeline = PipelineModel(stages=[
binary_to_image,
text_detector,
draw_regions
])
data = pipeline.transform(df)
display_images(data, "image_with_regions")
not implemented